






Coordinate Attention for Efficient Mobile Network Design
Abstract
最近关于移动网络设计的研究已经证明了通道注意力(例如,挤压和激励注意力)对于提升模型性能的显着有效性,但它们通常忽略了位置信息,这对于生成 空间选择性特征图 很重要。在本文中,我们通过将位置信息嵌入到通道注意力中,提出了一种新的移动网络注意力机制,我们称之为"坐标注意力"。与通过 2D 全局池化将特征张量转换为单个特征向量的通道注意力不同,坐标注意力将通道注意力分解为两个一维特征编码过程,分别沿两个空间方向聚合特征。通过这种方式,可以沿一个空间方向捕获远程依赖性,同时可以沿另一个空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的注意力图,这些注意力图可以互补地应用于输入特征图以增强感兴趣对象的表示。我们的坐标注意力很简单,可以灵活地插入经典移动网络,例如MobileNetV2、MobileNeXt 和 EfficientNet,几乎没有计算开销。大量实验表明,我们的协调注意力不仅有利于 ImageNet 分类,而且更有趣的是,在下游任务中表现更好,例如对象检测和语义分割。
代码可在https://github.com/Andrew-Qibin/CoordAttention获得。
1. Introduction
用于告诉模型"什么"和"哪里"参加的注意机制已得到广泛研究 [47、29] 并被广泛部署以提高现代深度神经网络的性能 [18、44、3、25, 10, 14]。然而,它们在移动网络(模型大小有限)中的应用明显落后于大型网络[36, 13, 46]。这主要是因为移动网络无法承受大多数注意力机制带来的计算开销。
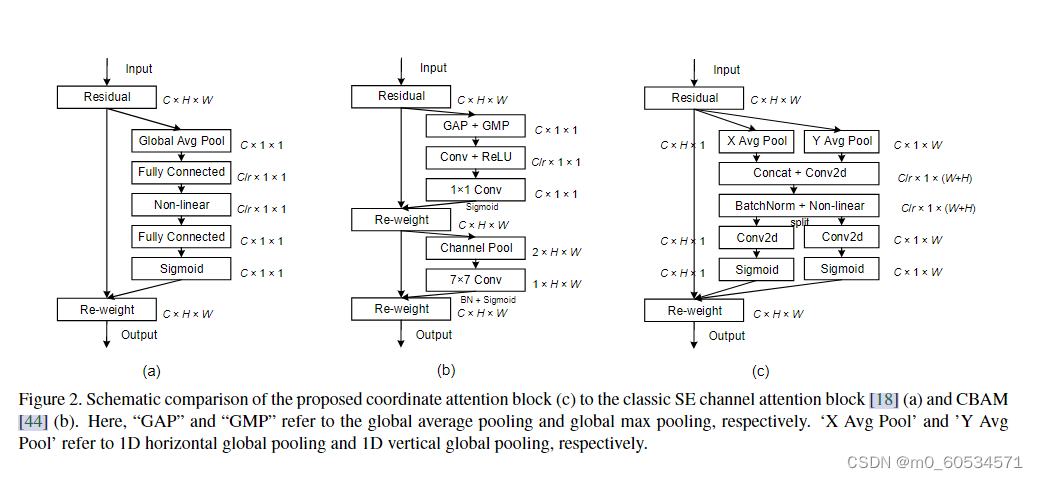
考虑到移动网络计算能力的限制,迄今为止,最流行的移动网络注意机制仍然是挤压和引用(SE)注意[18]。它在2D全局池的帮助下计算通道注意力,并以相当低的计算成本提供了显著的性能提升。然而,SE注意只考虑了通道间信息的编码,而忽略了位置信息的重要性,位置信息是视觉任务[42]中捕获物体结构的关键。后来的工作,如BAM[30]和CBAM[44],试图通过降低输入张量的通道维数来利用位置信息,然后使用卷积计算空间注意力,如图2(b)所示。然而,卷积只能捕获局部关系,但无法建模对视觉任务至关重要的长期依赖关系[48,14]。
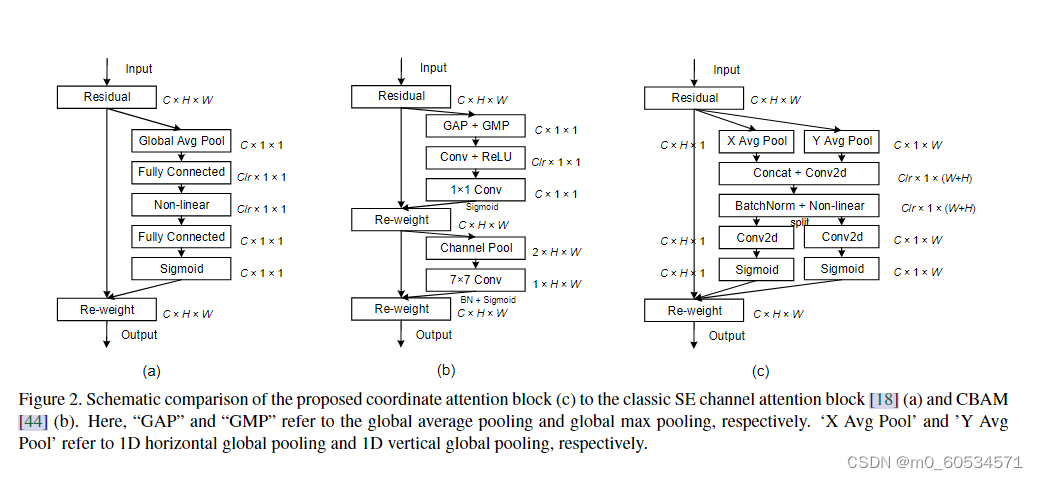
图2。本文提出的坐标注意块©与经典的SE通道注意块18和CBAM [44] (b)的对比图。这里的“GAP”和“GMP”分别表示全局平均池和全局最大池。“X Avg Pool”和“Y Avg Pool”分别是指一维水平全局池化和一维垂直全局池化。
