







1.motivation
由于知识从多个源域转移到目标域,多源域自适应比传统的数据分析更具挑战性。为此,作者在真实世界的数据集上进行了全面的实验,以证明本文方法及其基于最优运输的模仿学习观点的优点。实验结果表明,提出的方法在包括digits - 5、Office-Caltech10和Office-31在内的多源域自适应基准数据集上达到了所知的最先进的性能。
受模仿学习原理的启发,本文提出了一种基于最优传输和模仿学习理论的多源数据挖掘模型。本文方法由两个合作代理组成:教师分类器和学生分类器。教师分类器是一个综合专家,它利用领域专家的知识,理论上可以保证完美地处理源示例,而作用于目标领域的学生分类器试图模仿作用于源领域的教师分类器。基于最优传输的严谨理论使这种跨域模仿成为可能,并且有助于减轻数据迁移和标签迁移,这是数据分析研究中固有的棘手问题。在MSDA背景下应用师生机制时,寻求两个自然提出的问题的解决方案:1)如何确定教师 ii)学生模仿老师的原则和机制是什么? 本文基于最优运输的文献,通过开发一个严格而直观的理论来解决这两个问题。这项工作中的贡献总结如下:
- 提出了一个严格的基于ot的理论来利用模仿学习进行领域适应。
- 在模仿学习的视角下,本文提出了一种新的MSDA模型,该模型利用了两个合作主体:教师和学生。MOST的实现也可以在线获得。
- 在包括digits - 5、Office-Caltech10和Office31在内的多源域自适应基准数据集上进行了全面的实验。实验结果表明,本文的MOST在这些基准数据集上达到了我们所知的最先进的性能。
2.Background
2.1 Optimal transport
在一些温和的条件下,如Santambrogio[2015]中的定理1.32和1.33所述,Kantorovich problem (KP)与Monge problem (MP)相同,为了方便起见,我们将Md和Kd统称为Wd,即Wd (Q, P) = Kd (Q, P) = Md (Q, P)。
此外,在一些温和的条件下,如Villani[2008]的定理5.10所述,可以用其对应的对偶形式代替原始形式
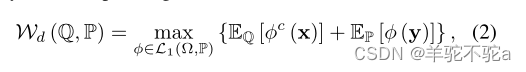
其中并且
是函数
的c变换,定义为
。
最优运输的聚类观点。这种最优运输的观点已被用于研究一类丰富的分层和多层聚类问题。提出了最优运输的聚类观点,这有助于解释本文在续集中开发的方法。设P和Q是两个离散分布,定义为
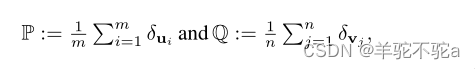
其中δx表示以x为中心的狄拉克测度。在不丧失一般性的情况下,可以假设n≤m,并将Wasserstein距离Wd (P, Q) w.r.t.视为度量d。以下定理表征了OT的聚类观点。
定理1。考虑以下优化问题:。设
,
为其最优解,T∗为最优运输映射,为
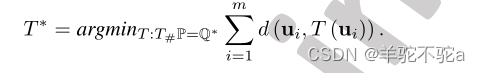
进一步,设和σ *表示以下聚类问题的最优解:
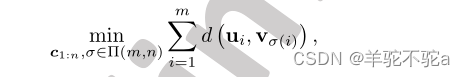
式中Π (m, n)是从{1,…, m}到{1,…n}满射映射集合。然后我们有和
。
上述定理表明,如果我们学习Q的原子以最小化Wd (P, Q) w.r.t.度规d,那么Q的最佳原子将成为由P原子形成的簇的质心,或者Q的原子正在移动以寻找P的原子群,目的是最小化w.r.t.度规d的畸变。
2.2熵正则对偶性
为了实现最优传输在机器学习和深度学习中的应用,Genevay等人在Genevay等人[2016]中开发了一种熵正则对偶形式。首先,他们提出在Kantorovich problem (KP)中的原始形式中加入一个熵正则化项。
其中为正则化率,DKL(·||·)为KL散度,Q⊗P表示Q和P独立的特定耦合。
→0,时,
逼近
,(3)的最优运输计划
也弱收敛于(1)的最优运输计划γ *。在实践中,我们设置(3)中
是一个小的正数,因此
非常接近γ *。
其次,利用fenchell - rockafellar定理,得到了势的对偶形式
3.理论的发展
3.1 Priliminaries
我们首先考察一般的监督学习设置。考虑假设类H中的假设h和标记函数f(即f(·)∈, h(·)∈
,其中
,类的个数M,设dy是度量或
的散度。我们进一步定义假设h w.r.t.的一般损失,数据分布P和标记函数f为:
通过将度量或散度dY定义为,其中1i是一个one-hot向量,可以恢复深度学习中广泛使用的交叉熵损失。
接下来,考虑一个领域自适应设置,其中我们有一个具有分布PS的源空间X S和一个具有分布PT的目标空间X T。给定两对
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









