







前提:环境配置
-
配置Python环境,安装必要的库和依赖,如TensorFlow、PyTorch、Keras、OpenCV、Gradio等。
-
确保CUDA和cuDNN(如果使用NVIDIA GPU)已正确安装和配置。
演示运行代码框架
部分项目结构和调用关系
universal-image-restoration/
│ ├── factory.py #open_clip.create_model_from_pretrained()方法
├── config/
│ ├── daclip-sde/
│ |──models/
│ ├──__init__.py # 包含create_model()方法
│ ├──networks.py # 定义生成对抗网络的生成器、鉴别器和感知损失模型
│ ├──denosing_model.py # 定义DenosingModel类,继承自BaseModel
│ ├──base_model.py # 定义BaseModel类
│ |──options/
│ ├──test.yml #演示代码使用的配置参数文件
│ |── options.py # 包含 prase() 、dict_to_nonedict()方法
│ └──app.py # 这是当前演示代码的文件
│
└── utils/
├── __init__.py
├── sde_utils.py # 包含sde类和IRSDE类
└── file_utils.py # 包含 OrderedYaml() 方法
1.设置命令行参数:
import argparse
import options as option
parser = argparse.ArgumentParser()
parser.add_argument("-opt", type=str, default='options/test.yml', help="Path to options YMAL file.")
# 添加一个命令行选项,这个选项被命名为-opt,它是一个接受字符串类型的参数,默认为该文件对应配置的yml地址
opt = option.parse(parser.parse_args().opt, is_train=False)
# 调用options.py中的parse方法,接受两个参数,args.opt是通过 argparse 解析器得到的选项值,默认yml地址,is_train与训练配置相关,演示不需要-
argparse.ArgumentParser():- 这是
argparse模块的一个类,用于创建一个新的解析器对象。 - 解析器对象包含了用于添加参数和选项的方法,并且可以生成帮助和使用信息。
- 这是
创建了ArgumentParser对象后,你可以使用
add_argument()
来添加你的程序需要接受的命令行参数和选项。例如,你可以添加位置参数(必须提供的参数)、可选参数(可以提供,也可以不提供的参数)、带有默认值的参数等。
这个解析器对象随后可以用来解析命令行输入。parse_args()方法是ArgumentParser对象的一个方法,它解析命令行输入并返回包含提供参数的Namespace对象。这个Namespace对象包含了所有的命令行参数,可以像访问字典一样访问这些参数。例如上面的parser.parse_args().opt
自定义函数parse()
主要任务是读取yml中的GPU、地址、数据集、训练测试参数等转为opt字典。
import logging
import os
import os.path as osp
import sys
import yaml
# sys优先寻找../../路径下的文件,方便import utils
sys.path.insert(0, "../../")
from utils.file_utils import OrderedYaml
Loader, Dumper = OrderedYaml()
# 使用自定义的OrderedYaml()返回的 Loader 来加载一个YAML文件。
# 由于 Loader 被设计为支持有序字典,因此加载后的数据中的字典将保持其键的原始顺序。
def parse(opt_path, is_train=True):
# 读取YAML文件
with open(opt_path, mode="r") as f:
opt = yaml.load(f, Loader=Loader)
# export CUDA_VISIBLE_DEVICES 输出可用的GPU list,默认只有gpu 0
gpu_list = ",".join(str(x) for x in opt["gpu_ids"])
os.environ["CUDA_VISIBLE_DEVICES"] = gpu_list
opt["path"]["root"] = osp.abspath(
