






编者按
面向对象的遥感图像目标检测技术已经得到了广泛的应用近年来取得了很大进展。然而,大多数目前的方法只关注目标检测,无法在复杂场景中很好地区分细粒度对象。在本技术报告中,作者分析了细粒度对象识别的关键问题,并使用了面向对象的功能校准网络(OFA网络)以实现高性能面向细粒度对象的光学遥感识别传感图像。OFA网络通过旋转边界框细化模型实现精确的对象局部化

Oriented Feature Alignment for Fine-grained Object Recognition in High-Resolution Satellite Imagery
1. Introduction
随着可用遥感图像的增加,遥感图像的有效判读变得越来越重要。目标检测是一种有效的海量遥感解译方法。近年来,随着信息技术的飞速发展,通过深入学习,目标检测技术得到了突飞猛进的发展[10,4,9,2]。目标检测在遥感图像方面也取得了很大进展。A.提出了一系列高效探测器来实现遥感图像中的高精度目标检测[3, 5, 6, 7, 14, 1, 8, 15].
与使用水平边界框(HBB)注释对象的一般对象检测不同,遥感图像中的对象检测通常采用定向边界框(OBB)来描述对象。与HBB相比,OBB包含的背景更少,因此它可以更有效地描述目标的轮廓信息,这对于卷积神经网络(CNN)显示边界特征是非常有效的。当前的主流方法都是预先设置旋转的先验边界框或生成旋转的建议,如RoI Transformer[1],CFC Net[5].
然而,目前大多数检测器都是继承了一般的检测方法,没有注意到遥感图像中特有的问题。也就是说,从高空观察时,很难区分不同类别的类似目标。例如,DOTA[12]是目前具有OBB注释的最大遥感数据集,包含15个类别。这些类别的外观有很大的不同。即使在遥感图像中,也不难区分不同的类别(如桥梁和飞机)。在DOTA数据集上表现良好的这些方法在区分细粒度目标时可能会表现不佳。如图1所示,除非您是该领域的专家,否则很难区分不同类型的飞机。

遥感图像中的细粒度目标识别是一项具有挑战性的任务。在高视距下,对象几乎没有纹理特征,因此很难识别它们。此外,实例的长尾分布将进一步降低识别精度。在本技术报告中,我们使用面向特征对齐网络(OFA Net)实现遥感图像中的高精度细粒度目标识别。网络是一种无锚方法,它在图像上放置密集的锚盒。这些锚定框生成候选方案,以捕获对象的可能位置,从而提高召回率。具体来说,我们使用一个额外的定向框细化模块来调整所获得建议的位置。对于分类任务,我们设计了面向对象的特征对齐分支来提取细粒度分类任务中旋转后的特征。

类别不平衡是影响检测准确性的另一个问题。如图2所示,不同类别的实例数量存在巨大差距。为了实现平衡的训练过程,我们执行了类平衡采样来扩展数据集。同时,数据扩充1(如随机裁剪、翻转、光学失真等)用于扩展数据集。这些方法可以有效地提高识别的准确性。
1.分析了细粒度对象识别的技术难点,并提出了解决方案。
2.采用OFA网络将细粒度目标检测任务解耦为定位子任务和分类子任务。然后采用旋转锚点细化模型(RARM)和精确检测模块(ADM)实现高精度定位和分类。
3.设计了有效的数据扩充策略,大大提高了识别精度。此外,我们还尝试了一系列技巧,并详细报告了效果。
2. Methodology
我们建议将细粒度对象识别任务分解为定位任务和分类子任务。然后,我们为这两个子任务设计有效的结构以实现高性能。

定位子任务的目的是实现边界框回归的高召回率和高精度。为此,我们在检测分支中采用了面向级联的细化模块。如图3所示,定位分支由两部分组成:旋转锚优化模块(RARM)和精确检测模块(ADM)。其中,RARM使用低IoU阈值选择阳性样本(在我们的实验中设置为0.4),以尽可能提高召回率。定向锚定细化后获得的高质量建议被发送给ADM,用于最终定位输出,从而实现高结果精度。级联优化模块的优越性已在以前的一些工作中得到证实[5, 3, 13]。
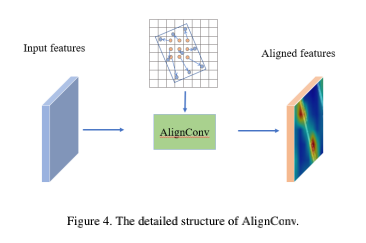
分类任务是细粒度对象识别任务的要点之一。需要捕获细粒度特征,以实现对类似类的准确区分。因此,我们建议提取尽可能多的有效纹理信息,同时忽略背景。为此,我们在S2ANet[3]中使用AlignConv来实现局部特征的对齐和提取。AlignConv从可能包含对象的建议区域提取对齐卷积特征,并有效地提取纹理信息,以帮助实现高性能分类。AlignConv的详细信息如图4所示。
3. Experimental Results
3.1. Dataset and Implementation Details
我们使用的数据集包括高分挑战赛和FAIR1M数据集中的细粒度对象识别比赛[11]。FAIR1M是ISPRS长凳高分辨率卫星图像中的目标检测标记,包含37个类别。FAIR1M数据集中的对象类别包括波音737、波音777、英格兰银行747、波音787、空中客车A320、空中客车A320、空中客车A330、空中客车A350、中国商飞C919、中国商飞ARJ21、其他飞机、客船、摩托艇、渔船、拖船、工程船、液体货船、干货船、军舰、其他船舶、小型汽车、公共汽车、货车、,自卸车、厢式货车、拖车、牵引车、卡车牵引车、挖掘机、其他车辆、棒球场、篮球场、足球场、网球场、环岛、十字路口和桥梁。在数据集中,每个对象都由一个定向边界框(OBB)进行注释。我们对FAIR1M数据集的测试集进行了评估,并在服务器上提交了高分挑战的最终提交。

