









缓存
使用缓存可以更高效的获取数据,操作数据,如果没有缓存,所有的用户都在访问同一个服务器,同一个数据库,这样的话如果用户数过多就会导致速度变慢
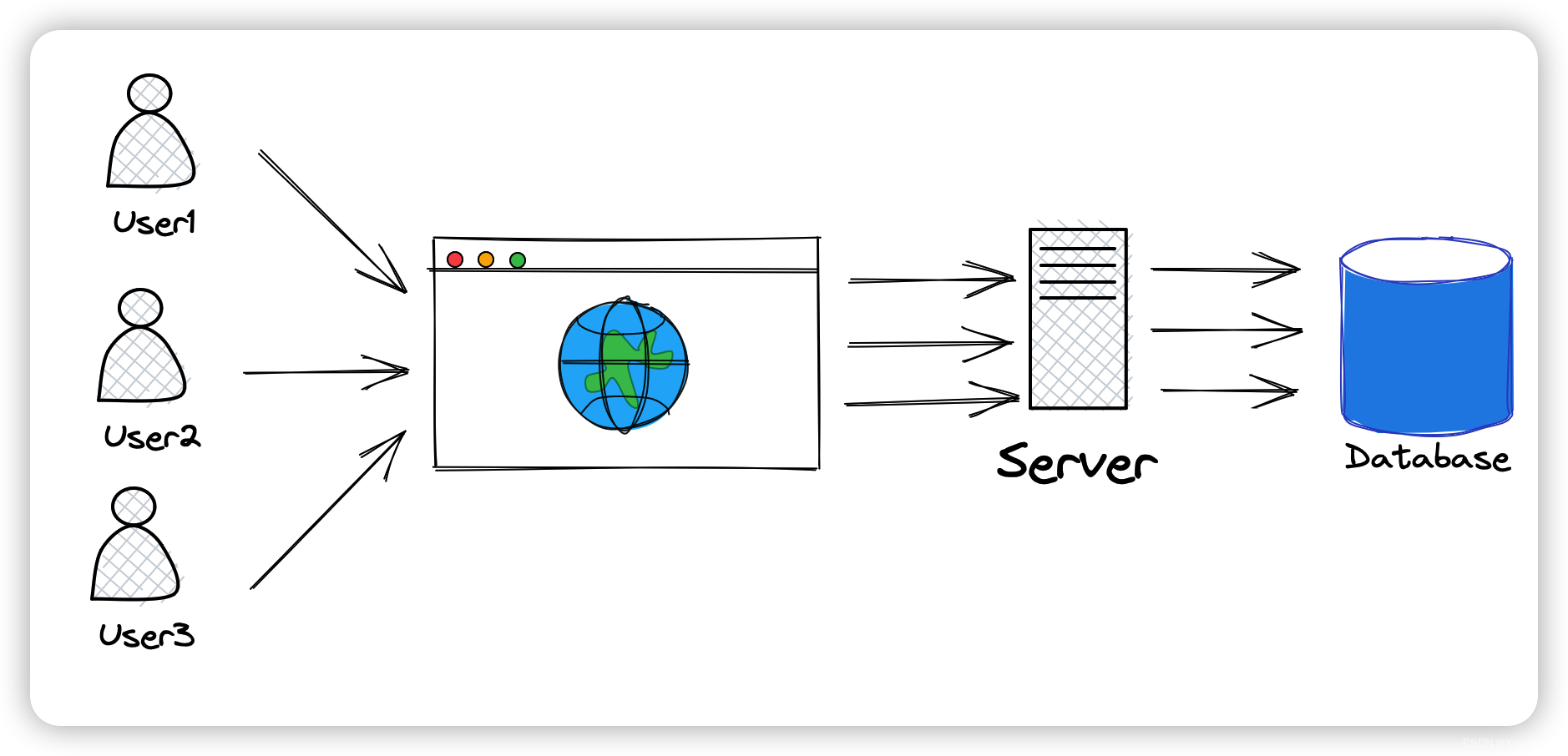
而如果使用多台服务器来分摊压力,由于还是使用同一个数据库,最终的性能瓶颈就在数据库上
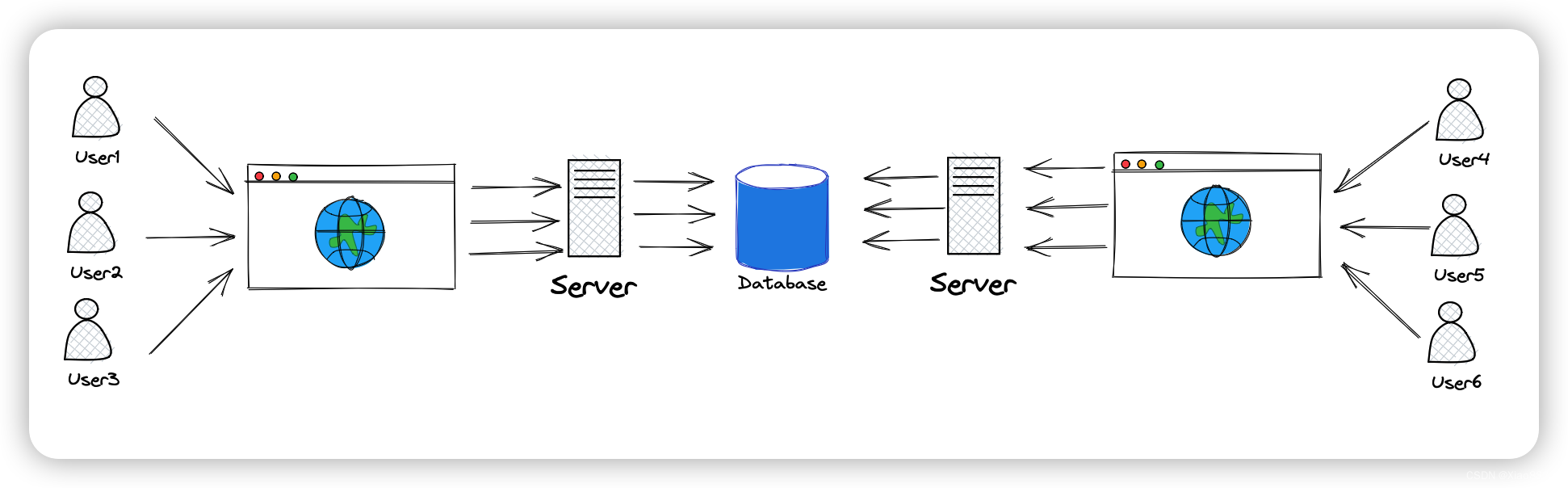
因此,我们可以使用缓存,将一些已经查询过的数据直接返回,没有数据再去访问数据库
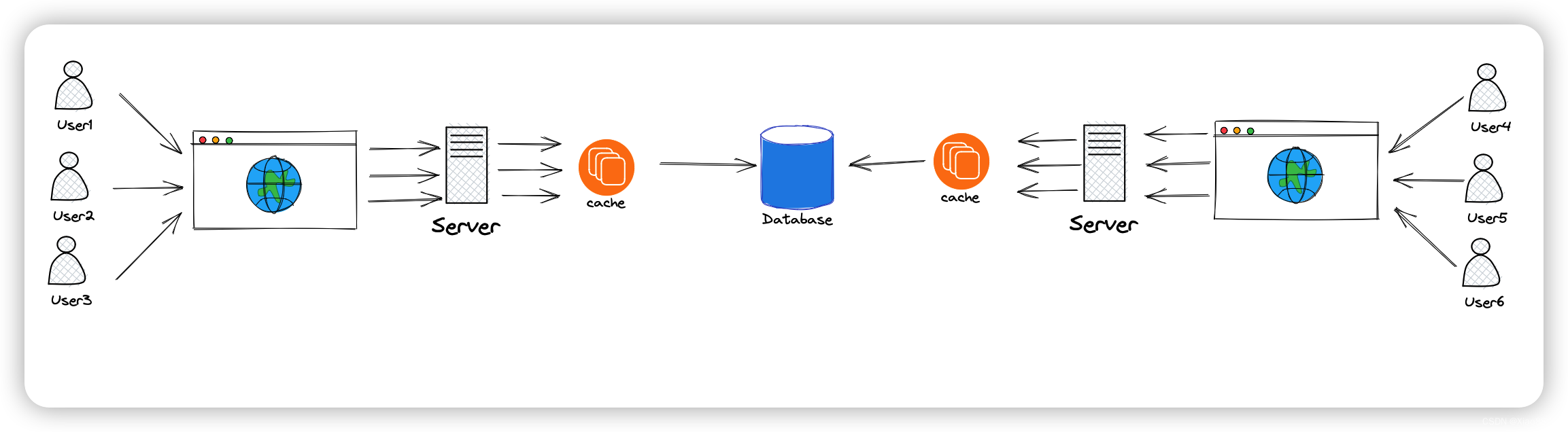
缓存具有如下几种优点:
- 缓存使用key-value存储,查询性能高
- 缓存存储在内容中,查询效率高
- 缓存更容易实现分布式部署