在本文中,我们提出了一种新颖而有效的注意机制,通过将位置信息嵌入到信道注意中,使移动网络能够在大区域内进行关注,同时避免产生大量的计算开销。为了缓解二维全局池化造成的位置信息损失,将信道注意分解为两个并行的一维特征编码过程,有效地整合了空间坐标将信息放入生成的注意力图中。具体来说,我们的方法利用两个一维全局池化操作分别将垂直和水平方向的输入特征聚合到两个独立的方向感知特征图中。然后将这两个嵌入特定方向信息的特征图分别编码为两个注意力图,每个注意力图捕获输入特征图沿一个空间方向的长期依赖性。因此,位置信息可以保存在生成的注意力图中。然后将两个注意力图通过乘法应用于输入特征图,以强调感兴趣的表示。我们将提出的注意方法命名为坐标注意,因为它的操作区分空间方向(即坐标)并生成坐标感知注意图。
我们的协调注意力具有以下优势。
首先,它不仅捕获了跨通道的信息,还捕获了方向感知和位置敏感的信息,这有助于模型更准确地定位和识别感兴趣的对象。
其次,我们的方法灵活轻便,可以轻松插入移动网络的经典构建块,例如 MobileNetV2 [34] 中提出的倒置残差块和 MobileNeXt [49] 中提出的沙漏块,通过强调信息表示来增强功能。
第三,作为预训练模型,我们的协调注意力可以为移动网络的下游任务带来显着的性能提升,特别是对于那些具有密集预测(例如语义分割)的任务,我们将在实验部分展示这一点。
为了证明所提出的方法相对于以前的移动网络注意方法的优势,我们在 ImageNet 分类 [33] 和流行的下游任务(包括对象检测和语义分割)中进行了广泛的实验。通过相当数量的可学习参数和计算,我们的网络在 ImageNet 上的 top-1 分类精度中实现了 0.8% 的性能增益。在对象检测和语义分割方面,与具有其他注意机制的模型相比,我们也观察到显着改进,如图 1 所示。我们希望我们简单高效的设计能够促进移动网络注意机制的发展未来。
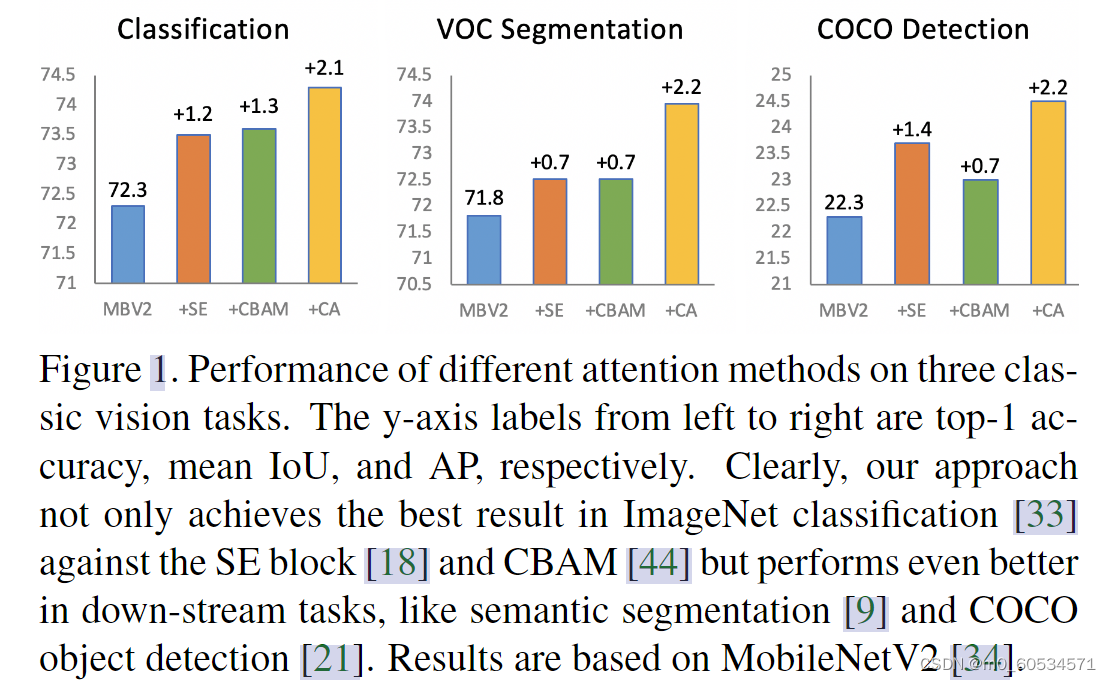
图1。不同注意方法在三种经典视觉任务上的表现。y轴标签从左到右分别为top-1精度、mean IoU和AP。显然,我们的方法不仅在ImageNet分类[33]中相对于SE块[18]和CBAM[44]中获得了最好的结果,而且在下游任务中表现更好,如语义分割[9]和COCO对象检测[21]。结果基于MobileNetV2[34]。
2. Related Work
在本节中,我们将对本文进行简要的文献回顾,包括先前关于高效网络架构设计和注意力或非本地模型的工作。
2.1. Mobile Network Architectures
