







一、模型描述
DynamiCrafter 是一种(文本-)图像到视频/图像动画的方法,旨在从条件图像和文本提示中生成短视频片段(约 2 秒)。
开发者 :香港中文大学 & 腾讯 AI 实验室
资助方 :香港中文大学 & 腾讯 AI 实验室
模型类型 :生成性(文本-)图像到视频模型
模型资源
Github 仓库(https://github.com/Doubiiu/DynamiCrafter),其中包含了详细的实现代码。
仓库链接 :https://github.com/Doubiiu/DynamiCrafter
论文链接 :https://arxiv.org/abs/2310.12190
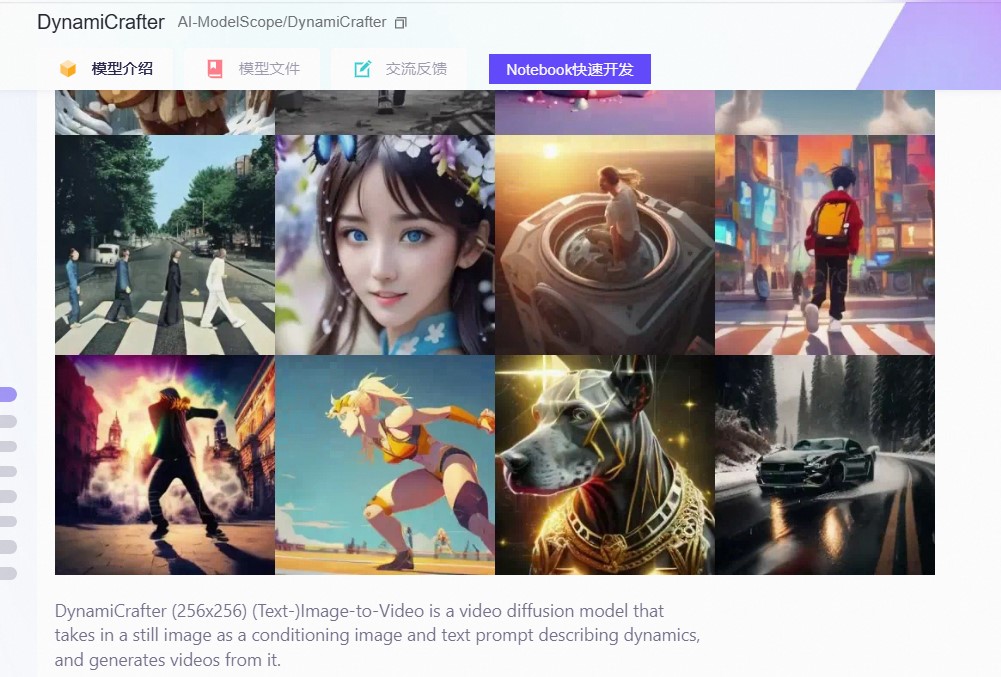
二、特点
- 视频扩散先验技术:DynamiCrafter 使用视频扩散先验技术来生成动画,这是一种基于深度学习的方法,可以模拟真实世界的运动模式。
- 开放域图像动画化:该项目能够处理各种类型的静态图像,包括风景、人物、动物、交通工具、雕塑等,不限于特定的主题或风格。
- 多种主题和风格:DynamiCrafter 能够处理多种类型的图像,满足不同创作需求。
- 文本控制运动:用户可以通过输入文本指令来控制动画的运动,这为动画创作提供了更大的灵活性和创意空间。
- 高分辨率支持:最新的更新推出了高分辨率模型,支持生成 576x1024 和 320x512 分辨率的视频,让用户可以获得更清晰、更细腻的动画效果。
三、部署流程
1. 安装更新基础环境
apt update
apt upgrade
apt install build-essential
2. 创建虚拟环境
conda create -n DynamiCrafter python=3.8.5
conda activate DynamiCrafter
3. 克隆项目仓库
git lfs install
git clone https://github.com/Doubiiu/DynamiCrafter.git
4. 打开文件,安装依赖
cd DynamiCrafter
pip install -r requirements.txt
5. 修改访问端口
DynamiCrafter/gradio_app.py打开文件,划到最底部
将server_name设置为'0.0.0.0'、server_port设置为8080
dynamicrafter_iface.launch(server_name='0.0.0.0', server_port=8080, max_threads=1)
6. 运行模型
本地 Gradio 演示,图片到视频生成。
在终端中输入以下命令(根据所需的分辨率:1024、512 或 256 选择一个模型)。
python gradio_app.py --res 1024