分布式缓存指的是应用在分布式系统中的缓存,分布式系统就是将用户的请求分散到不同的服务器上,减少一个服务器的负担
而分布式缓存可以保证所有的服务器都能够获取到其他服务器存储的缓存,这篇博客主要介绍的redis就是其中一种分布式缓存的存储方式
缓存雪崩
当内存中大量的缓存同时过期,那么请求会直接查询数据库,也就会带来巨大压力
具体的结果策略如下:
- 使用加锁排队:即降低了请求访问数据库的速度
- 随机化过期时间:避免缓存同时失效
- 设置二级缓存:当redis的缓存过期,先去查询二级缓存,二级缓存中没有再查询数据库
缓存穿透
如果数据库中没有数据,缓存中当然也不会存储相关数据,那么每次查询这种数据就会直接查询数据库,造成服务器压力
解决方案:
- 缓存空结果:缓存中将数据库中没有的数据存储为空
缓存击穿
和缓存雪崩类似,缓存击穿指的是缓存中的高频率访问数据突然过期,也会突然对服务器造成压力
解决方案:
- 加锁排队
- 设置永不过期:将缓存设置为永远不过期,但是需要在数据库中的数据更改后将缓存中的数据也进行改变
缓存预热
在服务器启动后,将热点数据先加入到缓存中,后期用户就可以直接在缓存中读取数据
Redis的数据类型
字符串类型
添加数据:
set key值 value值 ex 过期时间(单位是秒)
查询数据:
get key值;
结果是value值
查询字符串的长度:
strlen key
字典类型
添加数据:
hset 哈希表 key值 value值
查询数据:
hget 哈希表 key值
结果得到value值
列表类型
添加数据:
lpush 列表名 数据1 数据2 数据3...
查询第一个数据:
lpop 列表名
集合类型
添加数据:
