







参考教程:B站up主:我是土堆
1. dir ( ) 与 help ( ) 函数 —— 学习时常用
import torch
# 打印 package 下的子分类
print(dir(torch))
print(dir(torch.cuda))
print(dir(torch.cuda.is_available))
# 打印 函数的使用方法
print(help(torch.cuda.is_available))2. 快捷键
Tab — 缩进、Ctrl — 查看函数具体信息、Ctrl + / — 注释
3. GPU训练
# 利用GPU训练神经网络:提升训练速度,远快于CPU
import torch
# 方法一:针对 “神经网络模型” “损失函数” “数据(训练集、验证集的值及其对应标签)” 使用 GPU 训练
if torch.cuda.is_available():
model_name = model_name.cuda()
loss_fn = loss_fn.cuda()
zhi = zhi.cuda()
label = label.cuda()
# 方法二:设置 “训练设备”
Device = torch.device("cuda")
# 若电脑含多张显卡:
# 指定训练设备为第一个cuda
Device = torch.device("cuda:0")
# 指定训练设备为第二个cuda
Device = torch.device("cuda:1")
Device = torch.device("cpu")
# 语法糖
Device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 以下两种写法等价
model_name = model_name.to(Device)
model_name.to(Device)
loss_fn = loss_fn.to(Device)
loss_fn.to(Device)
# 注意:训练集、验证集的值及其对应标签 仅能以该形式设置训练设备
zhi = zhi.to(Device)
label = label.to(Device)
4. pytorch 框架下的 “数据加载”
两个实用类:dataset ( ) 及 dataloader ( ):
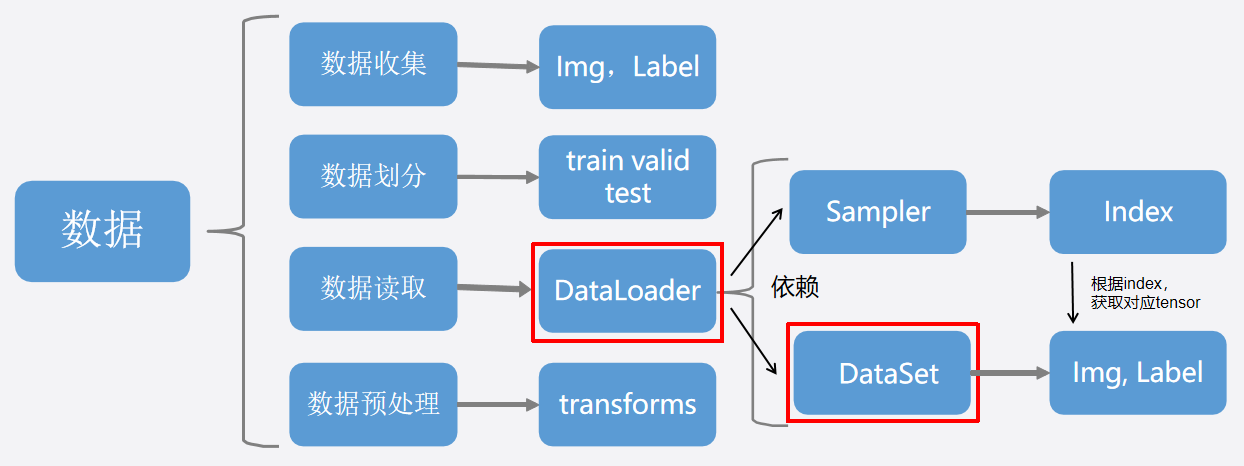

