







目录
一、概述
R3Det论文中提到一个端到端的精细化的单级旋转检测器,通过从粗到细的逐步回归的方法快速和准确地目标检测。
考虑到现有的改进的单级检测器中特征错位的不足,我们设计了一个特征精细化模块(FRM),通过获得更准确的特征来提高检测性能。FRM特征细化模块核心就是进行逐像素的特征插值(双线性插值重新获取更精确的特征向量)。
提出一个近似SkewIoU来解决SkewIoU计算不可推导的问题,也相较于Smooth L1 Loss对不同尺寸的旋转框有更好的拟合效果。
本文也在DOTA、HRSC2016、UCAS-AOD三个遥感数据集和ICDAR2015场景文本数据集上进行了对比实验和消融实验,验证本文方法有效性。
二、三个挑战
当前目标检测方法分为两类,以faster rcnn等rcnn系列为主的two-stage(二阶段检测器)和YOLO系列和SSD的one-stage(单级检测器)
由于场景文本检测、零售场景检测、遥感物体检测中物体有不同的方向,所以提出符合通用检测框架的旋转检测器,其中本文提出三个挑战:
(1)大纵横比:大纵横比对象之间的联合倾斜交叉点得分对角度的变化很敏感。本文提出高精度、快速旋转的单级检测器,实现高精度检测,相较于基于学习的特征对齐方法,缺乏明确的机制来补偿错位,本文提出一个直接有效的基于纯计算的方法,来扩展到处理旋转的情况。
(2)对于密集排列的物体:由于在遥感领域等物体紧密排列。本文提出了一个从粗到细渐进回归的方法,首先使用水平锚来提高检测速度,在使用旋转锚来调整精度,这可以更加高效和灵活。
(3)任意旋转的物体:由于图像的物体可能出现在不同方向上,所以检测器需要具有判断不同方向的能力。本文提出了一种可推导的近似的SkewIoU损失,解决了SkewIoU计算不可微问题,相较于Smooth L1损失,可以实现更加精确的旋转估计,这种方法保留了准确的SkewIoU振幅,只是近似了SkewIoU损耗的梯度方向。