osp.join(__file__, osp.pardir, osp.pardir, osp.pardir, osp.pardir)
)
# osp 是 os.path 的常用别名,在 Python 中用于处理操作系统路径相关的操作。
# 这行代码设置 opt 字典下的 "path" 键的 "root" 子键的值为当前文件(__file__)所在目录的上上上上级(即daclip-uir-main的)绝对路径。
# osp.join 函数用于连接多个路径部分,osp.pardir 是 pathlib 模块中的一个常量,表示当前目录的上一级目录。
# 连续使用四次 osp.pardir 实际上是将路径向上移动了四级,然后 osp.abspath 函数将这个相对路径转换为绝对路径。
path = osp.abspath(__file__)
# 这行代码获取当前文件的绝对路径并赋值给变量 path。__file__ 是一个特殊变量,它包含了当前脚本的路径。osp.abspath 函数将这个路径转换为绝对路径。
config_dir = path.split("\\")[-2]
# split 方法将 path 字符串按 \ 分割成一个列表,然后通过索引 [-2] 获取这个列表的倒数第二个元素,即配置目录的名称
if is_train:
pass
else:
results_root = osp.join(opt["path"]["root"], "results", config_dir)
opt["path"]["results_root"] = osp.join(results_root, opt["name"])
opt["path"]["log"] = osp.join(results_root, opt["name"])
# 更新了opt字典中的"path"键,为其添加了两个新的子键:"results_root"和"log"。
# "results_root"子键的值是results_root路径与一个名为opt["name"]的字符串连接后的结果。
# "log"子键的值是results_root路径与opt["name"]连接后的结果,这通常用于存放日志文件。
return opt
test.yml中的部分配置
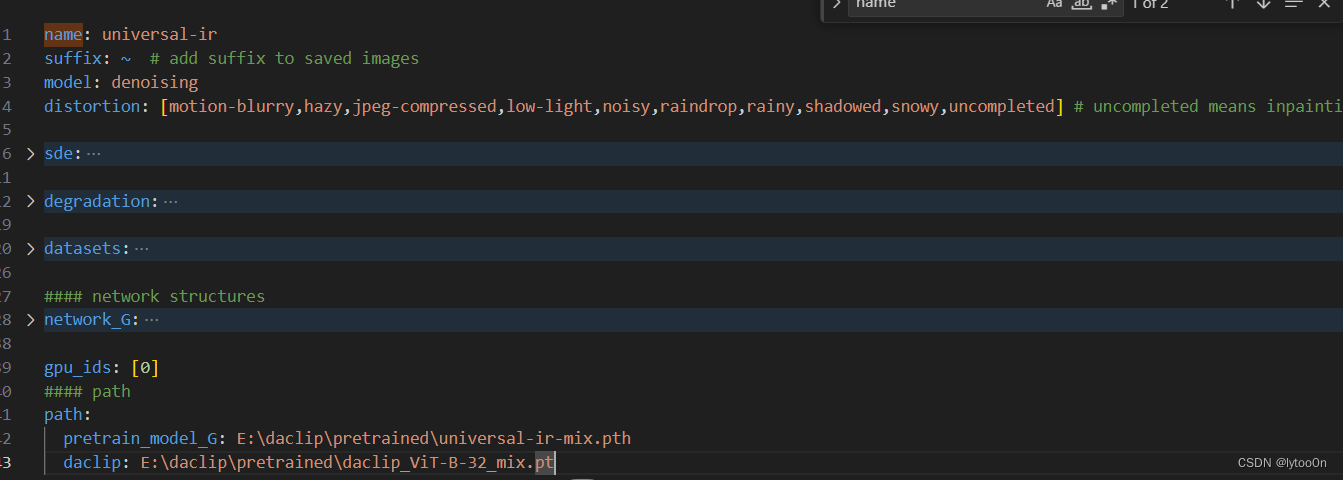
2.模型和预处理加载:
from models import create_model
import open_clip
import utils as util
opt = option.dict_to_nonedict(opt)
# convert to NoneDict, which return None for missing key.
# load pretrained model by default
model = create_model(opt)
# 在models的init.py中的create_model()
device = model.device
clip_model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=opt['path']['daclip'])
# open_clip提供了对 OpenAI 的 CLIP 模型的访问和使用。
# open_clip.create_model_from_pretrained 是 open_clip 库中的一个函数,用于创建和初始化一个预训练的 CLIP 模型。
# 'daclip_ViT-B-32' 是指定的预训练模型的名称。CLIP 有多种不同大小和类型的预训练模型,
# ViT-B-32 是其中之一,它基于 Vision Transformer (ViT) 架构的 B/32 版本。这个版本在性能和大小之间取得了平衡。
# clip_model, preprocess 是这行代码的结果,它包含了两个对象:clip_model 是加载的 CLIP 模型,
# 而 preprocess 是一个函数,用于预处理输入数据(如图像),使其符合模型的输入要求。
clip_model = clip_model.to(device)
sde = util.IRSDE(max_sigma=opt["sde"]["max_sigma"], T=opt["sde"]["T"], schedule=opt["sde"]["schedule"],
eps=opt["sde"]["eps"], device=device)
# 调用sde_utils.py的IRSDE()方法
sde.set_model(model.model)模型创建时设置了分布式训练等相关参数判断,在演示时并不需要设置,
自定义NoneDict类和dict_to_nonedict()方法
将未设置参数设为None,跳过相关判断.
