







(很早之前写的,比较懒,改天有时间会好好改一下)
自己想搜yolov5-7.0版本训练自己的数据集,很多都写的太乱了,这个是官网上,有需要的可以参考(后期会上传自己训练的过程和数据)
安装环境之前最好先把yolov5代码clone下来,打开requirements.txt文件对照着装环境
已经安装环境完成的查看自己的环境是否符合要求。
这个版本部分要求如下
# YOLOv5 🚀 requirements
# Usage: pip install -r requirements.txt
# Base ------------------------------------------------------------------------
gitpython
ipython # interactive notebook
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.1
Pillow>=7.1.2
psutil # system resources
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
thop>=0.1.1 # FLOPs computation
torch>=1.7.0 # see https://pytorch.org/get-started/locally (recommended)
torchvision>=0.8.1
tqdm>=4.64.0
# protobuf<=3.20.1 # https://github.com/ultralytics/yolov5/issues/8012
# Logging ---------------------------------------------------------------------
tensorboard>=2.4.1
# clearml>=1.2.0
# comet
# Plotting --------------------------------------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
原文https://github.com/ultralytics/yolov5/blob/master/segment/tutorial.ipynb
Clone GitHub repository, install dependencies and check PyTorch and GPU.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -qr requirements.txt # install
import torch
import utils
display = utils.notebook_init() # checks
YOLOv5 🚀 v7.0-2-gc9d47ae Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)Setup complete ✅ (2 CPUs, 12.7 GB RAM, 22.6/78.2 GB disk)
1. Predict(示例如下)
python segment/predict.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
这个代码是环境安装完成做测试用的
python segment/predict.py --weights yolov5s-seg.pt --img 640 --conf 0.25 --source data/images
#display.Image(filename='runs/predict-seg/exp/zidane.jpg', width=600)
segment/predict: weights=['yolov5s-seg.pt'], source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/predict-seg, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1, retina_masks=False YOLOv5 🚀 v7.0-2-gc9d47ae Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB) Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt to yolov5s-seg.pt... 100% 14.9M/14.9M [00:01<00:00, 12.0MB/s] Fusing layers... YOLOv5s-seg summary: 224 layers, 7611485 parameters, 0 gradients, 26.4 GFLOPs image 1/2 /content/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, 18.2ms image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 2 persons, 1 tie, 13.4ms Speed: 0.5ms pre-process, 15.8ms inference, 18.5ms NMS per image at shape (1, 3, 640, 640) Results saved to runs/predict-seg/exp
