







目录
一、2D到3D转换模块
核心目的:由于将2D空间转换到BEV,所以我们要引入一个媒介3D空间,通过2D->3D->BEV转换到BEV特征。
1、LSS
目前基于环视图像信息,去构建BEV视角的特征的主流方法一共有两种:显式估计图像深度信息,完成BEV的构建;基于transformer的查询方式,利用BEV Query构建BEV特征。

LSS的目的:提出一种名为“Lift-Splat-Shoot”的模型,用于从多视图图像中学习一致的表示,并实现端到端的自动驾驶规划,该模型将图像转换为3D点云表示,并从BEV中进行预测规划,以实现对相机视野内上下文特征的融合和利用。
Lift(提取特征):通过对图像进行处理,为图像中每一个像素生成所有可能深度的一系列点,并为每个点生成特征,对于每个像素置信度最高的深度,生成锥形点云,表示相机视野内的上下文特征,生成一个深度估计。
Splat(投影):将每个锥形点云投影到参考平面上,得到鸟瞰图的表示。这个过程将锥形点云转换为固定维度的张量,可以被后续的卷积神经网络处理。
Shoot(规划):使用推断的成本地图进行运动规划。通过“Shoot”不同的轨迹,计算它们的成本,并选择成本最低的轨迹作为最终的规划结果。
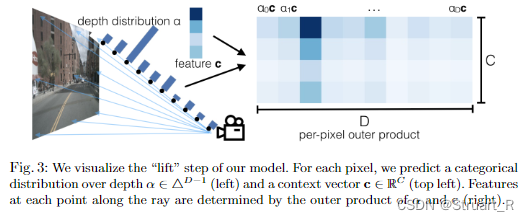
2、Pseudo LiDAR
Pseudo LiDAR(伪点云)通过将环视图像经过深度估计生成深度图,并将深度图反投影生成3D伪点云(点云格式,但与实际存在一定误差),后续可以通过接一个基于LiDAR预测3D图像的预测头,或者将LiDAR转换成BEV,通过与Camera得到的视觉特征结合起来提取3D图bounding boxes来进行回归和分类。
相比于LSS方法,LSS方法通过环视图像生成视锥,并获得深度估计,将锥形点云投影到参考平面得到BEV鸟瞰图,后续基于BEV进行预测。