class NoneDict(dict):
def __missing__(self, key):
return None
# NoneDict 类定义,它能够接受一个字典或关键字参数来初始化,它继承自 dict 类,
# convert to NoneDict, which return None for missing key.
# 旨在将一个普通的 Python 字典或列表转换为一个 NoneDict 对象,后者是一个特殊类型的字典,
# 它返回 None 而不是抛出 KeyError 当尝试访问不存在的键 它允许程序在遇到缺失的键时不会崩溃,而是可以安全地继续执行。
def dict_to_nonedict(opt):
if isinstance(opt, dict):
# 这一行检查 opt 是否是一个字典类型(dict)。如果是,它将进入 if 语句块。
new_opt = dict()
# 创建了一个新的空字典 new_opt,这是为了存储转换后的键值对。
for key, sub_opt in opt.items():
# 遍历 opt 字典中的所有键值对。key 是字典的键,sub_opt 是与 key 相关联的值。
new_opt[key] = dict_to_nonedict(sub_opt)
# 调用 dict_to_nonedict 函数递归地处理 sub_opt。这意味着如果 sub_opt 是一个字典或列表,
# 它也会被转换成 NoneDict 或递归地转换成包含 NoneDict 的列表。转换后的值被存储在 new_opt 字典中,与原始的 key 关联
return NoneDict(**new_opt)
# 在处理完所有的键值对后,new_opt 字典被解包(** 操作符)并作为参数传递给 NoneDict 类的构造函数,创建一个新的 NoneDict 实例。
# 这个新的 NoneDict 实例是原始字典的深度拷贝,并且所有的字典和列表都被转换成了 NoneDict 类型。最后,这个新的 NoneDict 实例被返回。
elif isinstance(opt, list):
# 如果 opt 是一个列表,那么进入这个 elif 语句块
return [dict_to_nonedict(sub_opt) for sub_opt in opt]
# 这个列表推导式遍历 opt 列表中的每个元素 sub_opt,并对每个元素递归地调用 dict_to_nonedict 函数。
# 这确保了列表中的每个元素(无论是字典还是列表)都被转换成 NoneDict 或递归地包含 NoneDict 的列表。然后返回这个新列表。
else:
return opt
# return opt 返回原始的 opt 值,如果它不是字典或列表。创建模型
创建主要处理模型model
根据输入的字典进行相关判断创建模型
def create_model(opt):
model = opt["model"]
# YAML中默认model参数为denoising
if model == "denoising":
from .denoising_model import DenoisingModel as M
else:
raise NotImplementedError("Model [{:s}] not recognized.".format( model))
m = M(opt)
# 这个类提供了一个模型完整的训练和测试流程,包括数据准备、模型优化、评估、日志记录和模型保存。
# 它使用 PyTorch 框架,并且考虑了分布式训练的情况。通过 opt 配置字典,用户可以灵活地配置模型的各种参数。
logger.info("Model [{:s}] is created.".format(m.__class__.__name__))
return m
模型DenosingModel类和方法定义

在初始化方法中调用了load方法,而load方法调用BaseModel的 load_network方法,根据地址pretrain_model_G加载了IRSDE预训练模型。
def load(self):
load_path_G = self.opt["path"]["pretrain_model_G"]
# 加载yml路径下的模型预训练权重
if load_path_G is not None:
logger.info("Loading model for G [{:s}] ...".format(load_path_G))
self.load_network(load_path_G, self.model, self.opt["path"]["strict_load"])在BaseModel类中定义device等属性、包含了与学习率调度、网络保存和加载、训练状态保存和恢复相关各方法
class BaseModel:
def __init__(self, opt):
# 构造函数接收一个配置字典 opt,并初始化一些基本属性。
self.opt = opt
# self.opt 存储传入的配置字典。
self.device = torch.device("cuda" if opt["gpu_ids"] is not None else "cpu")
# self.device 根据配置中的 gpu_ids 决定使用 CUDA 设备还是 CPU。
self.is_train = opt["is_train"]
self.schedulers = []
self.optimizers = []
# self.schedulers 和 self.optimizers 分别用于存储学习率调度器和优化器的列表。
#其他类方法省略创建CLIP 模型
clip_model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=opt['path']['daclip'])
clip_model = clip_model.to(device)open_clip.create_model_from_pretrained(),,这是调用open_clip自定义包的init.py中,从factory.py定义的函数。
yml文件提供了对应预训练权重路径,已读取到opt['path']['daclip']参数中。
返回的clip_model 是加载的 CLIP 模型。
