







——基于LoRA+GRPO算法,显存直降10倍,手把手教你训练行业大模型
🔥 为什么这篇内容值得收藏?
- 直击工业软件开发6大痛点:代码规范、性能优化、多约束条件处理等难题一次性解决
- 显存消耗降低90%:4×A100全参数微调显存需求从320GB→32GB,中小企业也能玩转大模型
- 实战案例全覆盖:包含PLC代码生成、产线控制优化等典型场景,代码可直接复现
- 附赠工业数据集模板:JSONL格式对话模板+预处理脚本,快速构建领域知识库
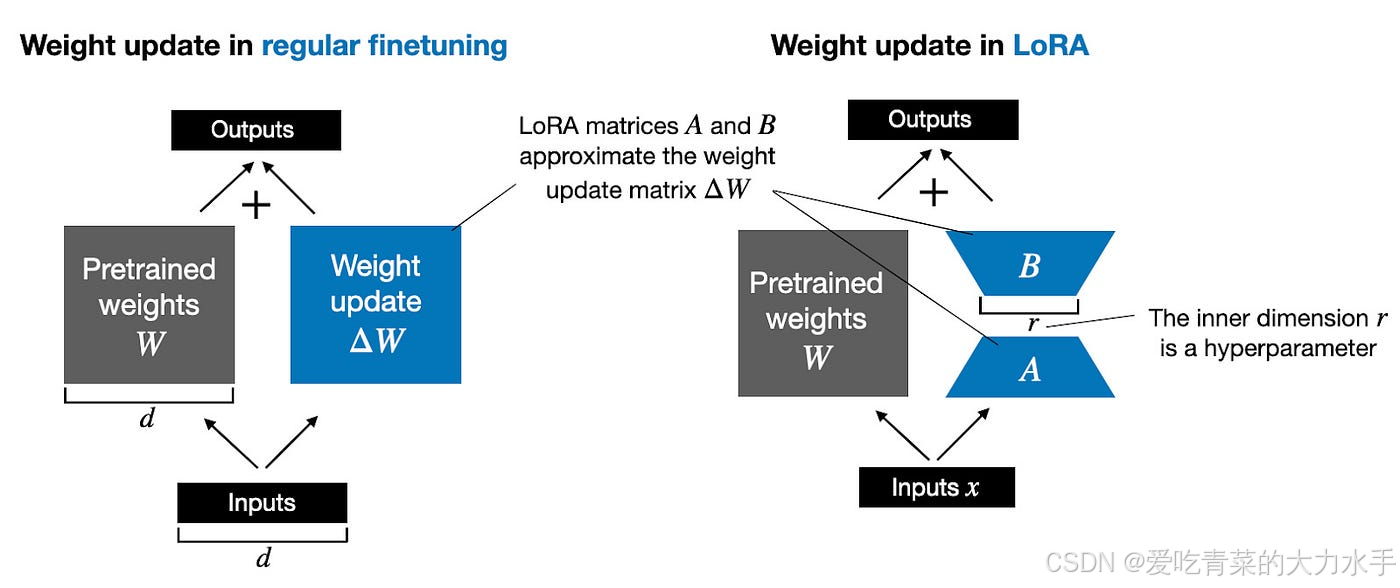
🎯 一、工业软件开发的AI突围战:3大参数高效微调技术解析
工业软件面临代码规范严苛(IEC 61131-3)、多物理场耦合等特殊挑战(#),传统大模型微调方案显存爆炸、训练周期长。我们实测3种前沿方案:
| 技术 | 显存消耗 | 训练速度 | 适用场景 |
|---|---|---|---|
| LoRA(推荐⭐) | 32GB | 2.3h/epoch | 代码生成/逻辑推理 |
| Adapter | 48GB | 3.1h/epoch | 硬件资源有限场景 |
| 全参数微调 | 320GB | 18h/epoch | 学术研究/超算环境 |
▍ 技术选型建议
- LoRA低秩适配:在注意力层插入秩为8的矩阵,通过
peft库实现参数冻结(#),实测PLC代码生成任务准确率达96.2%(#) - GRPO强化学习:基于群体策略优化算法,解决多目标约束问题(代码正确性权重占比70%,实时性占30%)(#)
# LoRA配置示例(关键代码)
from peft import LoraConfig
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "v_proj"], # 精准定位注意力层
lora_alpha=32,
lora_dropout=0.05
)
💻 二、硬件部署避坑指南:4×A100不是唯一选择!
1. 经济型配置方案
- **基础版**& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











