







LoRA 官网
LoRA(Low-Rank Adaptation)出自2021年的论文“LoRA: Low-Rank Adaptation of Large Language Models”
常见的大模型微调方法:
Adapter-Tuning、Prefix-Tuning、Prompt-Tuning(P-Tuning)、P-Tuning v2、LoRA。
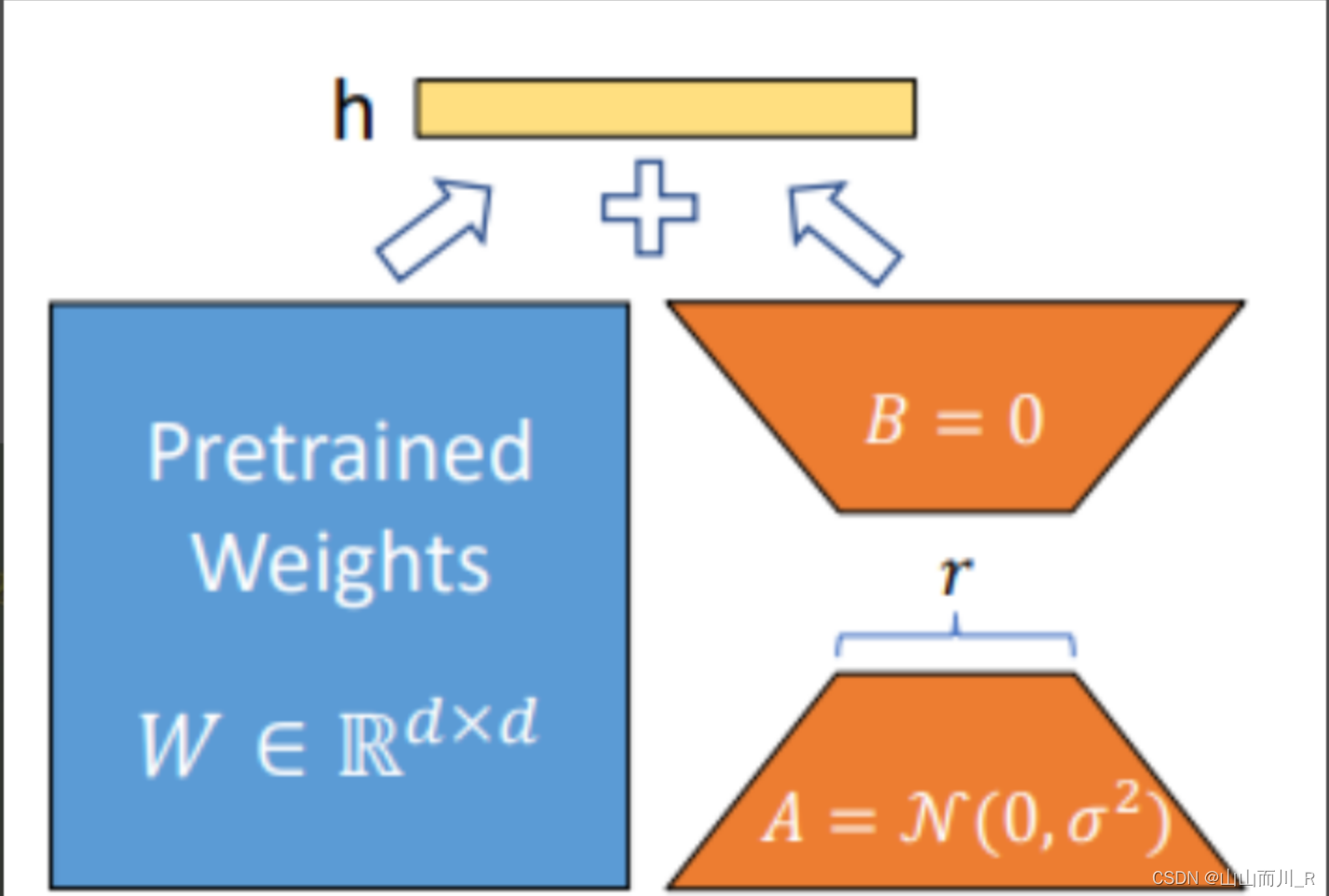
LoRA技术冻结预训练模型的权重,并在每个Transformer块中注入可训练层(称为秩分解矩阵),即在模型的Linear层的旁边增加一个“旁支”A和B。其中,A将数据从d维降到r维,这个r是LoRA的秩,是一个重要的超参数;B将数据从r维升到d维,B部分的参数初始为0。模型训练结束后,需要将A+B部分的参数与原大模型的参数合并在一起使用。
LoRA微调的优点包括:
(1)训练速度更快。
(2)计算需求更低。
(3)训练权重更小
解读:LoRA
LoRA:大型语言模型的低秩适应 (Low-Rank Adaptation,简称LoRA)
即Low-Rank Adaptation,是一种针对大型预训练语言模型的参数高效微调方法。在自然语言处理领域,大型语言模型(如GPT-3、BERT等)已经取得了显著的成功,但这些模型的参数量往往非常庞大,达到数十亿甚至千亿级别。因此,对这类模型进行微调(fine-tuning)以适应特定任务时,需要消耗大量的计算资源和时间。
LoRA的主要思想是将这些大型模型的适应性参数分解为两个低秩矩阵的乘积,从而大幅减少需要更新的参数数量。具体来说,LoRA在原始模型的基础上添加了额外的可训练参数,这些参数以矩阵的形式存在,并通过与原始模型中的注意力矩阵或前馈网络矩阵相乘,来模拟微调过程中参数的变化。
这种方法的优势在于:
-
计算效率:由于更新的参数数量大幅减少,因此在进行微调时,所需的计算资源(如GPU内存和计算时间)也相应减少。
-
存储效率:由于不需要存储原始模型的所有参数的更新版本,因此可以节省存储空间。
-
稳定性:由于更新的参数较少,LoRA可以减少过拟合的风险,提高模型的泛化能力。
-
