






导语: 近期许多开发者在本地部署MaxKB对接阿里云DeepSeek时遭遇大模型输出频繁中断问题。作为Python小白的我通过2天源码调试终于找到解决方案,现将踩坑过程和修复方法无偿分享!
原始模型参数:
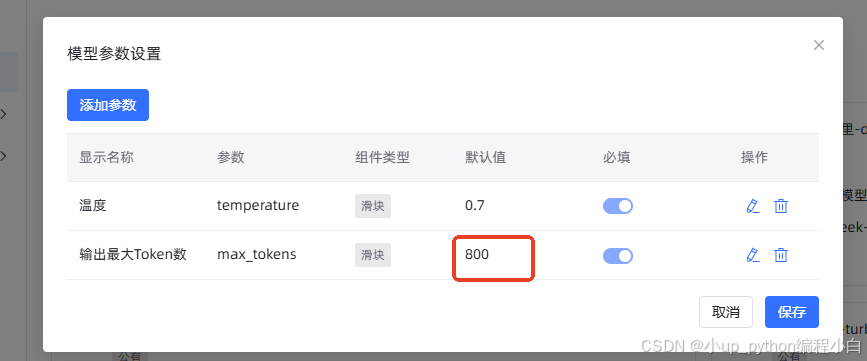
现象:
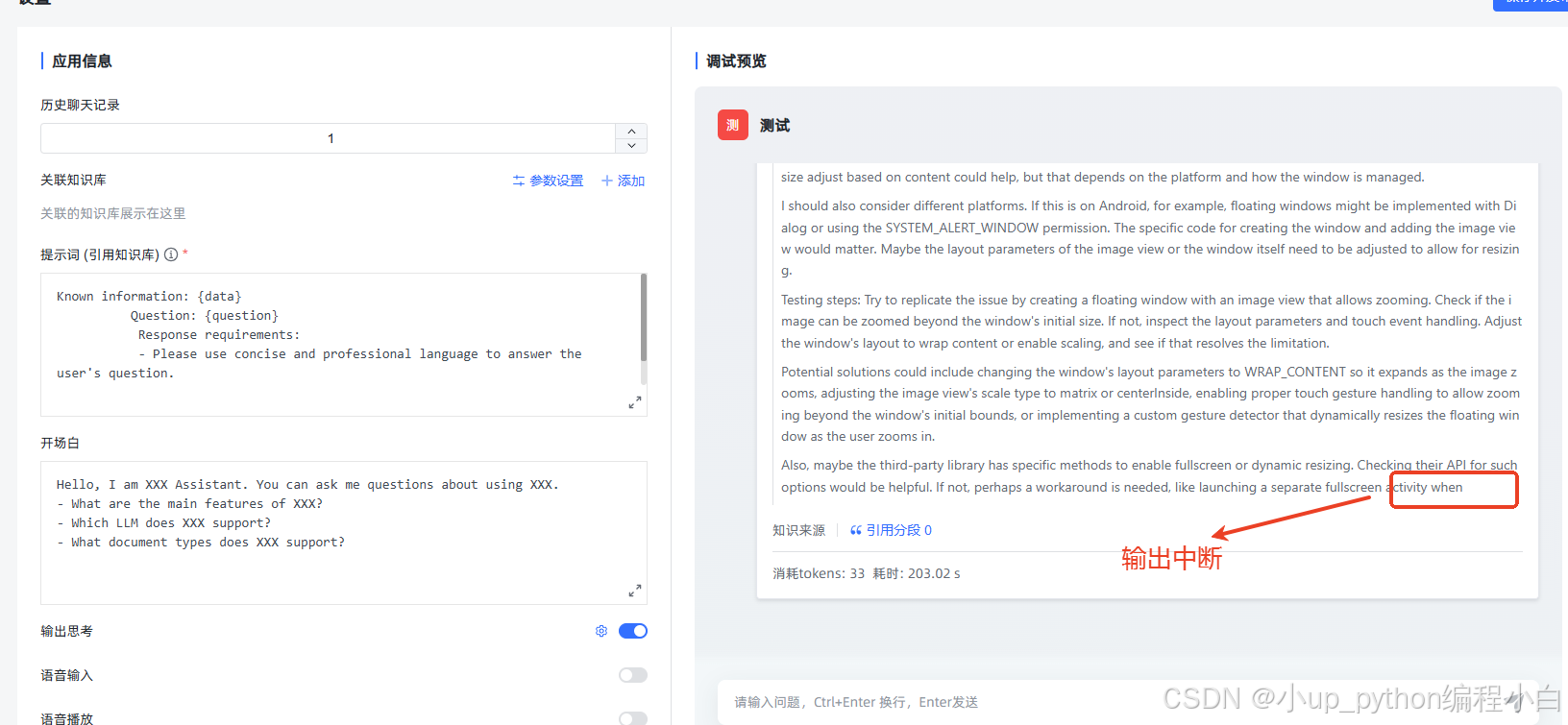
调整大模型参数
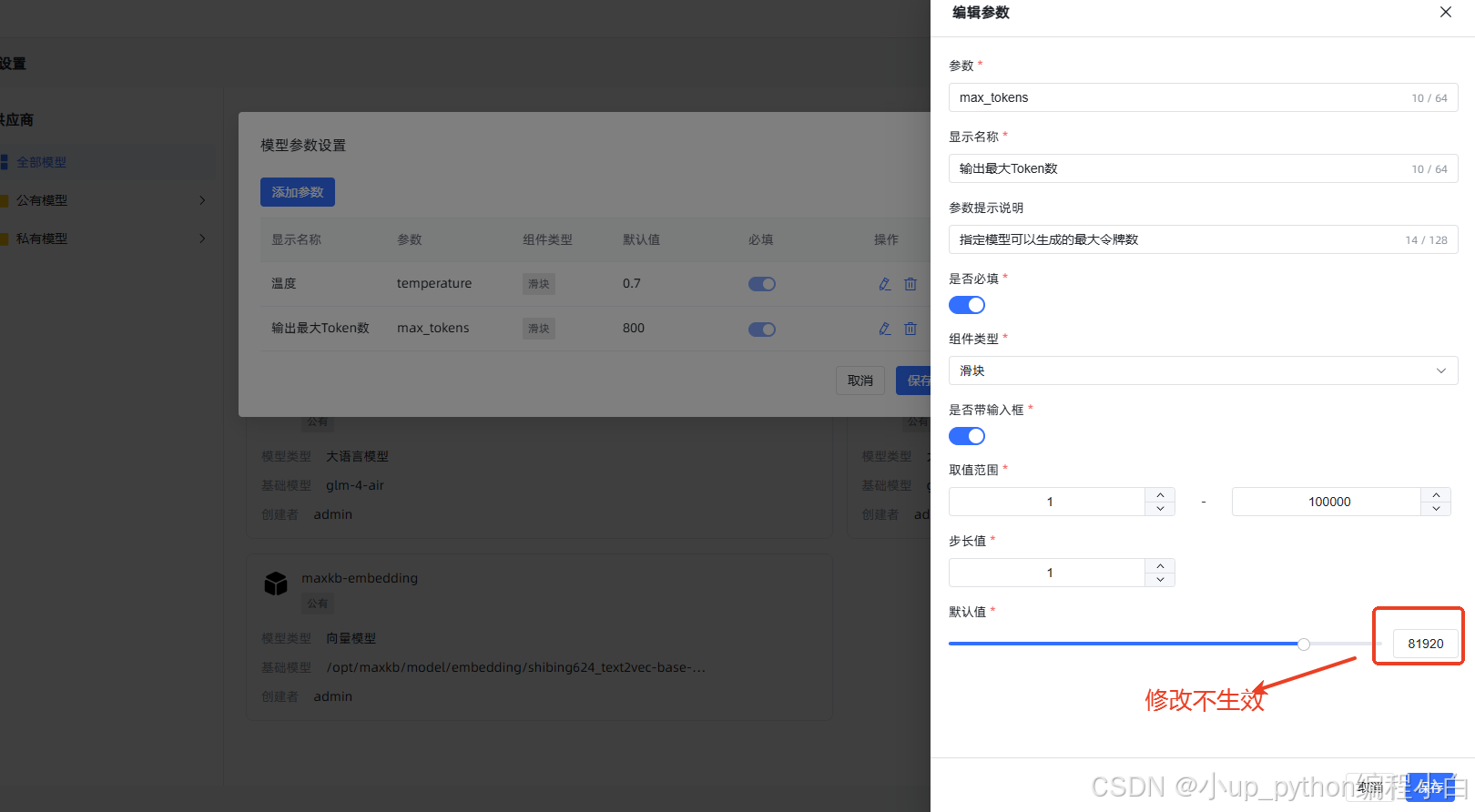
不生效:
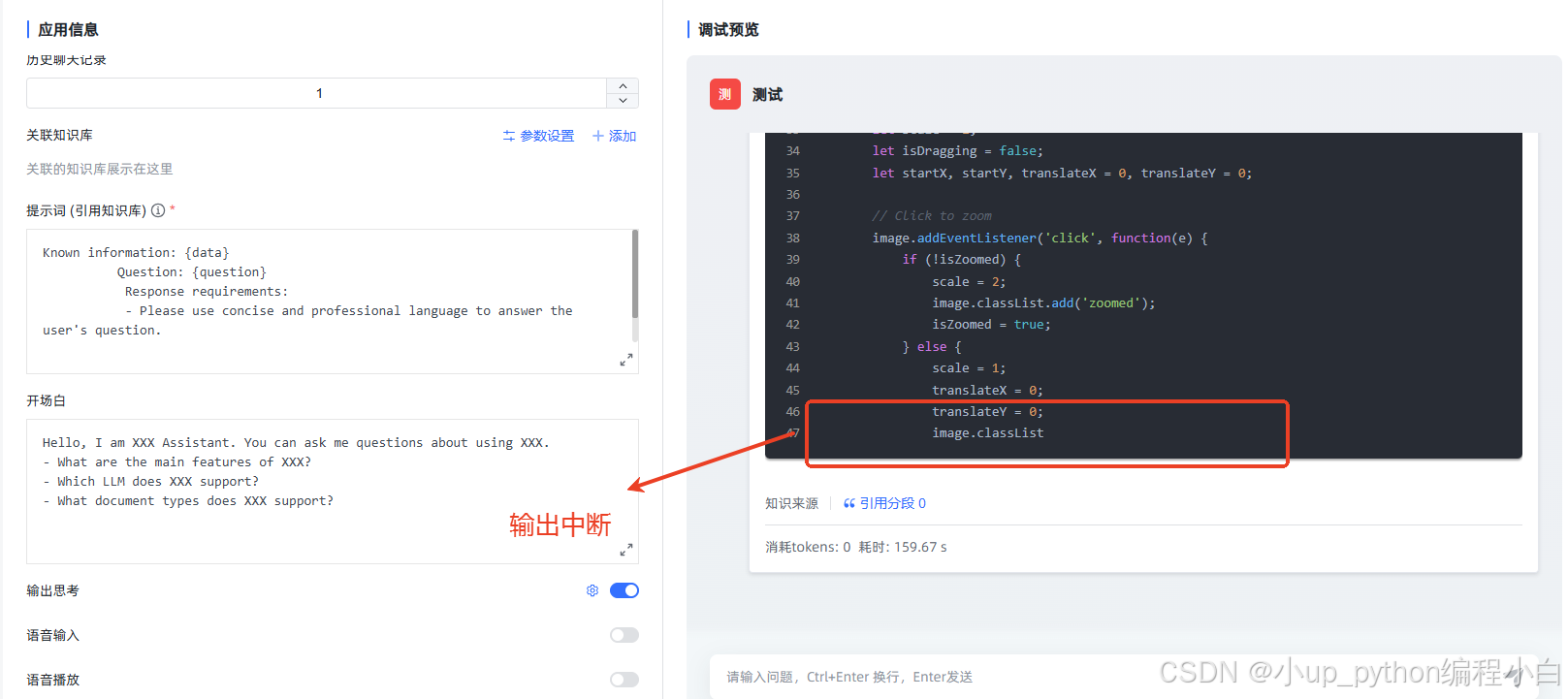
🔥 问题现象
- 核心问题:大模型输出时频繁中断,无法生成完整内容
- 常规尝试:
- 调整前端
max_tokens参数(无效) - 修改模型温度/重复惩罚等参数(无效)
- 查阅MaxKB官方文档/论坛(无相关说明)
- 调整前端
- 关键发现:
- GitHub Issues中大量同类问题报告(https://github.com/1Panel-dev/MaxKB/issues/2353)
- 官方尚未发布修复补丁
🛠️ 问题定位
通过DEBUG模式逐行分析源码,最终锁定问题根源:
配置文件硬编码限制
