







 本文介绍了一种基于CLIP的模型DA-CLIP,通过训练解决图像纹理识别问题,特别针对十种退化类型进行优化。该模型能控制图像编码器,提高对退化类型如运动模糊、低光照等的识别精度。代码示例展示了如何使用DA-CLIP进行图像退化类型检测,尽管在某些情况下结果接近100%,但仍存在改进空间,尤其是在处理真实手机图像和复杂噪声场景时。
本文介绍了一种基于CLIP的模型DA-CLIP,通过训练解决图像纹理识别问题,特别针对十种退化类型进行优化。该模型能控制图像编码器,提高对退化类型如运动模糊、低光照等的识别精度。代码示例展示了如何使用DA-CLIP进行图像退化类型检测,尽管在某些情况下结果接近100%,但仍存在改进空间,尤其是在处理真实手机图像和复杂噪声场景时。
背景
在CLIP基础上微调而来,使用图像控制器编码生成退化类型embedding并在训练中对图像编码器进行控制。针对十种退化类型进行了训练。
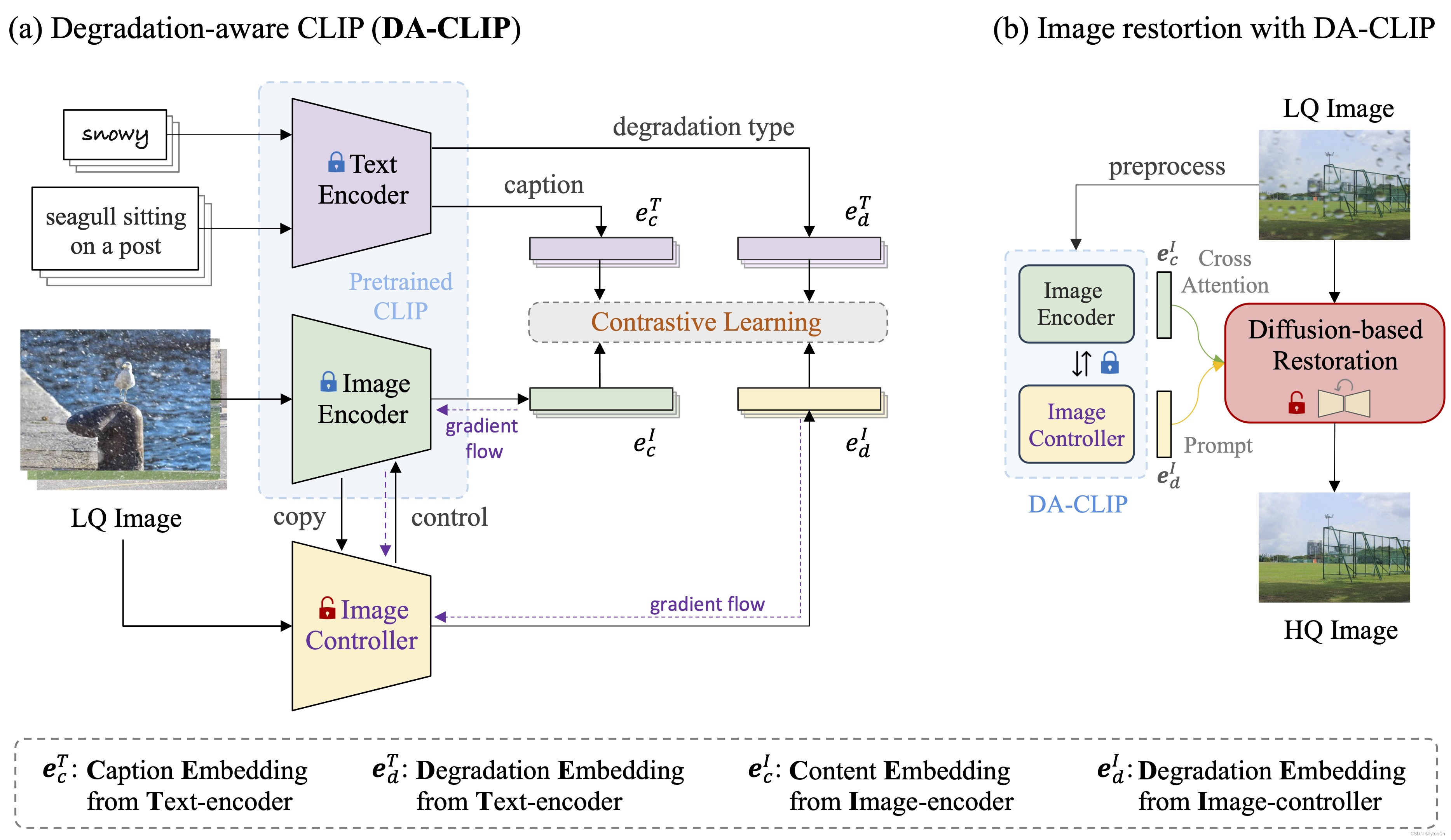
解决CLIP模型在图像纹理等层面无法针对退化类型识别或识别率较低的问题。
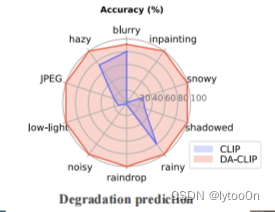
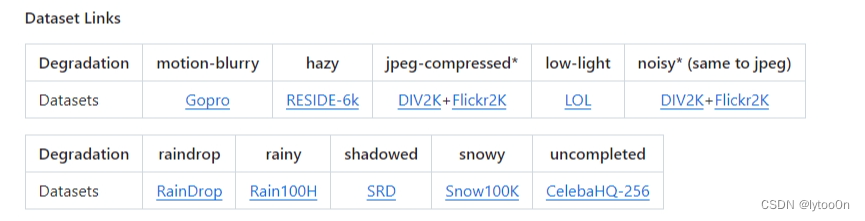
训练数据集情况
 GitHub有对应数据集连接
GitHub有对应数据集连接
完整代码
项目没有提供退化类型识别准确率计算的代码。只提供了上面的雷达图对比。毕竟这只是复原处理的一小部分。
以下代码是缺少img复原处理的版本。这份代码是在app.py的基础上做了退化类型检测功能,并去掉图像复原处理过程。GitHub - Algolzw/daclip-uir: [ICLR 2024] Controlling Vision-Language Models for Universal Image Restoration. 5th place in the NTIRE 2024 Restore Any Image Model in the Wild Challenge.[ICLR 2024] Controlling Vision-Language Models for Universal Image Restoration. 5th place in the NTIRE 2024 Restore Any Image Model in the Wild Challenge. - Algolzw/daclip-uir![]() https://github.com/Algolzw/daclip-uir
https://github.com/Algolzw/daclip-uir
下载项目、预训练模型权重、安装环境后将该份代码复制到app.py同一目录下运行即可
# 缺少img处理的版本
# 这份代码是在app的基础上做了daclip退化类型检测功能,并去掉图像复原处理过程
import os
import gradio as gr
import argparse
import numpy as np
import torch
from PIL import Image
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize, InterpolationMode
import options as option
from models import create_model
import open_clip
parser = argparse.ArgumentParser()
# ArgumentParser对象是argparse模块的核心,它提供了一个接口来添加参数(arguments)和选项(options)到你的程序
parser.add_argument("-opt", type=str, default='options/test.yml', help="Path to options YMAL file.")