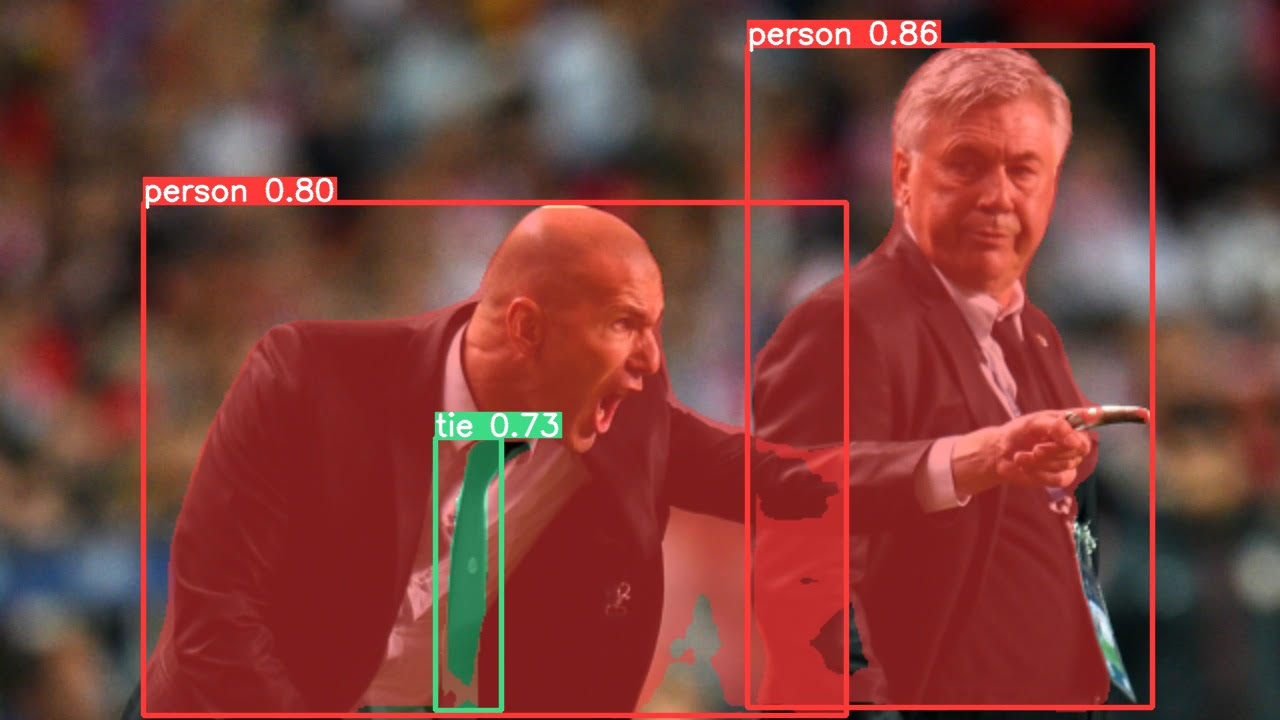
2. Validate(验证)
Validate a model's accuracy on the COCO dataset's val or test splits. Models are downloaded automatically from the latest YOLOv5 release. To show results by class use the --verbose flag.
(这是人家用CoCo上数据集做的验证,你可以用自己的)
# Download COCO val
bash data/scripts/get_coco.sh --val --segments # download (780M - 5000 images)
Downloading (这是下载的CoCo数据集链接)https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip ... Downloading http://images.cocodataset.org/zips/val2017.zip ...
######################################################################## 100.0% ######################################################################## 100.0%
# Validate YOLOv5s-seg on COCO val
python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 --half
segment/val: data=/content/yolov5/data/coco.yaml, weights=['yolov5s-seg.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=False, project=runs/val-seg, name=exp, exist_ok=False, half=True, dnn=False
YOLOv5 🚀 v7.0-2-gc9d47ae Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)
Fusing layers...
YOLOv5s-seg summary: 224 layers, 7611485 parameters, 0 gradients, 26.4 GFLOPs
val: Scanning /content/datasets/coco/val2017... 4952 images, 48 backgrounds, 0 corrupt: 100% 5000/5000 [00:03<00:00, 1361.31it/s]
val: New cache created: /content/datasets/coco/val2017.cache
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100% 157/157 [01:54<00:00, 1.37it/s]
all 5000 36335 0.673 0.517 0.566 0.373 0.672 0.49 0.532 0.319
Speed: 0.6ms pre-process, 4.4ms inference, 2.9ms NMS per image at shape (32, 3, 640, 640)
Results saved to runs/val-seg/exp
3. Train(数据集、训练、部署下面是流程图流程)

Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package
Train a YOLOv5s-seg model on the COCO128 dataset with --data coco128-seg.yaml, starting from pretrained --weights yolov5s-seg.pt, or from randomly initialized --weights '' --cfg yolov5s-seg.yaml.
- Pretrained Models are downloaded
automatically from the latest YOLOv5 release
- Datasets available for autodownload include: COCO, COCO128, VOC, Argoverse, VisDrone, GlobalWheat, xView, Objects365, SKU-110K.
- Training Results are saved to
runs/train-seg/with incrementing run directories, i.e.runs/train-seg/exp2,runs/train-seg/exp3etc.
A Mosaic Dataloader is used for training which combines 4 images into 1 mosaic.