最近最先进的移动网络主要基于深度可分离卷积[16]和倒置残差块[34]。 HBONet [20]介绍每个倒置残差块内的下采样操作,用于对代表性空间信息进行建模。 ShuffleNetV2 [27] 在反转残差块之前和之后使用通道拆分模块和通道洗牌模块。后来,MobileNetV3 [15] 结合神经架构搜索算法 [50]来搜索最优激活函数和不同深度的倒置残差块的扩展率。此外,MixNet [39]、EfficientNet [38] 和ProxylessNAS [2] 也采用不同的搜索策略来搜索深度可分离卷积或标量的最佳内核大小,以在扩展比方面控制网络权重,在- 放置分辨率、网络深度和宽度。最近,周等人。 [49] 重新考虑了利用深度可分离卷积的方式,并提出了采用经典移动网络瓶颈结构的MobileNeXt。
2.2. Attention Mechanisms
注意机制 [41, 40] 已被证明有助于各种计算机视觉任务,例如图像分类 [18, 17, 44, 1] 和图像分割[14, 19, 10]。 SENet [18] 是一个成功的例子,它简单地压缩每个 2D 特征图以有效地建立通道之间的相互依赖关系。 CBAM [44] 通过使用大尺寸内核的卷积引入空间信息编码,进一步推进了这一想法。后来的作品,如 GENet [17]、GALA [22]、AA [1] 和 TA[28],通过采用不同的空间注意力机制或设计高级注意力块来扩展这一想法。
非局部/自注意力网络最近非常流行,因为它们具有建立空间或通道注意力的能力。典型示例包括NLNet [43]、GC-Net [3]、A 2 Net [7]、SCNet [25]、GSoP-Net [11] 或 CC-Net [19],所有这些都利用了非本地机制捕捉不同类型的空间信息。然而,由于自注意力模块内部的计算量很大,它们通常被大型模型采用[13, 46],但不适用于移动网络。与这些利用昂贵且繁重的非局部或自注意力块的方法不同,我们的方法考虑了一种更有效的方法来捕获位置信息和通道关系,以增强移动网络的特征表示。通过将 2D 全局池化操作分解为两个一维编码过程,我们的方法比其他具有轻量级属性的注意力方法(例如 SENet [18]、CBAM [44] 和 TA [28])表现得更好。
最重要的部分
3. Coordinate Attention
坐标注意块可以看作是一个计算单元,旨在增强移动网络学习特征的表达能力。它可以采用任何中间特征张量 X = [x 1 , x 2 , . . . , x C ] ∈RC×H×W 作为输入并输出一个变换后的张量与 X 大小相同的增强表示 Y = [y,y,…,y]12C。为了清楚地描述所提出的坐标注意,我们首先重新审视在移动网络中广泛使用的 SE 注意力.