输入图像被裁剪成800*800块,间距为150。我们使用SGD优化器以0.05的学习率训练网络。我们在2个RTX 2080ti GPU上训练12个时代的模型。随机裁剪、翻转、平移、仿射变换和光学失真用于数据增强。我们在FAIR1M的列车组上训练模型,并在FAIR1M的测试组上评估模型。最后,我们在高分挑战赛上对模型进行了测试。FAIR1M的总结果如表1所示。
3.2. Evaluation of pretrain models
我们尝试使用额外的数据进行预训练,包括DOTA数据集和高芬2020竞赛中300张细粒度飞机识别数据图像,然后在FAIR1M上对模型进行微调。表1中ID1和ID6的实验(40.7887%对40.7576%)表明,DOTA训练前体重在某些场景相似性较高的类别(如棒球场、篮球场、足球场、网球场)中提供了良好的先验知识优势。相关类的性能得到了改进。另一方面,细粒度的飞机图像与FAIR1M数据非常相似。表1中ID5和ID6的实验表明,使用预先训练的模型有效地提高了飞机识别的性能。此外,预先训练的模型加快了模型的收敛速度。例如,使用DOTA预训练权重,在FAIR1M上为1个历元微调的模型可以达到与从头开始的6个历元训练相当的精度。
3.3. Evaluation of IoU threshold for training sample selection
不同的IoU阈值会导致不同的训练样本分布,影响检测性能。阳性样本的低IoU阈值有助于提高召回率,但会降低检测精度。高IoU阈值将获得更高的准确率,但召回率可能不高。我们尝试了不同的阈值设置。如表1中的ID5和ID9所示(40.6944%对41.3631%),我们可以在第一阶段设置一个较低的IoU阈值以确保召回率,并在第二阶段设置一个较高的IoU阈值以提高准确性,这样可以实现更高的检测性能。
3.4. Evaluation of data augmentation
我们使用多种数据增强方法,包括随机翻转、仿射变换和光学失真。还尝试了剪切、随机噪声和随机dom像素下降等方法,但效果不佳。此外,我们使用很少的实例对类别进行重采样,以扩展训练集。有了这些数据,我们的数据集翻了一番。然后进行了多尺度的培训和测试,并取得了显著的性能改进,如ID10和ID11所示(分别为40.8882%和43.7304%)。该单一模型在高分细粒度飞机识别航迹(排名10/213)中实现了46.1747%的mAP,比基线提高了6个多点。
3.5. Outlook and other analysis
上述实验结果是通过单模型评估得出的。由于时间和可用GPU资源的限制,我们无法进一步进行apply复杂数据增强和多模型集成,用于更高的mAP。我们相信我们的方法和培训策略能够取得更好的绩效。我们还尝试了其他策略。例如,罪gle模型组合有助于略微提高性能(在高分挑战赛中约为0.5分)。这也是国际米兰测试表明,即使对微小数据进行复杂的数据扩充,特定类别的专家模型也不能显著提高检测精度。可能是因为安装过度?还是类似阶级之间的误判?我不确定。首先要弄清楚分类或检测是真正的问题,还是两者兼而有之。我以后会说清楚的。还有一件事,阶级不可知的NMS永远不会起作用。显然,在大多数情况下,在mAP中,回忆比精确更重要,这与第3.4节中的结论一致。
4. Conclusion
在本技术报告中,我们分析了光学遥感图像中细粒度目标识别的困难,并设计了实现高精度目标检测的有效策略。具体来说,我们将细粒度对象识别检测任务分解为检测子任务和分类子任务。旋转锚点细化模块用于获得精确的对象定位,而定向特征对齐模块用于有效提取对象的纹理特征。此外,我们还设计了定制的数据扩充策略和重采样策略来缓解类别不平衡的问题。甚至我们的方法的单一模型也取得了令人印象深刻的结果。我们仍有很大的改进空间,我们将在未来找出解决方案。















 5022
5022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