# 添加一个命令行选项,这个选项被命名为-opt,它是一个接受字符串类型的参数
opt = option.parse(parser.parse_args().opt, is_train=False)
# 调用options.py中的parse方法,接受两个参数,args.opt是通过 argparse 解析器得到的选项值,采用刚刚定义的默认YMAL地址
opt = option.dict_to_nonedict(opt)
# convert to NoneDict, which return None for missing key.
# load pretrained model by default
model = create_model(opt)
# 在models的init.py中的create_model()
device = model.device
# 根据配置决定CUDA还是CPU
clip_model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=opt['path']['daclip'])
clip_model = clip_model.to(device)
def clip_transform(np_image, resolution=224):
# 这一行定义了一个名为clip_transform的函数,它接受两个参数:np_image(一个NumPy数组格式的图像)和resolution(一个可选参数,默认值为224,表示图像的目标分辨率)。
pil_image = Image.fromarray((np_image * 255).astype(np.uint8))
# 这一行将NumPy数组格式的图像转换为PIL(Python Imaging Library)图像。首先,将NumPy数组中的像素值乘以255,然后转换为无符号的8位整数格式,这是因为图像的像素值通常在0到255的范围内。
return Compose([
# 来自torchvision.transforms
# 这一行开始定义一个转换流程,Compose是来自albumentations库的一个函数,用于组合多个图像转换操作。
Resize(resolution, interpolation=InterpolationMode.BICUBIC),
# 这一行使用Resize操作来调整图像大小到指定的分辨率。interpolation=InterpolationMode.BICUBIC指定了使用双三次插值方法来调整图像大小,这是一种高质量的插值算法。
CenterCrop(resolution),
# 这一行应用CenterCrop操作,将调整大小后的图像进行中心裁剪,以确保图像的尺寸严格等于指定的分辨率
ToTensor(),
# 这一行使用ToTensor操作将PIL图像转换为PyTorch张量。这是为了使图像能够被深度学习模型处理。
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))])(pil_image)