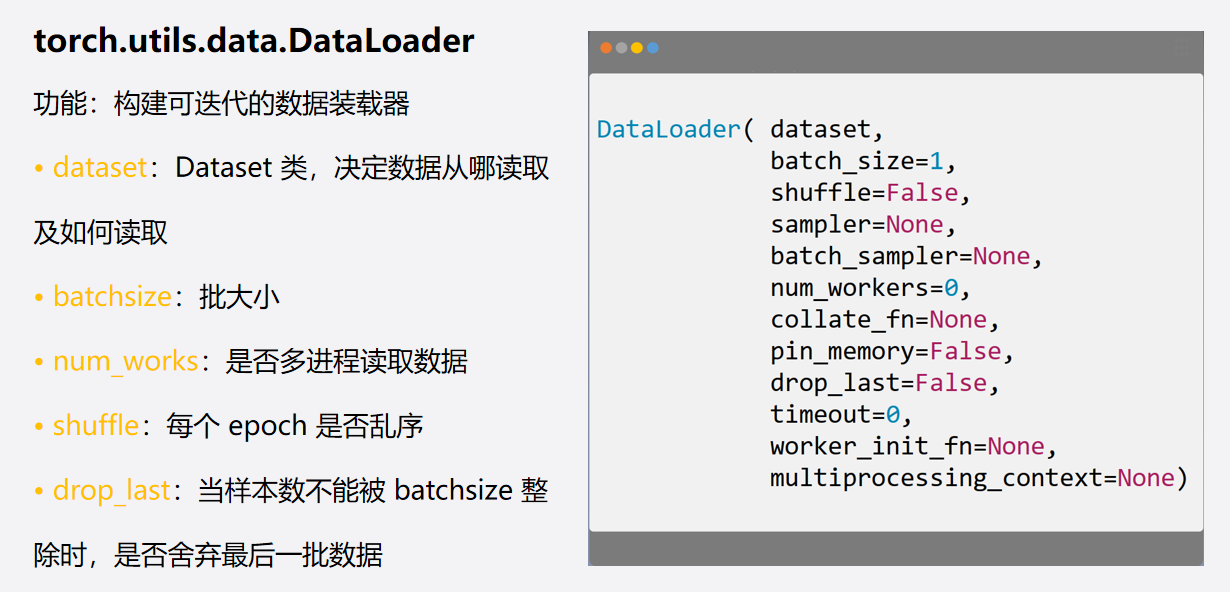
注:Epoch & Iteration & Batchsize:
Epoch: 所有训练样本都已输入至模型内一次,称为一个 Epoch
Iteration:一批 (一个Batch) 样本输入至模型内,称为一个 Iteration
(输入一个 Batch / 经历一次 Iteration,更新一次模型参数)
Batchsize:批 (Batch) 大小,决定一个 Epoch 有多少个 Iteration:
也即:num (Iteration) = num (train_data) / Batchsize
5. nn.Module:神经网络搭建 的 基本骨架
import torch
from torch import nn
# "container" —— 神经网络的基础模板,可修改其为更复杂的结构
# 继承父类 "nn.Module"
class model_name (nn.Module):
def __init__(self):
super().__init__()
# 前向传播,input-神经网络的输入
def forward(self,input):
output = input + 1
return output
# 模型实例创建
module_1 = model_name()
# 创建一个张量,作为模型的输入
x = torch.tensor(2.)
# 输出:经神经网络处理后的结果
y = module_1(x)
print(y)6. 卷积操作
理解:“卷积” 操作内的 "步幅 stride" 及 "外围填充 padding" 的设置:

空洞卷积,可增加 “感受野”:(设置 "dilation" 参数)

Q:写出:output_1、output_2、output_3的结果
import torch
import torch.nn.functional as F
# 创建被卷积的 tensor(外围有n个[] → n维tensor)
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
# 创建卷积核
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
# 变幻被卷积的 tensor 和卷积核的 shape
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel,(1,1,3,3))
output_1 = F.conv2d(input,kernel,stride=1)
print(output_1)
# 调整步幅 stride(stride可以为数字或元组,如:tuple(1,2) —— 横向步幅:1,纵向步幅:2)
output_2 = F.conv2d(input,kernel,stride=2)
print(output_2)
# 用 “0” 填充 input 的外围一层(padding可以为数字或元组)
output_3 = F.conv2d(input,kernel,stride=2,padding=1)
print(output_3)7. 池化操作
Q:写出:output 的结果,若 "ceil_mode=False",output 又将为何值?
import torch
from torch import nn
from torch.nn import MaxPool2d
# 创建被池化的 tensor(外围有n个[] → n维tensor)
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
# 定义含 “池化层” 的网络模型
class pool_net(nn.Module):
def __init__(self):
super(pool_net, self).__init__()
# 定义 “池化核” 的大小,注意:默认情况下,stride = kernel_size
self.pool_layer = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.pool_layer(input)
return output
# 变幻被池化的 tensor
input = torch.reshape(input, (-1, 1, 5, 5))
# 将 input 置于定义好的池化网络内
model = pool_net()
output = model(input)
print(output)8. 常用的非线性激活函数
引入非线性激活函数的目的:
旨在帮助网络学习数据中的复杂模式,对所有隐藏层及输出层添加 “非线性” 的操作,使得神经网络的输出更为复杂、表达能力更强
注意:绝大多数神经网络借助某形式的梯度下降进行参数优化,故:激活函数需要是可微分的
(或者至少是几乎完全可微分的)