def create_model_from_pretrained(
model_name: str,
pretrained: Optional[str] = None,
precision: str = 'fp32',
device: Union[str, torch.device] = 'cpu',
jit: bool = False,
force_quick_gelu: bool = False,
force_custom_text: bool = False,
force_image_size: Optional[Union[int, Tuple[int, int]]] = None,
return_transform: bool = True,
image_mean: Optional[Tuple[float, ...]] = None,
image_std: Optional[Tuple[float, ...]] = None,
cache_dir: Optional[str] = None,
):
model = create_model(
model_name,
pretrained,
precision=precision,
device=device,
jit=jit,
force_quick_gelu=force_quick_gelu,
force_custom_text=force_custom_text,
force_image_size=force_image_size,
cache_dir=cache_dir,
require_pretrained=True,
)
if not return_transform:
return model
image_mean = image_mean or getattr(model.visual, 'image_mean', None)
image_std = image_std or getattr(model.visual, 'image_std', None)
preprocess = image_transform(
model.visual.image_size,
is_train=False,
mean=image_mean,
std=image_std,
)
return model, preprocessfactory.py的create_model()函数同样重要 ,这个函数的设计允许用户灵活地创建和定制模型,包括选择不同的预训练权重来源、设置运行精度、移动设备、以及加载预处理配置等。代码过长就不展示了。
创建IRSDE模型
模型结构相关暂时还没看懂
sde = util.IRSDE(max_sigma=opt["sde"]["max_sigma"], T=opt["sde"]["T"], schedule=opt["sde"]["schedule"],
eps=opt["sde"]["eps"], device=device)
sde.set_model(model.model)相关解读也可以移步 IR-SDE类创建过程![]() http://t.csdnimg.cn/thzXE
http://t.csdnimg.cn/thzXE
第一行,根据读取的opt字典参数初始化IRSDE模型。
第二行,model 是 DenoisingModel 类的一个实例,而 model.model 指的是 DenoisingModel 实例中的 model 属性,即 self.model。这个属性是一个神经网络模型。在networks.py可以看到相关结构。将 DenoisingModel 实例中的 self.model 赋值给IRSDE 的 model 属性。
3.图像预处理:
import numpy as np
import torch
from PIL import Image
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize, InterpolationMode
def clip_transform(np_image, resolution=224):
# 这一行定义了一个名为clip_transform的函数,它接受两个参数:np_image(一个NumPy数组格式的图像)和resolution(一个可选参数,默认值为224,表示图像的目标分辨率)。
pil_image = Image.fromarray((np_image * 255).astype(np.uint8))
# 这一行将NumPy数组格式的图像转换为PIL(Python Imaging Library)图像。首先,将NumPy数组中的像素值乘以255,然后转换为无符号的8位整数格式,这是因为图像的像素值通常在0到255的范围内。
return Compose([
# 这一行开始定义一个转换流程,Compose是来自albumentations库的一个函数,用于组合多个图像转换操作。
Resize(resolution, interpolation=InterpolationMode.BICUBIC),
# 这一行使用Resize操作来调整图像大小到指定的分辨率。interpolation=InterpolationMode.BICUBIC指定了使用双三次插值方法来调整图像大小,这是一种高质量的插值算法。
CenterCrop(resolution),
# 这一行应用CenterCrop操作,将调整大小后的图像进行中心裁剪,以确保图像的尺寸严格等于指定的分辨率
ToTensor(),
# 这一行使用ToTensor操作将PIL图像转换为PyTorch张量。这是为了使图像能够被深度学习模型处理。
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))])(pil_image)
# 为什么参数这样设置还不知道
# 这一行应用Normalize操作,对图像的每个通道进行标准化。它使用两组参数,分别对应图像的均值和标准差。这些参数通常是根据预训练模型的要求来设置的。
# 然后,将转换流程应用到PIL图像上,并返回处理后的张量。该标准化参数是该预训练模型VITB32 process中的默认参数,,
4.图像复原:
def restore(image):
# 定义了一个名为restore的函数,它接受一个参数:image(一个图像张量)。
image = image / 255.