# 这一行应用Normalize操作,对图像的每个通道进行标准化。它使用两组参数,分别对应图像的均值和标准差。这些参数通常是根据预训练模型的要求来设置的。
# 然后,将转换流程应用到PIL图像上,并返回处理后的张量。
examples = [os.path.join(os.path.dirname(__file__), f"images/{i}.jpg") for i in range(1, 11)]
degradations = [
"运动模糊", "有雾", "JPEG压缩伪影", "低光照", "噪声", "雨滴", "多雨的", "阴影遮挡的", "多雪的", "遮挡修复"
]
text_tokens = ['motion-blurry', 'hazy', 'jpeg-compressed', 'low-light', 'noisy', 'raindrop', 'rainy', 'shadowed',
'snowy', 'uncompleted']
text = open_clip.tokenize(text_tokens).to(device)
def detect(image):
image = image / 255.
# 这一行将输入的图像张量的像素值归一化到0到1的范围内。
img4clip = clip_transform(image).unsqueeze(0).to(device)
if image is None:
pass
else:
# 计算daclip识别结果
with torch.no_grad(), torch.cuda.amp.autocast():
image_features, degra_features = clip_model.encode_image(img4clip, control=True)
# degra_features = clip_model.encode_image(img4clip, control=False)
# control=True启动图像控制器,不设置只有clip图像编码器
text_features = clip_model.encode_text(text)
# normalized features
degra_features = degra_features / degra_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = clip_model.logit_scale.exp()
logits_per_image = logit_scale * degra_features @ text_features.t()
# ...(省略之前的代码)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
degradation_probabilities = {degradation: round(prob, 3) for degradation, prob in
zip(degradations, probs[0].flatten())}
print(degradation_probabilities)
# 返回恢复后的图像和输入的退化类型。
return degradation_probabilities
