







1.论文介绍
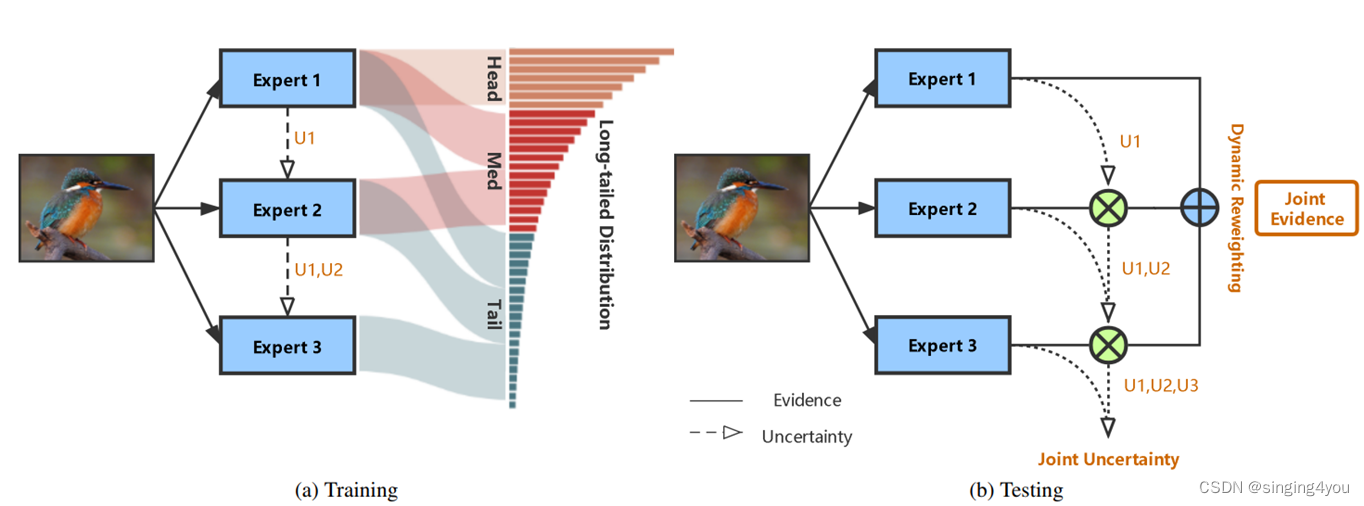
TLC的全称为<<Trustworthy Long-Tailed Classification>>,论文最大创新点是在长尾数据分类上引入了信度(Trustworthiness)这个概念,该概念来源于DS证据理论(Dempster-Shafer Evidence Theory),通过计算一个样本的置信度可以降低困难样本被错误预测时的损失。有研究显示用多个分类器可以减少模型的方差,提高长尾数据分类的鲁棒性,因此论文还用到了集成学习,将多个专家(expert,可以认为是一个独立的模型)的输出乘以其对应权重再求和得到模型的最终输出结果。每个专家对应的权重是上一个专家的权重与其不确定度的正交和。
无论头部类还是尾部类,其特征区分总是要依赖于对图像进行低级信息的提取,而后再根据这些特征进行分类,这些专家共享一部分泛化的模块,后面再对这些专家进行差异化地训练。ResNet里前两层CNN层只处理图像的低级信息,获取图像的一些简单特征。所以ResNet的前两个阶段在所有专家之间参数共享。而后面的一些模块则分别进行学习。


















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