# 这一行将输入的图像张量的像素值归一化到0到1的范围内。
img4clip = clip_transform(image).unsqueeze(0).to(device)
#调用刚刚定义的预处理函数clip_transform函数来处理图像,然后使用unsqueeze(0)在张量前面增加一个维度(通常是为了添加一个批次维度),最后将处理后的张量发送到指定的设备(如GPU)。
with torch.no_grad(), torch.cuda.amp.autocast():
# 这一行开始一个上下文管理器,用于关闭梯度计算(torch.no_grad()),这对于推理阶段是必要的,因为我们不需要计算反向传播。
# torch.cuda.amp.autocast()用于自动将操作转换为半精度浮点数,这可以提高计算速度并减少内存使用
image_context, degra_context = clip_model.encode_image(img4clip, control=True)
# 这一行使用CLIP模型的encode_image方法来编码处理后的图像,生成图像的上下文信息。control=True可能意味着模型在编码时使用了某种控制机制。
image_context = image_context.float()
# 这一行将图像上下文张量转换为浮点数类型。
degra_context = degra_context.float()
# 同上将degra_context张量转换为浮点数类型
LQ_tensor = torch.tensor(image, dtype=torch.float32).permute(2, 0, 1).unsqueeze(0)
# 这一行根据输入的image创建了一个低质量(LQ)图像的张量副本,并调整了维度顺序(从HWC到CHW),这是大多数深度学习模型期望的格式,并在前面增加了一个批次维度。
noisy_tensor = sde.noise_state(LQ_tensor)
# 这一行使用一个名为sde的noise_state方法来向 低质量图像张量添加噪声。??
model.feed_data(noisy_tensor, LQ_tensor, text_context=degra_context, image_context=image_context)
# 这一行将带有噪声的图像和原始低质量图像以及上下文信息传递给一个模型,这个模型可能是用于图像恢复的深度学习模型。
model.test(sde)