interface = gr.Interface(
fn=detect, # 要调用的函数
inputs=[gr.Image(label="输入图像")]
,
outputs=gr.Label(label="退化类型概率"),
title="DA-CLIP的图像退化识别" # 界面标题
, examples=examples
)
interface.launch()
# 修改为原图输出,只求退化类型
代码思路
- 设置命令行参数:通过
argparse库设置命令行参数,用于指定配置文件的路径。 - 加载预训练模型:根据提供的配置文件加载预训练的DA-CLIP模型。
- 图像预处理:定义
clip_transform函数,用于将NumPy数组格式的图像转换为适合模型输入的格式。 - 定义退化类型列表:创建一个包含所有可能退化类型的列表。
- 模型推理:在
detect函数中,对输入图像进行必要的预处理,然后使用DA-CLIP模型进行推理,计算每个退化类型的概率。 - 格式化输出:将模型输出的概率转换为字典格式,并选择概率最高的退化类型。
- Gradio界面:使用Gradio库创建一个界面,用户可以通过它上传图像并获取退化类型的概率。
图像编码模型处理过程:
clip_model.encode_image也可设置control为False进行CLIP的分类演示测试。
-
模型编码 (
encode_image和encode_text方法): 经过预处理的图像被送入模型进行特征提取。在DA-CLIP模型中,encode_image方法用于从图像中提取视觉特征,而encode_text方法用于提取文本特征。这些特征向量是高维空间中的点,它们编码了输入数据的关键信息。 -
特征归一化: 为了提高计算效率和模型性能,通常会对提取的特征进行归一化处理。在代码中,使用
norm方法对图像特征和文本特征进行L2归一化,使得每个特征向量的长度为1。 -
相似度计算 (
logits_per_image计算): 模型使用特征向量来计算图像与每个退化类型之间的相似度。在DA-CLIP模型中,这通常是通过计算特征向量之间的点积(即内积)来实现的。logit_scale是一个可学习的参数,用于调整相似度得分的尺度。 -
概率计算 (
softmax函数): 得到相似度得分后,需要将它们转换成概率分布。softmax函数可以将任意实数值向量转换成概率分布,使得向量中所有元素的和为1。这样,每个得分就表示了图像属于某个特定退化类型的概率。
运行演示
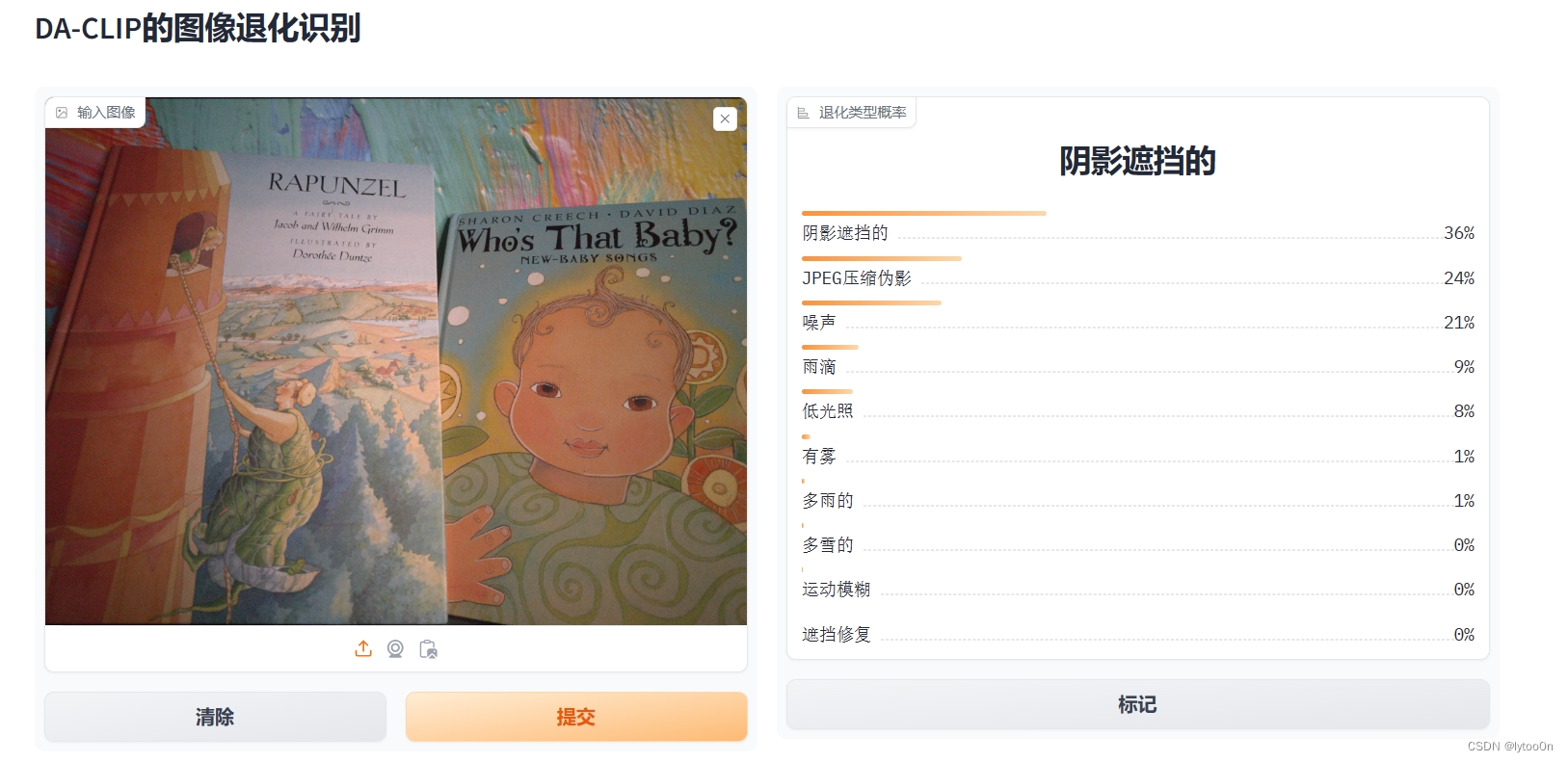
上传图像,展示退化类型识别结果百分比。后台提供三位小数计算结果
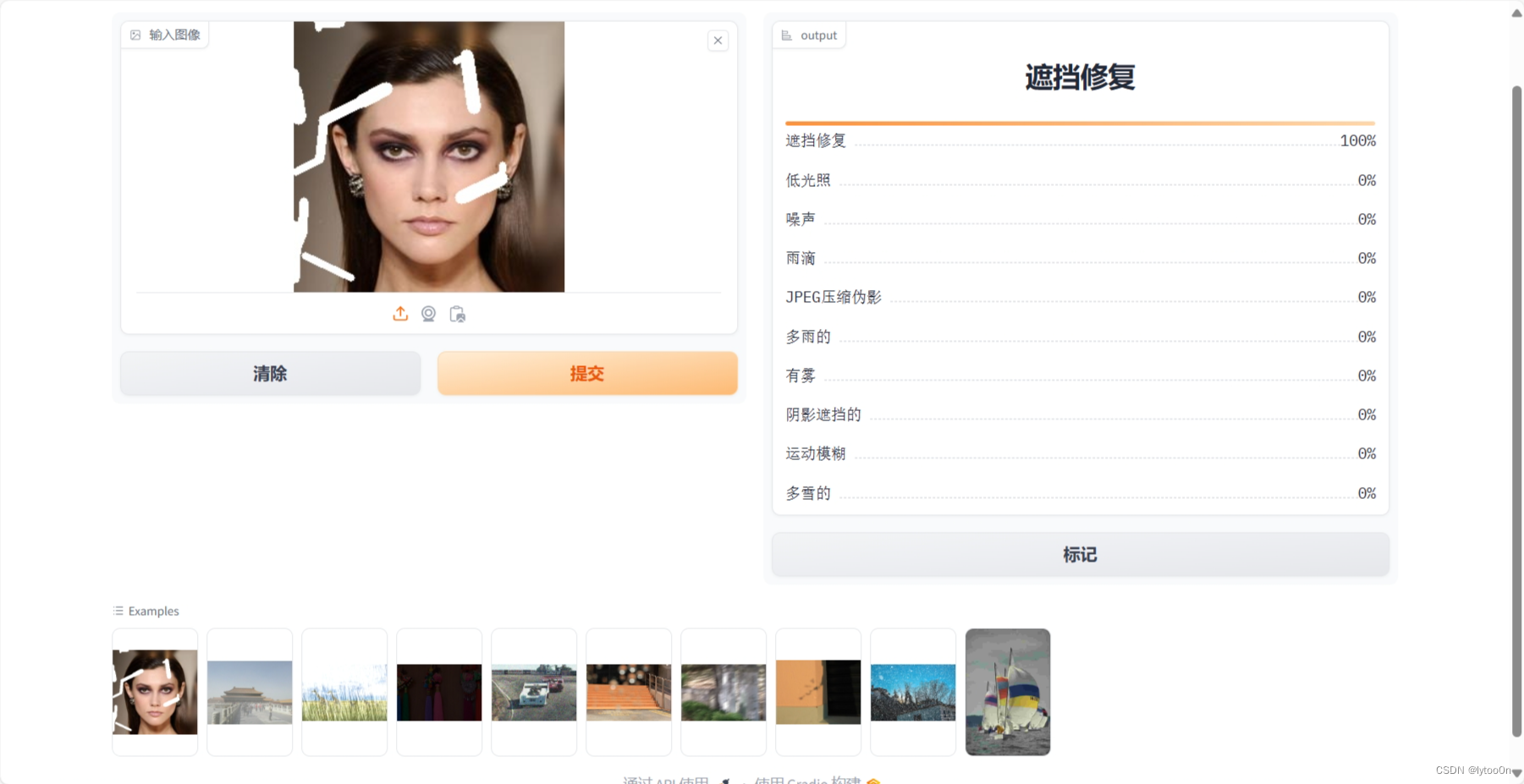

- 比较难绷的是example计算全为近100% ,所以是十边形战士?没啥精力搞十个数据集测试,感兴趣的同学可以去了解一下
- readme提供的LQ_image其实是训练集、测试集的一部分计算出来也全是100%
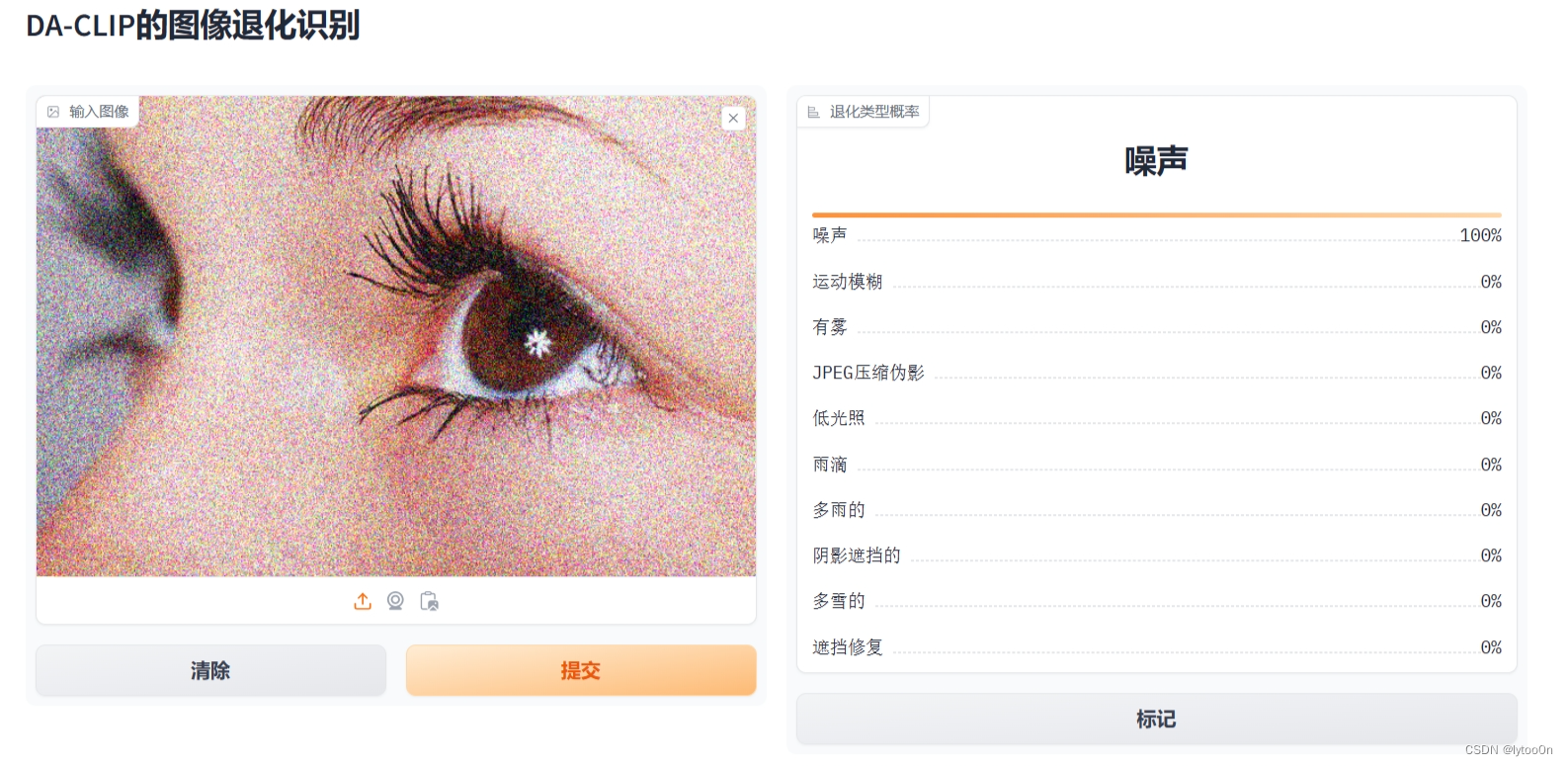