二、3D到2D转换模块
3D到2D的转换是自上而下的方式,一般有显式mapping和隐式mapping两种方式。
1、Explicit mapping
显式mapping中的DETR3D模型,利用环视图像先提取出2D特征,经过变换矩阵连接到3D位置,利用3D object query对2D图像的特征进行查询。
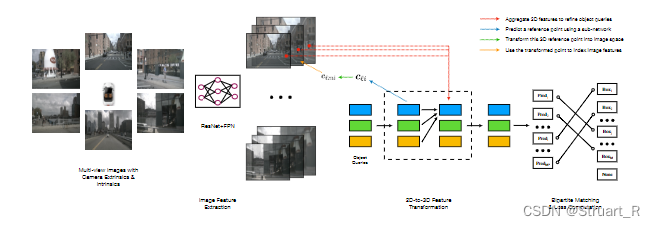
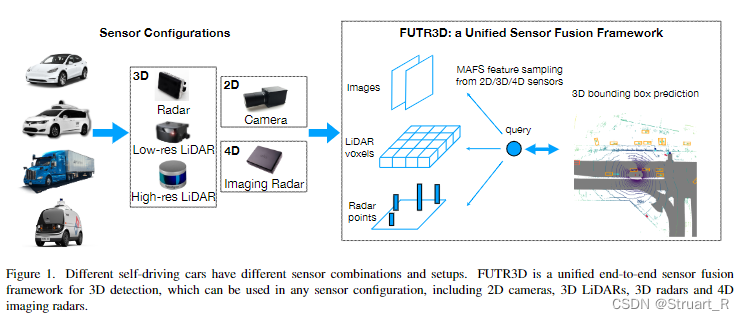
显式mapping中的FUTR3D模型,提出模态不可知的特征采样器(MAFS),可以从不同传感器(激光雷达、雷达、摄像机)中采样并通过不同的主干网络提取多模态特征,根据查询点聚合特征,为自动驾驶提供更高的数据灵活性。
2、Implicit mapping
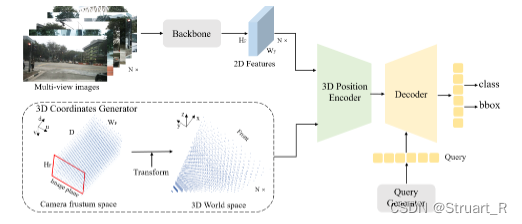
隐式mapping中的PETR3D模型,通过分别输入环视图像和3D坐标生成器,3D坐标生成器通过将所有视角共享的相机视锥空间离散化为一个3D网格,最终得到3D坐标,环视图像通过主干网络提取2D特征,与3D坐标生成器生成的3D坐标注入3D位置编码器,生成3D位置感知特征,查询器生成对象查询,通过与transformer解码器的3D位置感知特征进行更新,更新后的查询用于分类和回归任务。
隐式mapping和显式mapping的区别:
(1) 隐式mapping:隐式mapping是通过学习从3D空间到2D图像的映射函数来实现的。它不需要显式地定义或计算3D和2D之间的映射关系,而是通过神经网络等模型自动学习这种映射关系。隐式mapping的优点是可以适应不同的数据分布和复杂的映射关系,但缺点是可能需要更多的训练数据和计算资源。
(2)显式mapping:显式mapping是通过定义和计算3D和2D之间的映射关系来实现的。它通常基于几何或物理原理,例如相机投影模型,将3D点映射到2D图像上的像素位置。显式mapping的优点是可以精确地控制映射过程,但缺点是可能需要手动定义和计算复杂的映射关系,并且对于不同的数据分布和映射关系可能不够灵活。
三、transformer相关
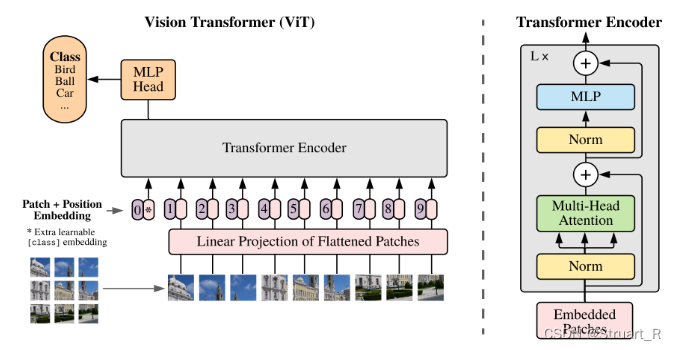
1、VIT
VIT(vision transformer),将transformer引入视觉的主要模型之一,通过将图像切分,得到图像块,将图像块提取特征,将完整图像转换为图像序列,但是由于应用transformer,损失了位置信息,同时使用position embedding的方式补充位置缺失带来的误差。
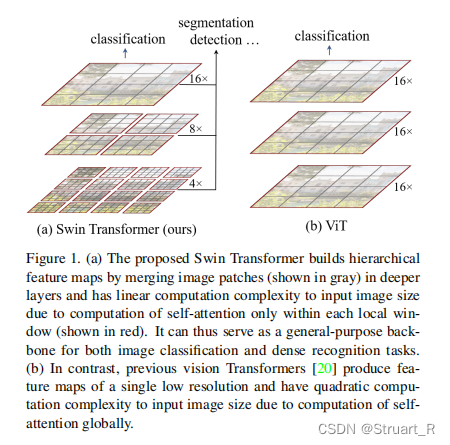
2、Swin Transformer
相比于VIT,SwinTransformer采用了分层的transformer结构,对于输入图像分解为若干小块,然后对每个小块应用transformer模块,这种分层一方面使得SwinTransformer更好的处理高分辨率的大尺寸图像,另一方面对于目标检测,图像分割中,大部分图像需要检测的物体不会占据图像较大空间,而对于较远距离的行人检测就十分困难,使用Swintransformer对于较小物体的观测会处理的更加细致。
SwinTransformer,在每一个windows中处理自注意力机制,另外允许跨窗口的不同分辨率的输出进行交互,达到更好的融合效果。
参考视频:自动驾驶之心BEV感知课程

















 210
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