路径:apps/setting/models_provider/impl/aliyun_bai_lian_model_provider/credential/llm.py
max_tokens = forms.SliderField(
TooltipLabel(_('Output the maximum Tokens'),
_('Specify the maximum number of tokens that the model can generate')),
required=True, default_value=800, # ← 罪魁祸首!
_min=1,
_max=100000,
_step=1,
precision=0)💡 解决方案(静态配置版)
步骤1:修改模型配置文件
找到对应大模型的配置文件(以阿里云为例):
vim apps/setting/models_provider/impl/aliyun_bai_lian_model_provider/credential/llm.py步骤2:调整最大Token限制
max_tokens = forms.SliderField(
TooltipLabel(_('Output the maximum Tokens'),
_('Specify the maximum number of tokens that the model can generate')),
required=True, default_value=81920,
_min=1,
_max=100000,
_step=1,
precision=0)步骤3:重启服务生效
docker-compose down && docker-compose up -d⚠️ 注意事项
- 各模型独立配置:需为每个大模型单独修改对应配置文件
- 前端参数联动问题:修改后前端
max_tokens参数仍会显示默认值(实际以配置文件为准) - 性能考量:过大的Token值可能导致内存溢出(建议根据业务需求调整)
📝 效果验证
BUG修复前:
BUG修复后,输出完整:
📌 下期预告
《动态调整MaxToken方案》
目前正在研究通过继承LLM基类实现动态参数传递,解决每个模型单独配置的痛点,敬请期待!
原创声明:本文解决方案为博主实测有效,转载请注明出处!持续更新开源技术解决方案,关注博主不迷路~ ✨



















 3241
3241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