三、网络架构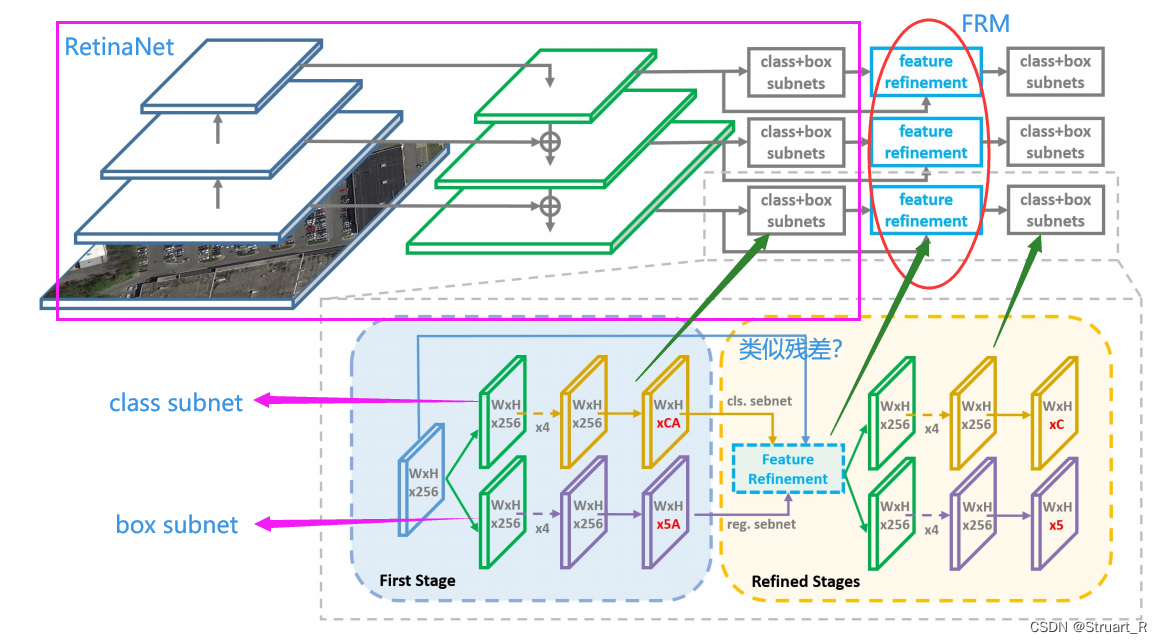
R3Det网络结构,首先使用Resnet的baseline,添加RetinaNet结构中的FPN,构建单级检测器,后使用残差结构添加FRM(特征细化模块)接二阶段(水平锚和旋转锚)分类和回归的subnet,其中Refined Stages的细化阶段可能会进行若干次。(其实这个改进单阶段检测器对比于改进二阶段检测器使用RoI Align和RoI Pooling,可以保持速度优势,仍然使用了全卷积结构)
下图为RetinaNet网络结构可以进行对比,RetinaNet网络结构:ResNet+FPN+class和box的subnet。
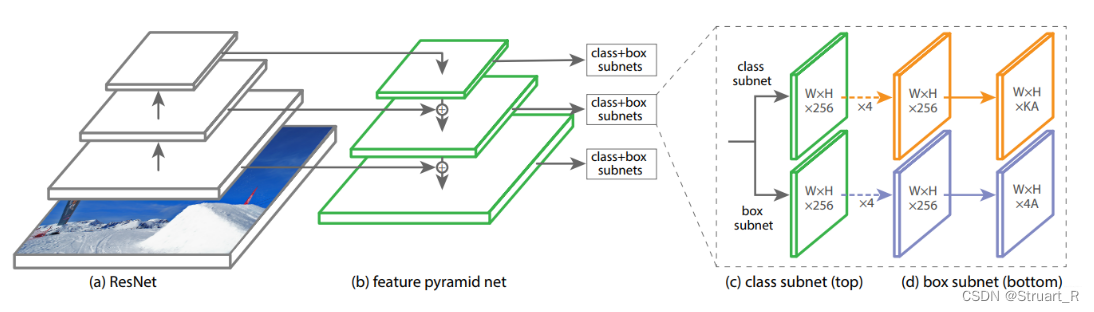
1、旋转RetinaNet
作为当时旋转框领域最为先进的模型R3Det,采用基于RetinaNet模型,使用x,y,w,h,θ,来将水平锚阶段结束的水平框转化为旋转框(真实框GT box,预测框bounding box)。
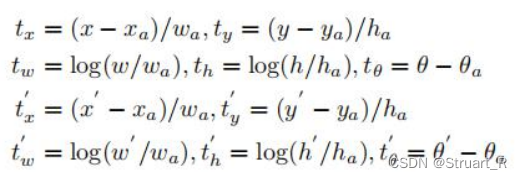
公式中分别是真实框,锚框,预测框的参数。
表示真实框的旋转框,预测框的旋转框的参数。
由于水平框转换为旋转框的过程中,由于框的比例不同,导致求解损失函数Smooth L1 Loss时会出现交并比明显不同,但是损失函数相同的结果,使用近似的SkewIoU损失函数可以避免这个问题。例如下图的两种框:
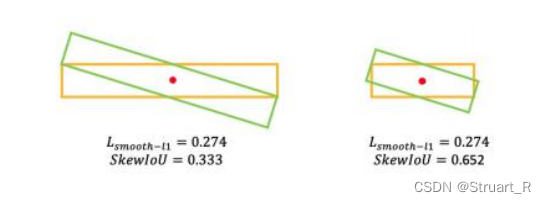
对于大长宽比的物体,他们对于SkewIoU十分敏感,但由于SkewIoU损失函数不可计算的原因,我们不能把SkewIoU直接作为回归损失,在SCRDet网络中对于小的、杂乱的、旋转的物体提供了可推导的SkewIoU损失函数。