sadd 集合名 数据1 数据2 数据3...
查询数据:
smembers 集合名
结果得到 数据1 数据2 数据3
有序集合类型
其中存储的每一个元素都有两个值,其中一个值是用来排序的可以重复,另一个值不可以重复
添加数据:
zadd 有序集合名 分值1 数据1 分值2 数据2 分值3 数据3
查询所有数据:
zrange zset 0 -1;
数据持久化
也就是将数据从内存存储到磁盘的过程,防止服务器重启后数据丢失,redis的数据持久化有下面几种方式
- 快照方式(RDB):以二进制将某一时刻的数据存入磁盘
- 文件追加方式(AOF):以文本将所有操作命令追加到文件中
- 混合持久化:既使用快照方式,又使用文件追加方式
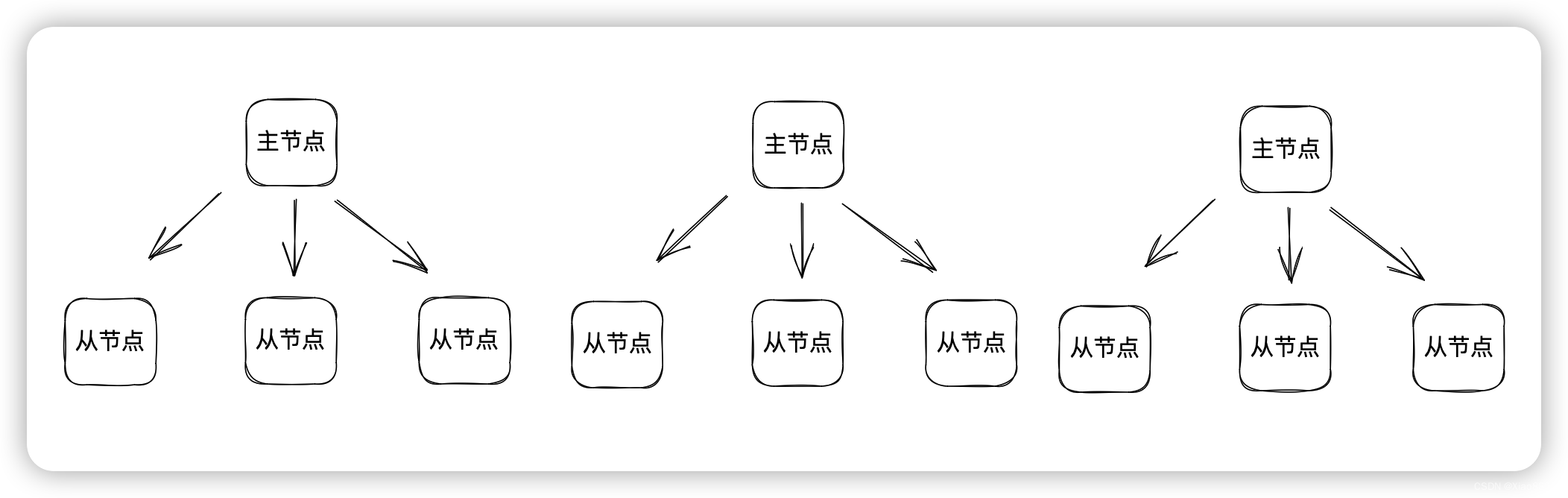