Train on Custom Data with Roboflow 🌟 NEW
Roboflow enables you to easily organize, label, and prepare a high quality dataset with your own custom data. Roboflow also makes it easy to establish an active learning pipeline, collaborate with your team on dataset improvement, and integrate directly into your model building workflow with the roboflow pip package.
- Custom Training Example: https://blog.roboflow.com/train-yolov5-instance-segmentation-custom-dataset/
- Custom Training Notebook:(这个是模型辅助标记的软件,可以跳过)

Label images lightning fast (including with model-assisted labeling)
#@title Select YOLOv5 🚀 logger {run: 'auto'}
logger = 'Comet' #@param ['Comet', 'ClearML', 'TensorBoard']
if logger == 'Comet':
%pip install -q comet_ml
import comet_ml; comet_ml.init()
elif logger == 'ClearML':
%pip install -q clearml
import clearml; clearml.browser_login()
elif logger == 'TensorBoard':
%load_ext tensorboard
%tensorboard --logdir runs/train
# Train YOLOv5s on COCO128 for 3 epochs
python segment/train.py --img 640 --batch 16 --epochs 3 --data coco128-seg.yaml --weights yolov5s-seg.pt --cache
(这是训练命令成功运行后出现的一些运行参数,结合自己电脑进行修改,这个可以作为自己的参考) segment/train: weights=yolov5s-seg.pt, cfg=, data=coco128-seg.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=3, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=ram, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train-seg, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, mask_ratio=4, no_overlap=False github: up to date with https://github.com/ultralytics/yolov5 ✅ YOLOv5 🚀 v7.0-2-gc9d47ae Python-3.7.15 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB) hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0 TensorBoard: Start with 'tensorboard --logdir runs/train-seg', view at http://localhost:6006/ Dataset not found ⚠️, missing paths ['/content/datasets/coco128-seg/images/train2017'] Downloading https://ultralytics.com/assets/coco128-seg.zip to coco128-seg.zip... 100% 6.79M/6.79M [00:01<00:00, 6.73MB/s] Dataset download success ✅ (1.9s), saved to /content/datasets
(从这里面可以看到训练数据集的存放位置等一些信息) Transferred 367/367 items from yolov5s-seg.pt AMP: checks passed ✅ optimizer: SGD(lr=0.01) with parameter groups 60 weight(decay=0.0), 63 weight(decay=0.0005), 63 bias albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8)) train: Scanning /content/datasets/coco128-seg/labels/train2017... 126 images, 2 backgrounds, 0 corrupt: 100% 128/128 [00:00<00:00, 1389.59it/s] train: New cache created: /content/datasets/coco128-seg/labels/train2017.cache train: Caching images (0.1GB ram): 100% 128/128 [00:00<00:00, 238.86it/s] val: Scanning /content/datasets/coco128-seg/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100% 128/128 [00:00<?, ?it/s] val: Caching images (0.1GB ram): 100% 128/128 [00:01<00:00, 98.90it/s] AutoAnchor: 4.27 anchors/target, 0.994 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅ Plotting labels to runs/train-seg/exp/labels.jpg... Image sizes 640 train, 640 val Using 2 dataloader workers Logging results to runs/train-seg/exp Starting training for 3 epochs...