与传统回归损失相比,新的回归损失包括两个部分:确定梯度传播方向,是保证损失函数可推导的重要组成部分,
负责调整损失值(即梯度大小),考虑到SkewIoU和Smooth L1损失之间的不一致性,使用第二个方程作为回归损失主导梯度函数。
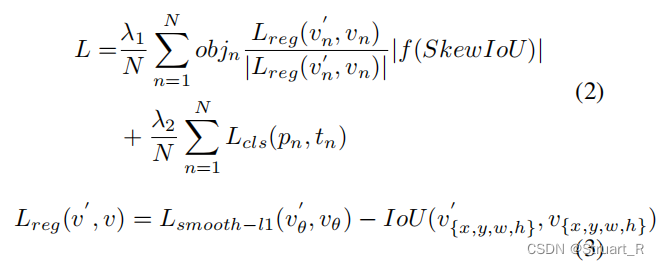
在这里再写一遍cls、reg、obj的区别:
cls:类别预测,对应类别预测损失,计算的是模型预测的类别与真实类别之间的差异
reg:边界框回归,对应损失为IoU损失,计算的是模型预测的边界框与真实边界框之间的交并比差异。
obj:目标存在概率,对应对象存在概率损失,计算的是模型预测的目标存在概率与真实存在概率之间的差异。
2、精细化旋转RetinaNet
精细检测
精细化可以提高旋转检测的召回率,使用不同的IoU阈值来加入多个细化阶段,第一阶段使用前景IoU阈值0.5和背景IoU阈值0.4外,第一细化阶段的阈值使用0.6和0.5,其他的细化阶段使用阈值0.7和0.6。精细化检测的总损失计算如下:
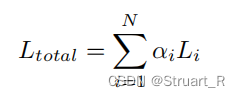
其中,为第i个细化过程的损失值,权衡系数为
默认为1。
功能模块细化
由于多次进行精细化检测使用同一个feature map,边界框位置变化导致feature错位,导致特征描述不准确,对于大长宽比和小样本的类别不利。
本文提出在当前细化边界框的位置信息重新编码到对应的特征点时,一逐个像素点的方式重构feature map,实现特征对齐,在获取精细化检测框的对应位置特征信息中,使用了双线性插值的方法。
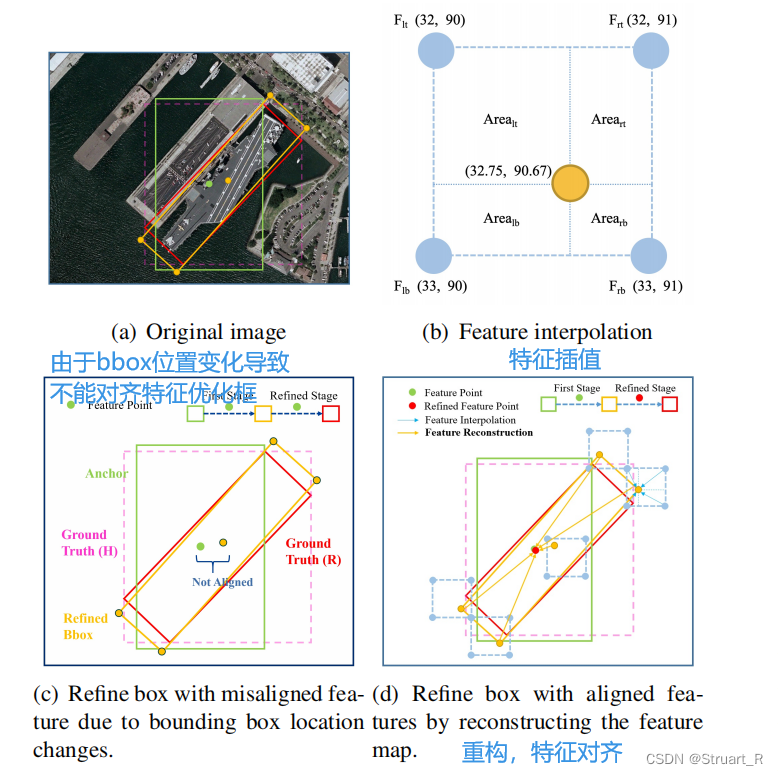
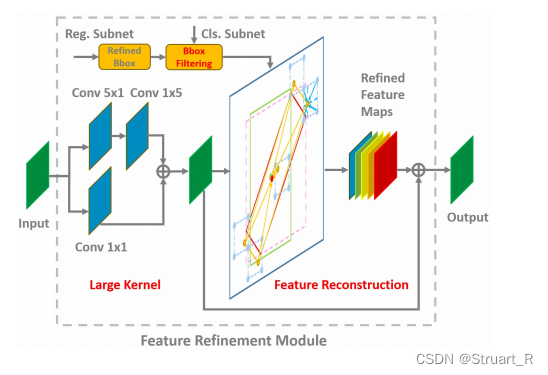