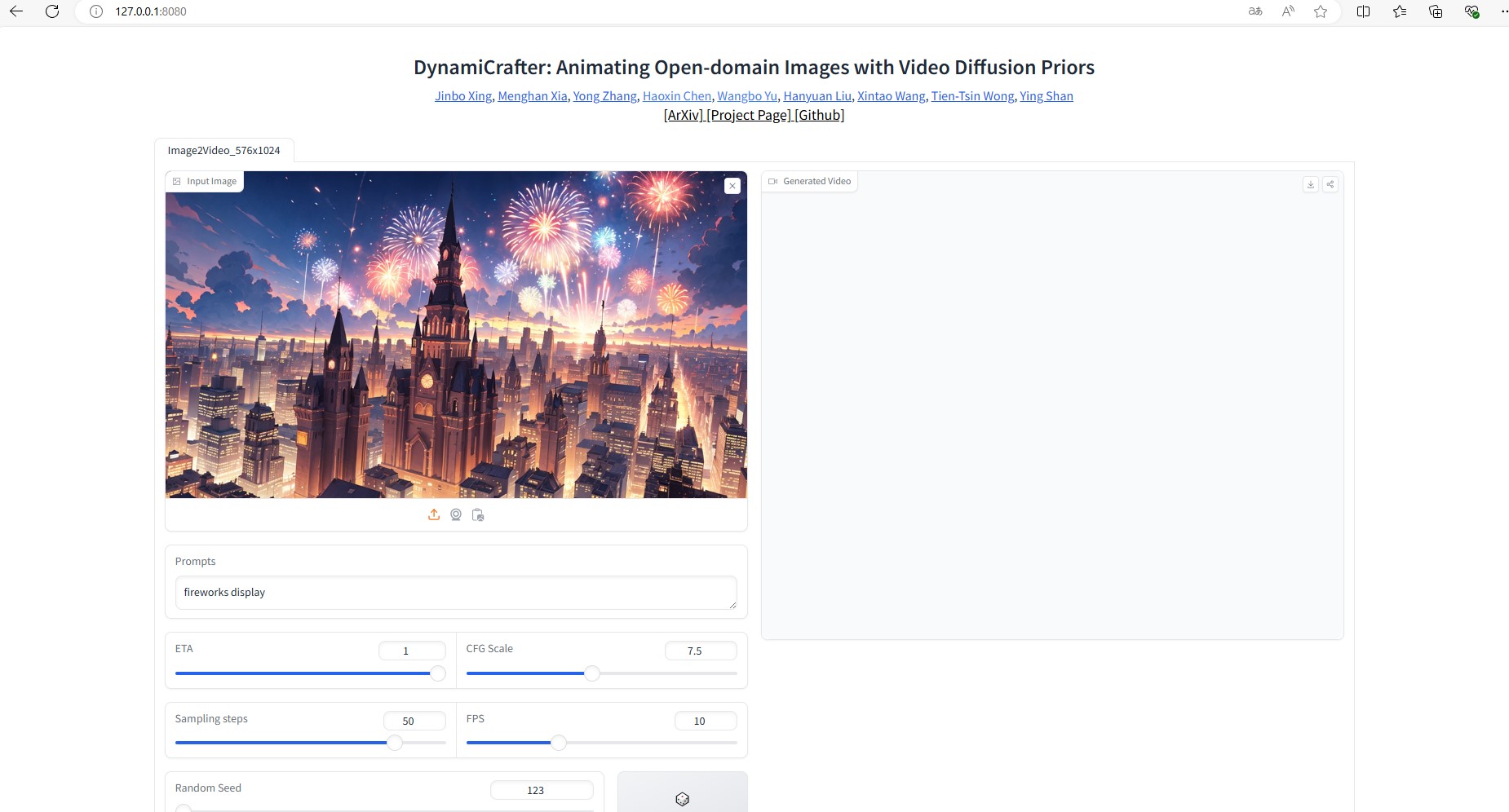
四、网页演示
开放端口,点击模型运行结束下方的“http://0.0.0.0”,进入网站搜索页面,将“0.0.0.0:8080”改为“127.0.0.1:8080”搜索,即可进入UI界面使用


















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