(训练成功之后出现的界面,里面包含了损失函数、预测值、mAP值等信息)
Epoch GPU_mem box_loss seg_loss obj_loss cls_loss Instances Size
0/2 4.92G 0.0417 0.04646 0.06066 0.02126 192 640: 100% 8/8 [00:08<00:00, 1.10s/it]
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100% 4/4 [00:02<00:00, 1.81it/s]
all 128 929 0.737 0.649 0.715 0.492 0.719 0.617 0.658 0.408
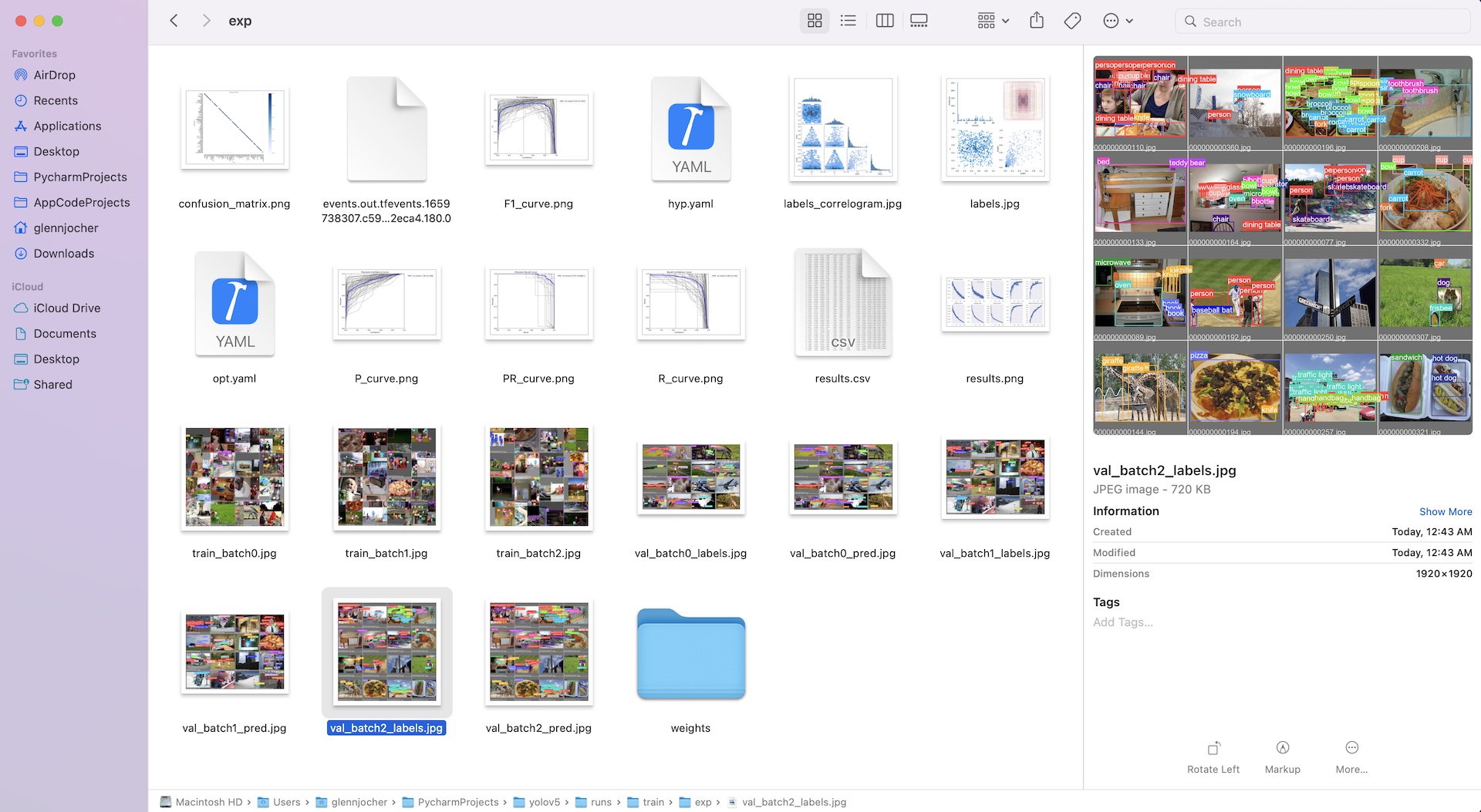
Local Logging(本地日志记录,训练完成查看预测值)
Training results are automatically logged with Tensorboard and CSV loggers to runs/train, with a new experiment directory created for each new training as runs/train/exp2, runs/train/exp3, etc.
This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