文中提供了一个特征细化模块的伪代码如下,具体来说,通过进行双向卷积添加特征映射feature map,得到一个新的特征(LK),在细化过程中,只保留每个特征点得分最高的bounding box,以提高速度(框过滤算法,BF),同时保证每个特征点只对应一个细化的bounding box,框过滤是特征重构的重要步骤,对于特征图中的每个特征点,我们根据细化后的边界框的五个点(一个中心,四个角点)来获取对应的特征向量,最后采取双线性插值获得更精确的特征向量。最后将5个特征向量相加,替换当前的特征向量,重构特征图feature map。细化过程可以进行多次重复。

本文给出FRM的内部算法可视化:
3、与RoIAlign(感兴趣区域插值)进行比较
其实RoIAlign也是为了解决二阶段问题目标检测中特征错位的问题,为了弥补RoIPooling提取感兴趣区域后,导致的feature map错位而设计。
相较于RoIAlign算法,FRM的优点如下:
(1)RoI Align采样点较多,对检测器性能影响较大,而FRM只抽取五个特征点(一个中心,四个角点)大约是RoI Align的四十分之一,可以提高速度优势。
(2)RoI Align在分类和回归之前首先获取RoI对应的特征,而FRM首先获取特征点对应特征,然后重构整个特征图,与RoI的全连接结构相比,FRM可以保持完整的卷积结构,效率更快,参数更少。
4、消融实验与对比实验
针对FRM的算法中各阶段LK、FR和是否使用SkewIoU做了消融实验,结果一目了然,在全部使用的情况下mAP相较于旋转的RetinaNet-R高了7个百分点。
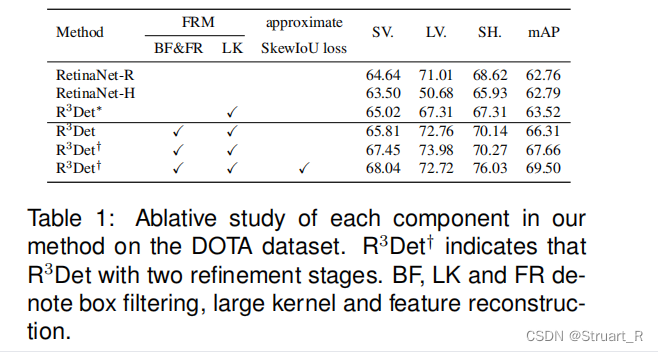
针对不同场景的数据集也对上述变量做了测试,FRM还是略胜一筹。

针对FRM中特征重构的算法双线性插值、随机双线性插值(不太懂还搜不到)和量化进行了对比实验,双线性插值的mAP高于其他各种算法,(反卷积和反池化有没有效果呢?)