3.1. Revisit Squeeze-and-Excitation Attention
正如 [18] 中所证明的,标准卷积本身很难对通道关系进行建模。明确建立通道相互依赖性可以提高模型对信息通道的敏感性,这些信息通道对最终分类决策的贡献更大。此外,使用全局平均池化还可以帮助模型捕获全局信息,这是卷积所缺乏的。
在结构上,SE块可以分解为两个步骤:挤压和激励,分别用于全局信息嵌入和信道关系的自适应重新校准。给定输入 X,第 c 个通道的挤压步骤可以表示为
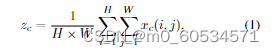
其中 zc 是与第 c 个通道关联的输出。输入 X 直接来自具有固定内核大小的卷积层,因此可以被视为局部描述符的集合。挤压操作使得收集全局信息成为可能。
第二步,激励,旨在完全捕获通道依赖性,可以表述为
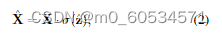
其中 ·指的是逐通道乘法,σ 是 sigmoid 函数,z^是由变换生成的结果

SE 块已广泛用于最近的移动网络 [18、4、38],并被证明是实现最先进性能的关键组件。然而,它只考虑通过建模通道关系来重新权衡每个通道的重要性,但忽略了位置信息,我们将在第 4 节中通过实验证明这对于生成空间选择性注意力图很重要。在下文中,我们介绍了一种新颖的注意力块,它同时考虑了通道间关系和位置信息。
3.2. Coordinate Attention Blocks
我们的坐标注意通过两个步骤使用精确的位置信息对通道关系和远程依赖性进行编码:坐标信息嵌入和坐标注意生成。所提出的坐标注意块的示意图可以在图 2 的右侧部分找到。在下文中,我们将对其进行详细描述。
3.2.1 Coordinate Information Embedding
全局池化常用于通道注意力以对全局空间信息进行编码,但它将全局空间信息压缩到通道描述符中,因此难以保留位置信息,而位置信息对于在视觉任务中捕获空间结构至关重要。为了鼓励注意力块使用精确的位置信息在空间上捕捉远程交互,我们分解了方程式中制定的全局池化。 (1)成对一维特征编码操作。具体来说,给定输入 X,我们使用池核 (H, 1) 或 (1, W) 的两个空间范围分别沿水平坐标和垂直坐标对每个通道进行编码。因此,高度为 h 的第 c 个通道的输出可以表示为

上述两个变换分别聚合了沿两个空间方向的特征,产生了一对方向感知特征图。这与产生单个特征向量的通道注意方法中的挤压操作(等式(1))有很大不同。这两个转换还允许我们的注意力块沿一个空间方向捕获远程依赖关系并沿另一个空间方向保留精确的位置信息,这有助于网络更准确地定位感兴趣的对象。
3.2.2 Coordinate Attention Generation
如上所述,Eqn。 (4)和Eqn。 (5) 启用全局接受域并编码精确的位置信息。为了利用由此产生的表达表示,我们提出了第二个转换,称为坐标注意生成。我们的设计参考了以下三个标准。首先,对于移动环境中的应用程序,新的转换应该尽可能简单和便宜。其次,它可以充分利用捕获的位置信息,从而准确突出感兴趣的区域。最后但并非最不重要的一点是,它还应该能够有效地捕获通道间关系,这在现有研究中已被证明是必不可少的 [18, 44]。
具体来说,给定等式生成的聚合特征图。 4和Eqn。 5,我们首先将它们连接起来,然后将它们发送到共享的 1 × 1 卷积变换函数 F 1 ,产生
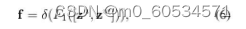

















 2504
2504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