Redis集群
当规模进一步增大,那么一个Redis就不够用了,多个Redis包含如下几种模式
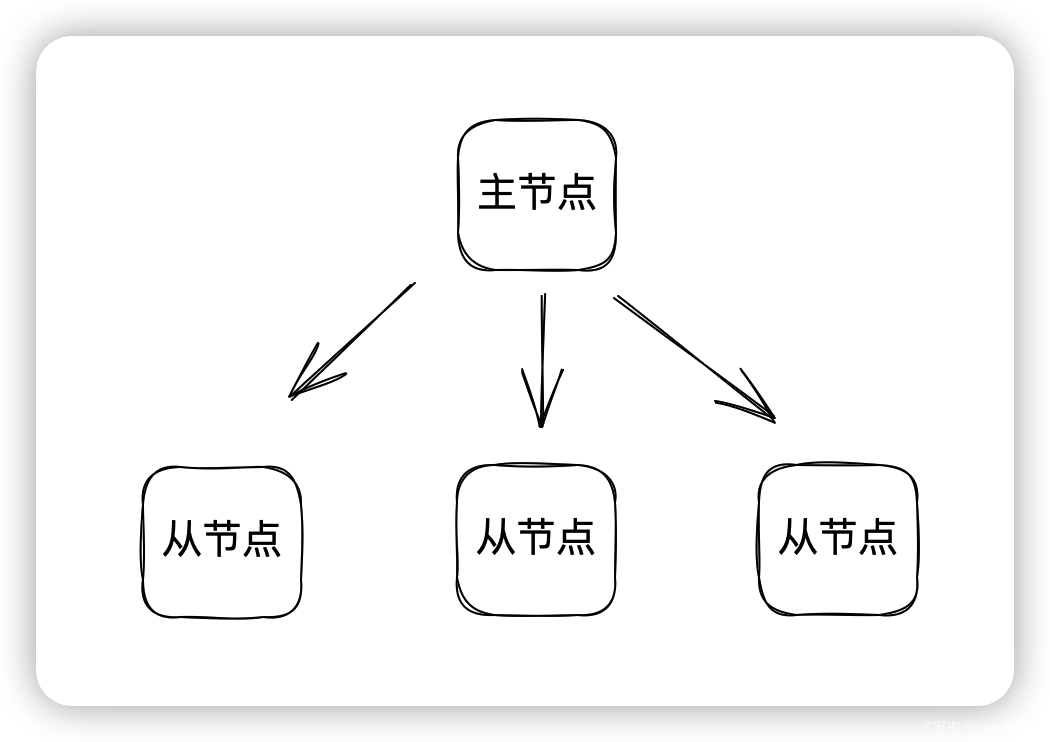
主从同步
主要存储数据的节点称之为主节点,其他从节点复制主节点的数据
从节点也可以作为别的节点的主节点,最终形成树的造型
哨兵模式
哨兵模式添加了一个哨兵节点,在主从服务器出现问题时可以自动恢复服务器
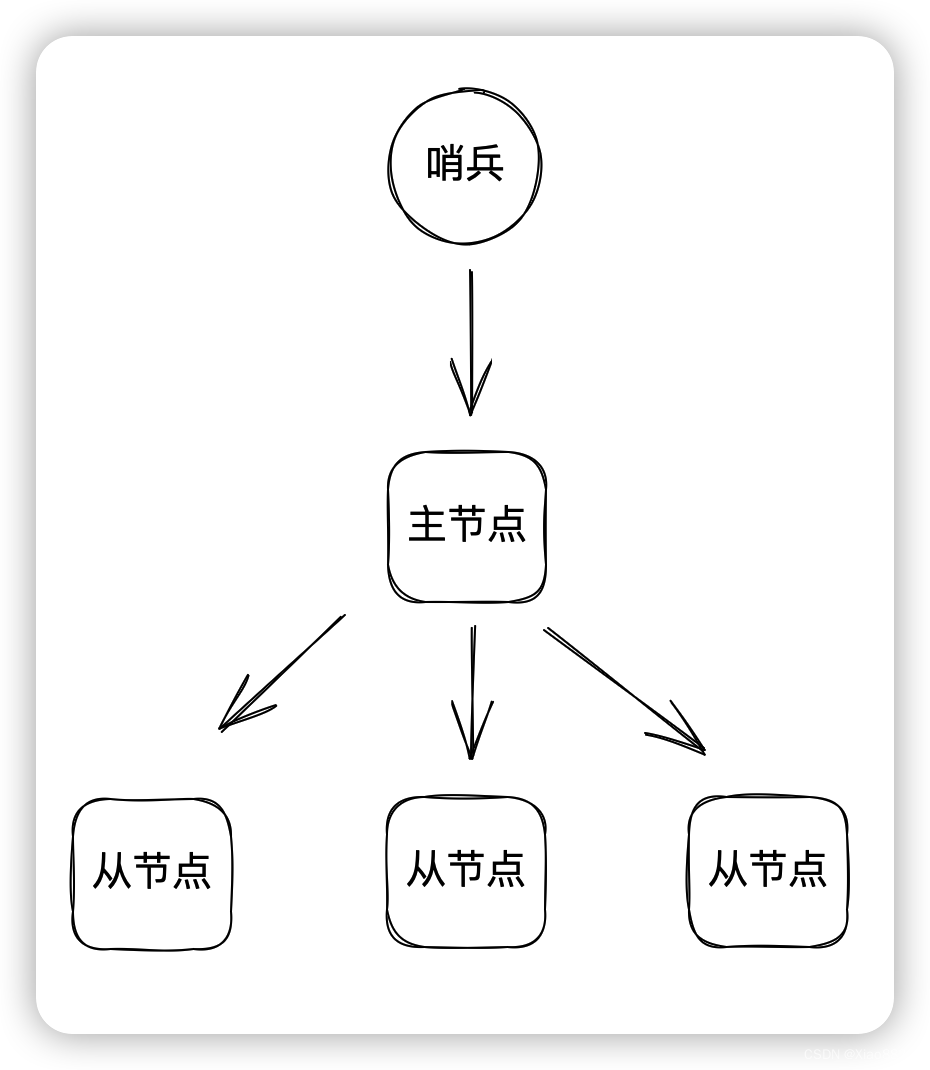
Redis集群服务
Redis的主从同步模式只能有一个主节点,而集群服务则是集成无数个主从节点














 1570
1570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