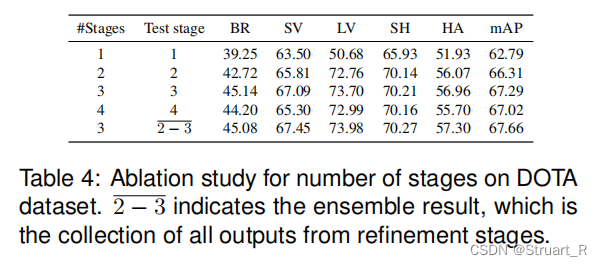
对于持续进行细化多次阶段在DOTA数据的不同的类别上的拟合效果进行了对比,作者验证大概2、3轮左右可以达到峰值。
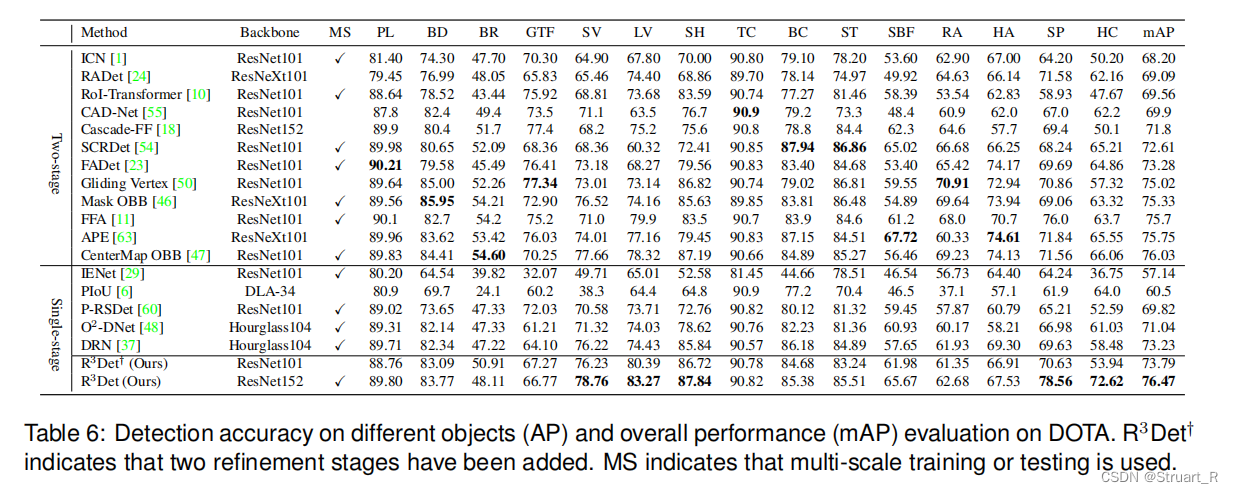
另外与当前主流模型进行了针对不同的类别的检测效果对比,二阶段的算法精准度整体优于一阶段是合理的,一阶段中R3Det基于ResNet152的backbone达到更好的精度效果,另外速度方面感觉会很慢(其他的二阶段基本都是用ResNet101对比的,除了个别模型)
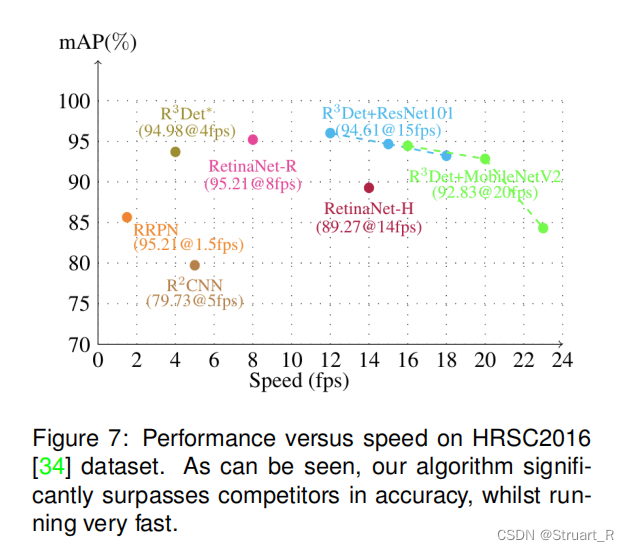
在速度方面使用HRSC数据集做了一个对比,但如果提高backbone的量级,时间上可能会有很大的劣势
论文来源:https://arxiv.org/abs/1908.05612
代码来源:https://github.com/SJTU-Thinklab-Det/r3det-on-mmdetection















 1792
1792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