9. 线性层(全连接层)
概念:各神经元都与上下层各神经元相连,一个简单的 “线性层(全连接层)” 如下所示:

具体函数:
# in_features & out_features:输入(出)特征数;bias:偏置项(默认为True)
torch.nn.Linear (in_features, out_features, bias=True, device=None, dtype=None)tip:torch.flatten ( ) 函数被用于 “拉平” 矩阵
10. Drop - out 操作:丢弃部分数据,避免过拟合
11. Sequential 的使用
Q:练习:写出下列图示的网络结构(使用 pytorch 框架):

代码如下:
1)不使用 Sequential 时的解答:
import torch
from torch import nn
from torch.nn import Flatten
# 搭建图示网络
class M (nn.Module):
# 定义后续将使用的网络模块
def __init__ (self):
super(M, self).__init__()
self.conv_1 = nn.Conv2d(3, 32, 5, padding=2)
self.pool_1 = nn.MaxPool2d(2)
self.conv_2 = nn.Conv2d(32, 32, 5, padding=2)
self.pool_2 = nn.MaxPool2d(2)
self.conv_3 = nn.Conv2d(32, 64, 5, padding=2)
self.pool_3 = nn.MaxPool2d(2)
self.flat = Flatten()
self.linear_1 = nn.Linear(1024, 64)
self.linear_2 = nn.Linear(64, 10)
# 定义前向传播
def forward(self, input):
input = self.conv_1(input)
input = self.pool_1(input)
input = self.conv_2(input)
input = self.pool_2(input)
input = self.conv_3(input)
input = self.pool_3(input)
input = self.flat(input)
input = self.linear_1(input)
input = self.linear_2(input)
return input
# 初始化上述定义的神经网络
m1 = M()
# 测试
q = torch.ones((64,3,32,32))
t = m1(q)
print(t.shape)
# 预计输出:torch.Size([64, 10])2)使用 Sequential 时的解答:(有助于简化网络搭建过程)
import torch
from torch import nn
from torch.nn import Flatten, Sequential
# 搭建图示网络
class M (nn.Module):
# 定义后续将使用的网络模块
def __init__ (self):
super(M, self).__init__()
# 使用 Sequential,有助于简化网络搭建过程,如下所示,以此类推
self.model1 = Sequential (
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
# 定义前向传播
def forward(self, input):
input = self.model1(input)
return input
# 初始化上述定义的神经网络
m1 = M()
# 测试
q = torch.ones((64,3,32,32))
t = m1(q)
print(t.shape)
12. Pytorch 下现有模型 的 引入及使用
import torch
import torchvision
from torch import nn
# 以 VGG16 神经网络为例
# 不含预训练参数的网络结构
vgg16_False = torchvision.models.vgg16(pretrained = False)
# 含有预训练参数的网络结构
vgg16_True = torchvision.models.vgg16(pretrained = True)
# 向 pytorch 框架提供的神经网络添加模块,进行结构修改
vgg16_False.add_module('linear_1',nn.Linear(1000,10))13. 模型的保存及加载
方法一:同时保存:模型的网络结构 及 模型参数:
import torch
import torchvision
# method 1
# 以 torchvision 内的 vgg 模型为例
model_vgg = torchvision.models.vgg16(pretrained=False)
# 模型保存(输入 待保存的模型 及 模型保存的路径名称)
torch.save(model_vgg, 'vgg.path')
# 模型加载(注意:若“保存”与“加载”不在同一python文件内,则需"import")
model_load = torch.load('vgg.path')
print(model_load)方法二:仅保存:模型参数(占用内存更小):
import torch
import torchvision
# method 2
# 以 torchvision 内的 vgg 模型为例
model_vgg = torchvision.models.vgg16(pretrained=False)
# 模型保存(输入 待保存的模型 及 模型保存的路径名称)
torch.save(model_vgg.state_dict(), 'vgg.path')
# 模型加载
vgg_16 = torchvision.models.vgg16(pretrained=False)
model_load = vgg_16.load_state_dict(torch.load('vgg.path'))
print(model_load)14. 损失函数 及 优化器
注:损失函数 “指导” 网络参数的优化更新,借助于 “优化器”
代码示例如下:
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