灵活性:LoRA可以应用于不同类型的模型,包括但不限于基于注意力机制的模型和基于Transformer的模型。
LoRA的实现通常涉及以下步骤:
-
冻结原始模型参数:在微调过程中,保持预训练模型的所有参数不变。
-
添加低秩矩阵:在原始模型的某些层中添加额外的可训练低秩矩阵。
-
微调低秩矩阵:使用特定任务的数据来训练这些低秩矩阵,从而使模型适应新的任务。
-
推理时结合低秩矩阵:在推理阶段,使用更新后的低秩矩阵与原始模型参数相结合,以生成输出。
LoRA为大型语言模型的微调提供了一种高效的方法,使得在资源有限的情况下也能对模型进行有效的适应和定制。
论文 LoRA 论文
自然语言处理的一个重要范例包括大规模的预训练一般域数据和适应特定的任务或域。当我们预训练更大的模型时,重新训练所有模型参数的完全微调变得不太可行。以GPT-3 175 B为例--部署微调模型的独立实例,每个实例都有175 B个参数,这是非常昂贵的。我们提出了低秩自适应(Low-Rank Adaptation,简称LoRA),它冻结了预先训练的模型权重,并将可训练的秩分解矩阵注入到Transformer架构的每一层中,大大减少了下游任务的可训练参数数量。与使用Adam微调的GPT-3 175 B相比,LoRA可以将可训练参数的数量减少10,000倍,并将GPU内存需求减少3倍。LoRA在RoBERTa、DeBERTa、GPT-2和GPT-3上的模型质量表现与微调相当或更好,尽管可训练参数更少,训练吞吐量更高,而且与适配器不同,没有额外的推理延迟。我们还提供了一个实证调查排名不足的语言模型适应,揭示了LoRA的功效。我们发布了一个软件包,用于促进LoRA与PyTorch模型的集成,并在此https URL中提供了RoBERTa,DeBERTa和GPT-2的实现和模型检查点。
参考:大模型微调技术(Adapter-Tuning、Prefix-Tuning、Prompt-Tuning(P-Tuning)、P-Tuning v2、LoRA)_prefix tuning-CSDN博客



















 1329
1329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