- 合成噪声比较明显的话也很好识别
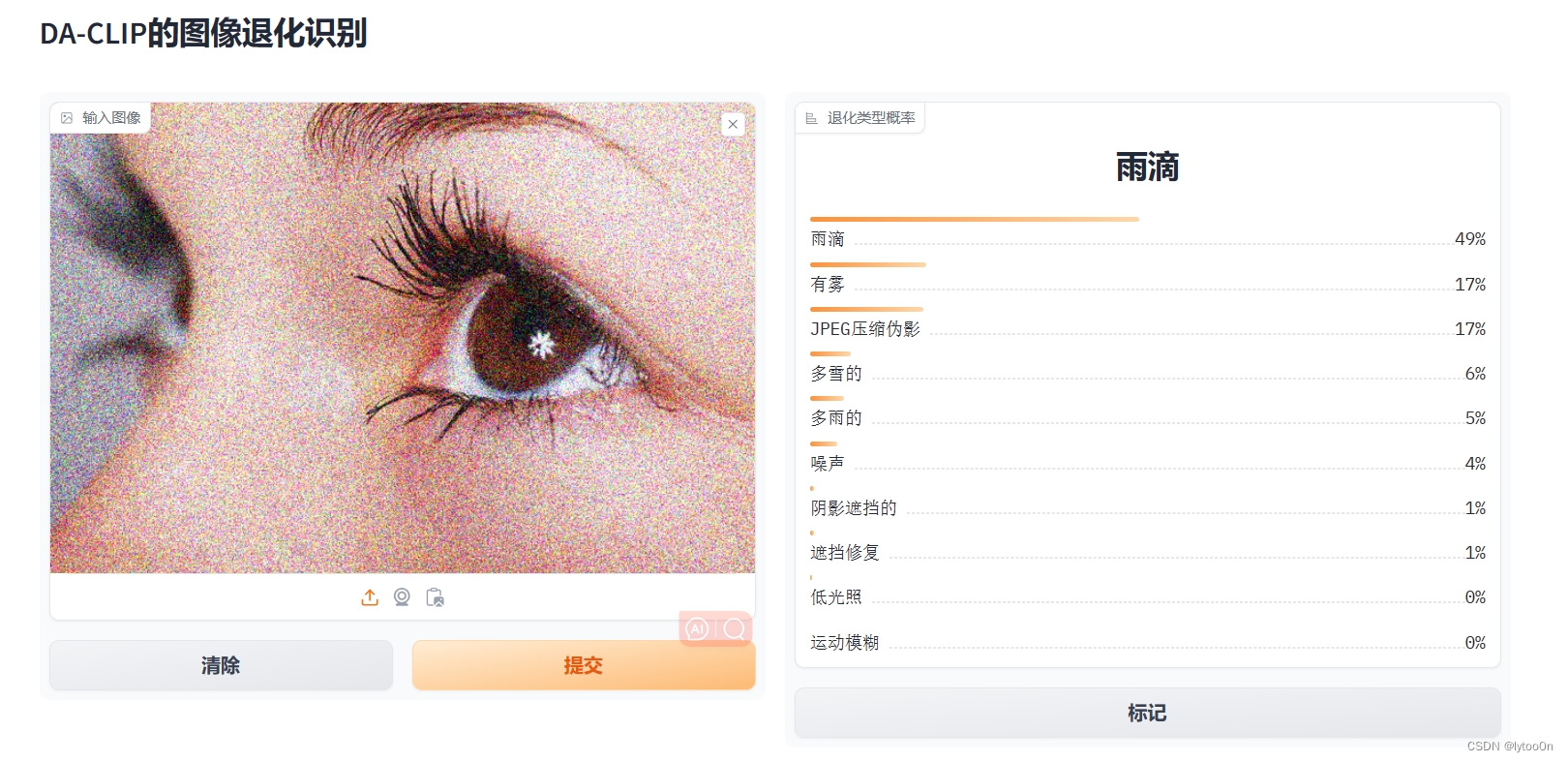
- 可以改一个DACLIP和CLIP结果对比的,我就先不搞了,可以复制一份搞两个网页,不过很吃内存hh
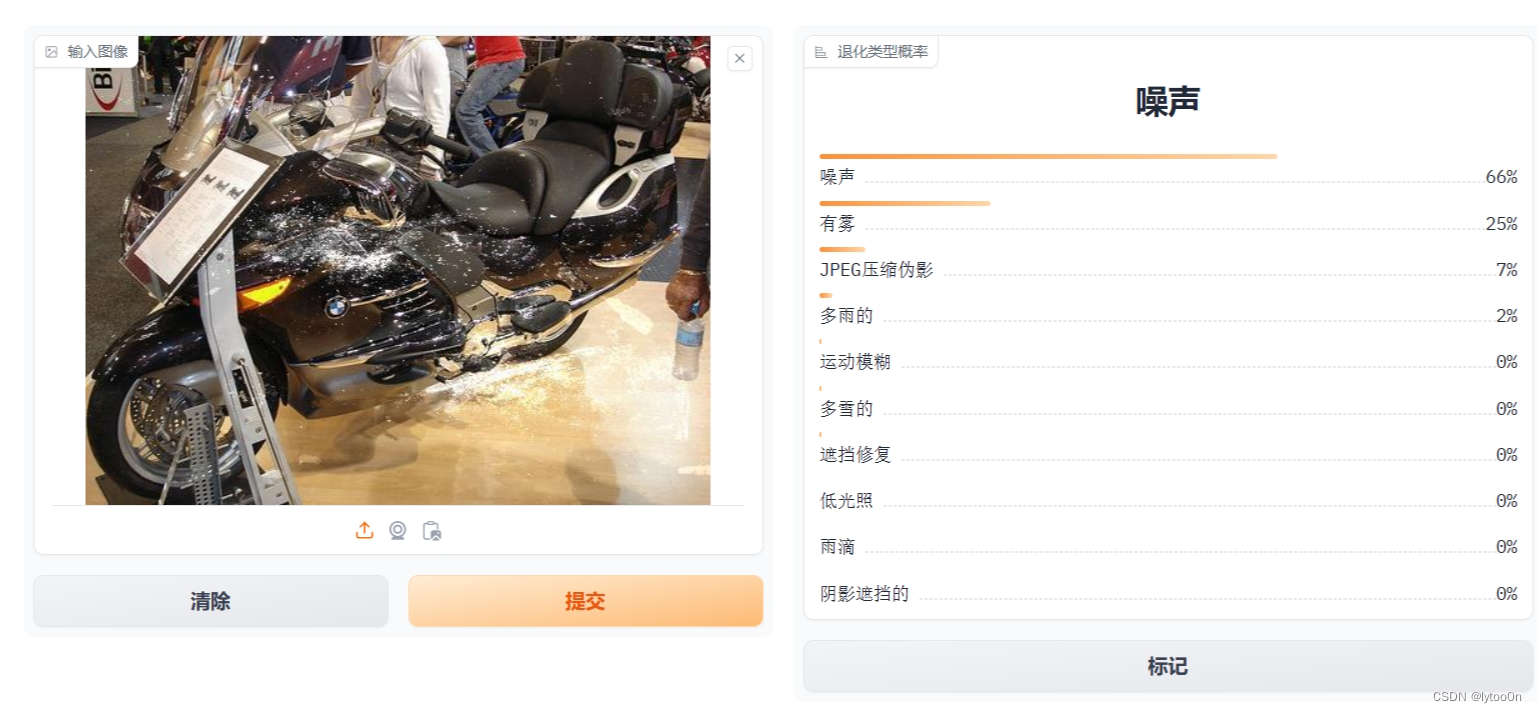
- 上面是DA-CLIP,下面修改了control是CLIP的计算结果
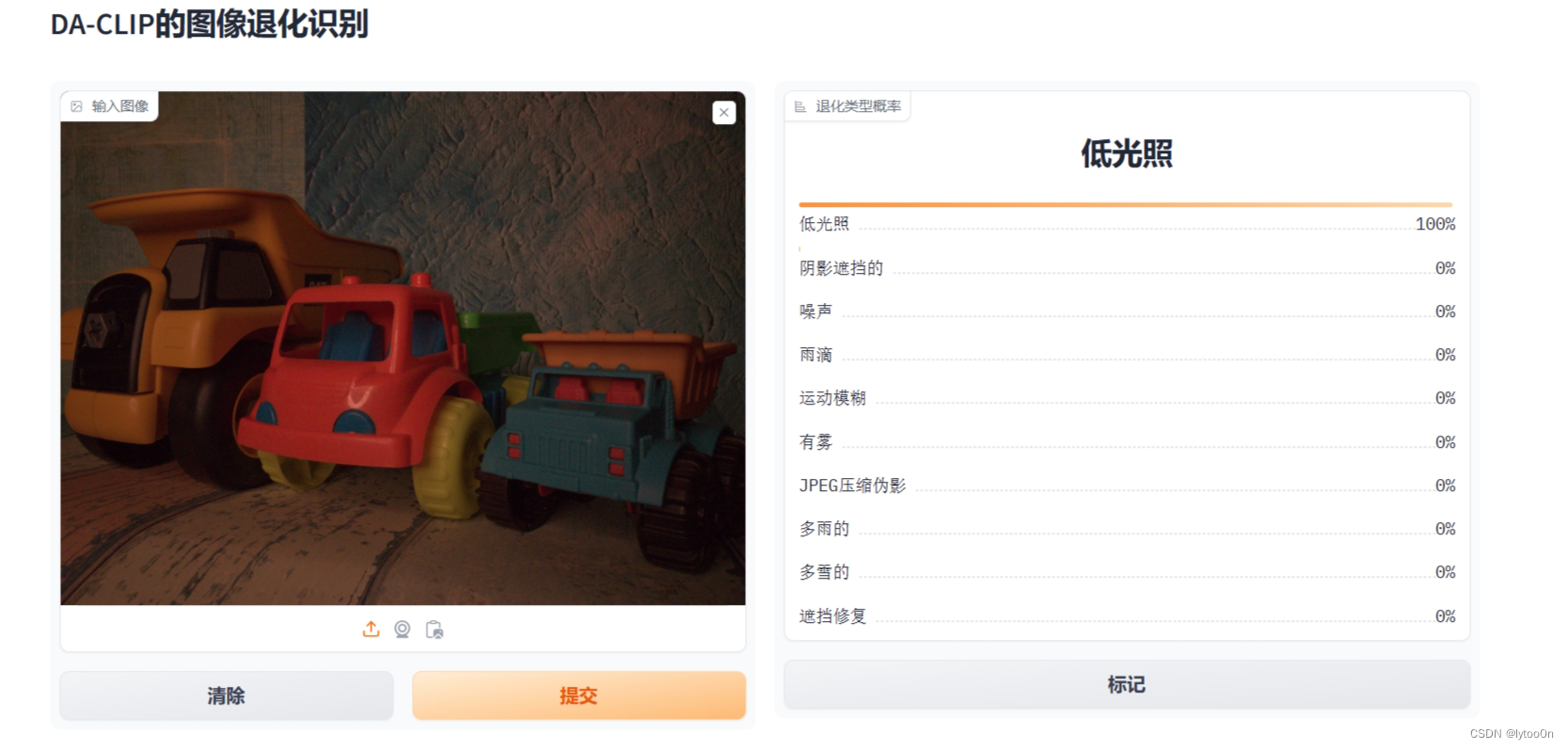
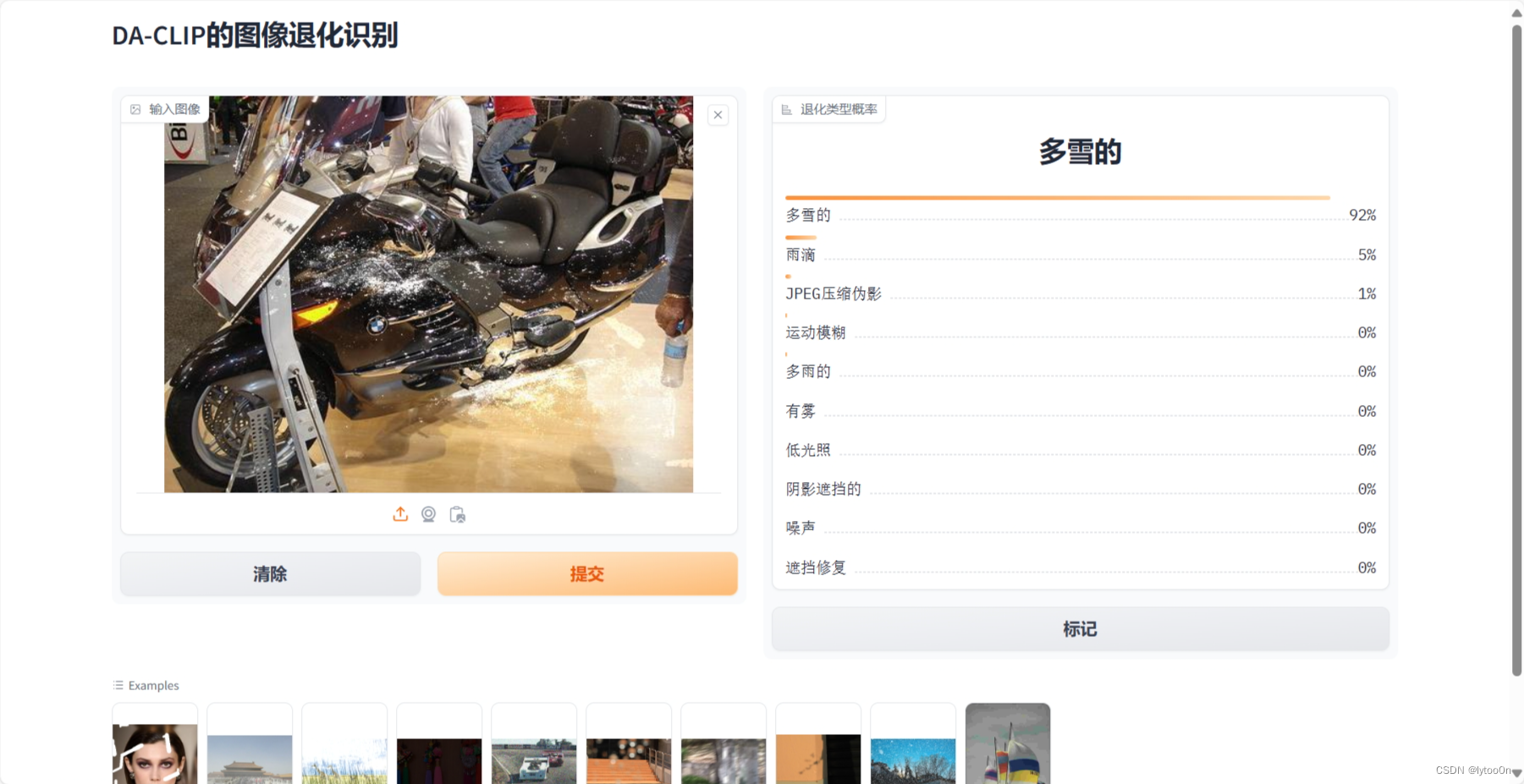
- SIDD智能手机图像去噪数据集的sRGB噪声图
- 对于真实手机拍摄图像的识别效果还不是很好,这个计算是不是有点绝对了,,虽然低光照是一个很明显的问题
- 可能这也导致不同数据集上测试这个模型效果不够好的原因,比如是想做去噪的但是复原模型却输入了低光照的退化嵌入
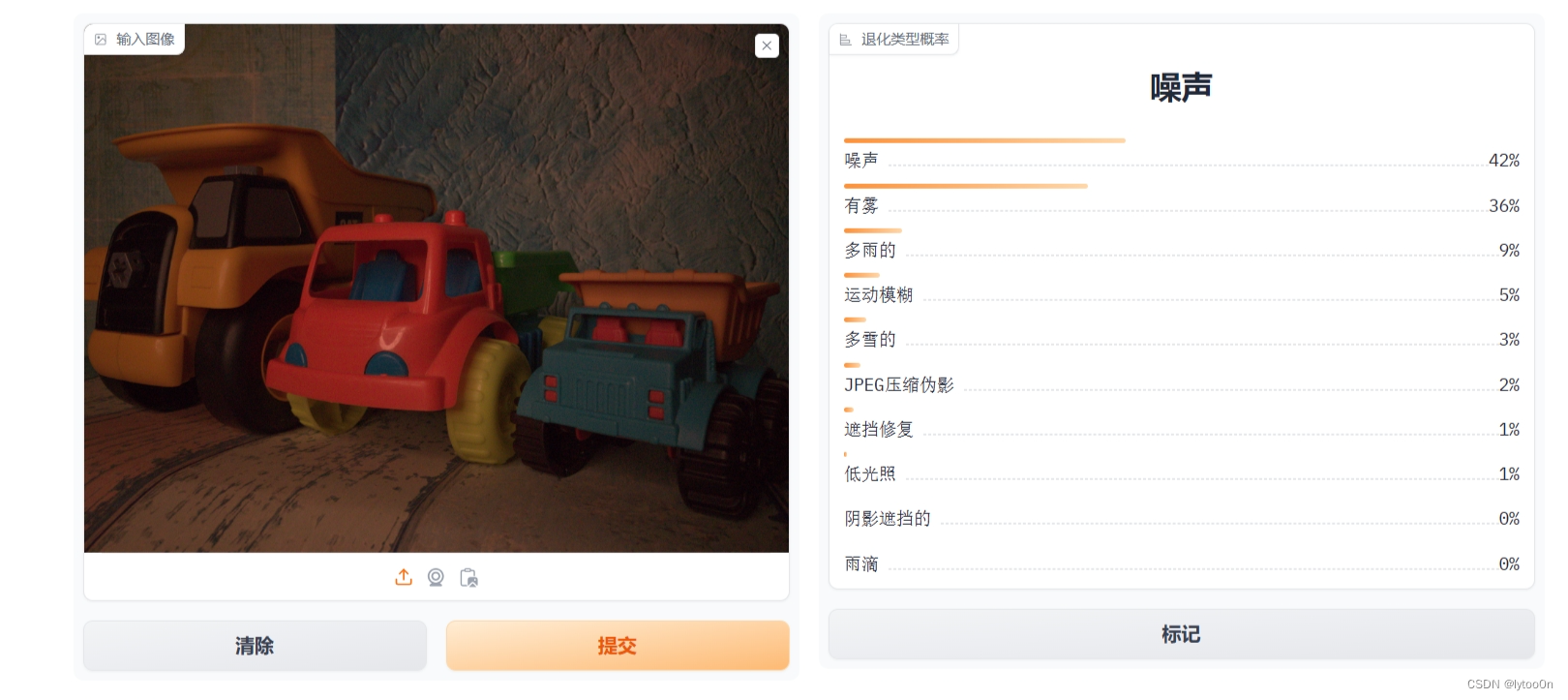 CLIP有时候确实感觉在胡扯,比如下面这图识别成rainy..
CLIP有时候确实感觉在胡扯,比如下面这图识别成rainy..
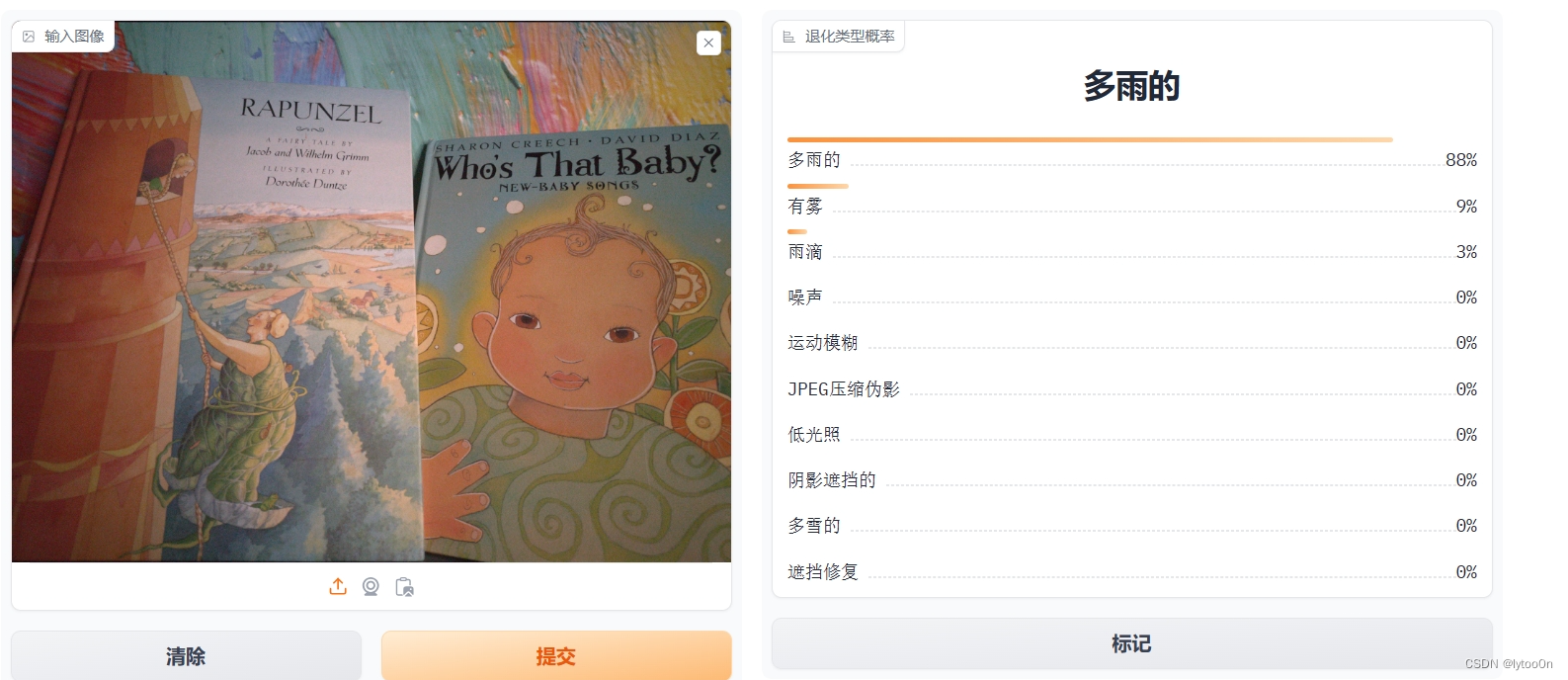
- old photo数据集,没翻论文看经过了什么处理合成的LQ图像,直观看比较接近snowy也算合理

CLIP的结果















 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