# 这一行调用模型的test方法,?
visuals = model.get_current_visuals(need_GT=False)
# 这一行从模型中获取当前的可视化结果,need_GT=False可能意味着不需要真实的高质量图像作为参考
output = util.tensor2img(visuals["Output"].squeeze())
# 这一行将模型输出的恢复图像张量转换为PIL图像格式。visuals["Output"]获取了输出图像的张量,squeeze()方法移除了所有单维度的批次维度。
return output[:, :, [2, 1, 0]]
# 这一行将图像的通道顺序从RGB转换为BGR,这是大多数图像处理库和显示设备使用的格式,并返回最终的恢复图像。5.Gradio界面 :
import os
import gradio as gr
examples = [os.path.join(os.path.dirname(__file__), f"images/{i}.jpg") for i in range(1, 11)]
# 这一行创建了一个包含10个示例图像路径的列表。这些图像被用于Gradio界面中的示例展示。
interface = gr.Interface(fn=restore, inputs="image", outputs="image", title="基于DA-CLIP的图像修复", examples=examples)
# 这一行使用Gradio库创建了一个界面对象。fn=restore指定了当用户上传图像时应该调用的函数,inputs="image"和outputs="image"定义了输入和输出类型,title设置了界面的标题,examples提供了界面中的示例图像。
interface.launch(share=True)
# 这一行启动了Gradio界面,使得用户可以通过网络浏览器与之交互。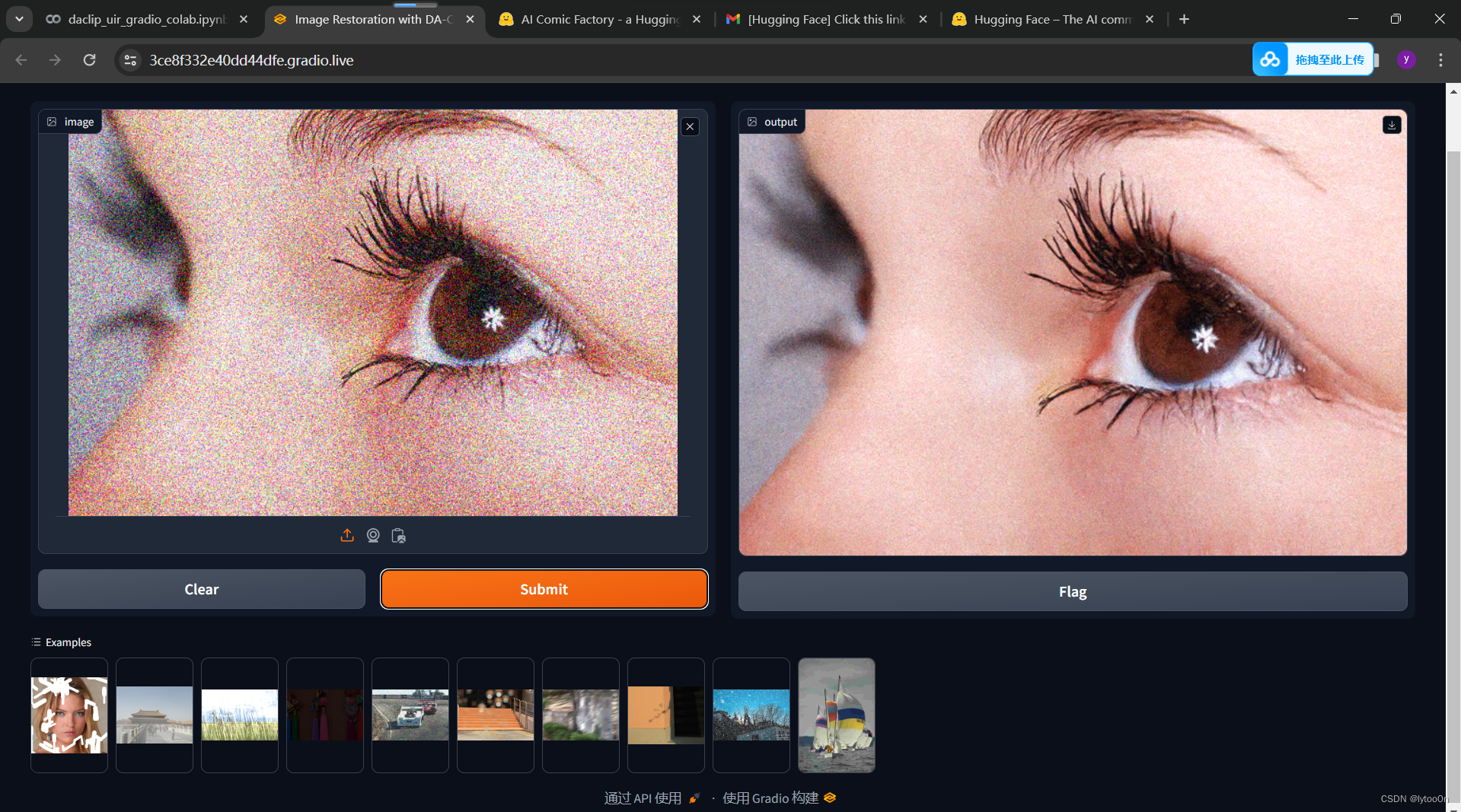















 4449
4449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









