







目录
一、概述
VideoCrafter->VideoCrafter->DynamiCrafter->ViewCrafter
提出一种利用视频扩散模型为开放域图像添加动画视频的方法DynamiCrafter,通过text-to-video的扩散模型作为运动先验,把图像放入生成过程中作为引导,并且采用双流图像作为输入,包括文本对齐上下文,以及视觉细节引导,确保视频扩散模型以互补的方式合成保留细节的动态内容。
(1)提出一个利用动画开放域图像的视频扩散先验的方法DynamiCrafter,显著优于近期的SOTA。
(2)提出了一种双流图像引入模型的方式,以实现图像动画的目标。
(3)率先研究了开放域图像动画的运动控制文本,并初步试验证明了概念。
二、相关工作
1、图像动画
从图像生成动画早期使用物理模拟的方法,专注于模拟特定对象的运动。但由于每个对象类别独立建模,导致通用性较低。
为了产生真实的运动,基于参考的模型,将运动或外观信息转换为参考信号比如视频格式,转移到生成模型里。这种方法显示出较好的时间相干性,但参考限制了实际应用。
基于GAN的方法,通过扰动初始潜在空间或者在潜在空间中进行随机的walk生成帧,但是他没有时间意识。
近期基于运动先验的方法,通过显式或者隐式的图像渲染估计运动场或者几何先验。同样视频预测通过从视频数据中学习时空先验,从单个图像开始预测未来的视频帧。
因为以往的方法主要集中于有所精心设计的领域,而且是随机扰动的运动,而一般的情况下图像动画包括很多人、自然、流动物体等等。所以该论文提出一种通用框架,目的是在开放域中进行广泛内容和风格的视频生成。
2、视频扩散模型
第一个视频扩散模型VDM,使用从像素空间中进行时间空间分解的U-Net建模低分辨率视频。
Imagen-Video提出了级联式DM模型,通过v-prediction生成高清视频。
为了降低训练成本,引入T2V方法(Text to Video),通过潜在模型或混合像素的潜在模型中学习VDM。与T2I方法相同,T2V中也开始引入结构,姿态,边缘等视觉条件。
近期,Seer,VideoComposer,l2VGen-XL局限于特定领域,或者无法时间连贯且真实的运动,或者无法保留较好的输入图像细节。一些T2V模型虽然引入了I2V但是无法完全follow输入图像。
DynamiCrafter框架旨在利用预训练的VDM的动态先验,通过特定设计来更好地理解语义并保持输入图像的视觉一致性,从而实现从静态图像到动态视频的自然转换。
三、DynamiCrafter
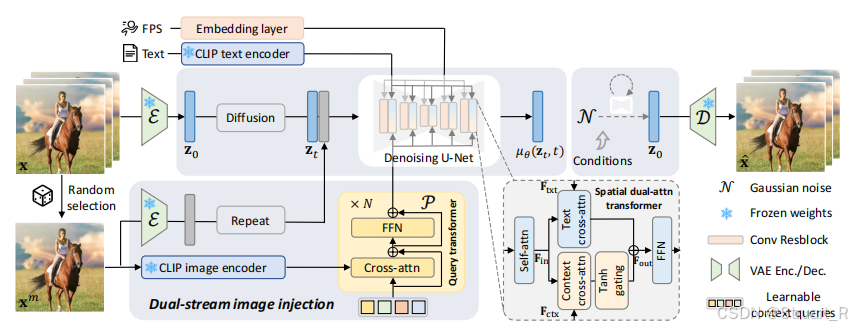
DynamiCrafter是基于一个潜在视频扩散模型VideoCrafter进行做的,该论文将一个视频通过一个潜在空间
进行逐帧编码,之后通过前向扩散过程
和后向去噪模型
,其中
表示其他条件,之后通过解码器
。
训练过程:双流路线,这也是相较于videocrafter的提升,通过随机采样来保证图像不单调,而通过双流路线,在噪音上拼接图像可以提高图像一致性。下图第一行是随机采样+双流concat,第二行都没有使用,第三行为单一采样第一帧图像+双流concat。

推理过程:从噪声中推理图像,输入的图像作为条件图像(嵌入信息,而不是输入)concat到高斯噪音中。
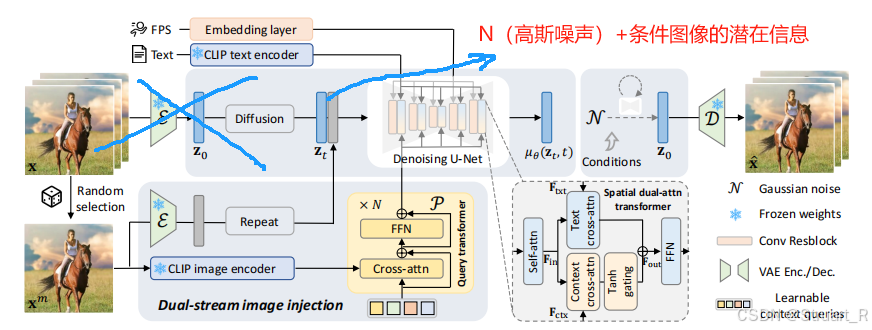
重要的method:
1、FPS embedding layer:固定帧数时,FPS代表视频的动态效果,采用time embedding的方式引入UNet。(这一部分在videocrafter里,一个是帧数,一个是扩散时间步)
2、Dual Stream Image Injection Mechanism:
文本对齐的图像语义表征输入:首先random select出的图像,通过clip+query former压缩到77个image token,并送入UNet中的cross attention。
细粒度图像空间:将image经过VAE得到潜在空间表示,在通道维度扩散video_length次后,与noise_latents进行拼接,UNet输出变为原有的2倍。
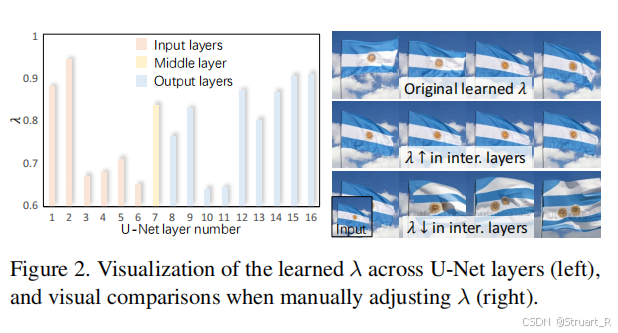
3、Dual Cross-Attention Layers:在UNet解码器部分使用两个cross attention加权形式,分别把文本嵌入和图像嵌入作为条件,用tanh作为门控实现文本和图像间的平衡,并且每一层自适应的学习。增大λ,增大image condition,减小text condition,跨帧运动被抑制。减小λ,减小image condition,增大text condition,画面结构受到影响。
random select的目的:防止特定位置的帧映射到图像条件,而导致死板,无法完成插帧。另外,也强制上下文更加灵活,避免特定帧而导致过度依赖。
由于dynamiccrafter实现了(I+T)2V的同时,也实现了循环生成视频(first frame 2 video)和视频插帧(first and last frames 2 video)这也是viewcrafter可以作单视图和稀疏视图的一个契机。

VDG:视觉细节引导,visual detail guidance,由于预训练的CLIP encoder在完全保留输入图像信息方面能力尚且有限,所以为了增强视觉一致性,提出为视频模型提供来自图像的额外视觉细节。具体来说通过将条件图像与每一帧的初始噪声concat并且作为一种guidance来输入到denoise U-Net中,通过文字和图像互补的方式集成输入图像的全局上下文和局部细节。

四、实验效果


















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









