








论文链接:https://arxiv.org/abs/2207.12201
代码链接:github.com
(一) 挑战
时间序列异常检测 在无监督情形下,通常依赖于:通过 单分类(one-class classification)的数据的 正态性(normality)。
→ 1. 训练集内存在 未知、不确定的异常;2. 缺乏 对关注的异常 的 先验知识
什么是 “异常污染(anomaly contamination)” ?
时间序列异常检测任务 可能被 隐藏在训练集内的 有害异常 (即:异常污染) 所偏差,导致:
1. 易过拟合;2. 对正常数据边界(normality boundary)的划分不准确
(本质上,“异常污染” 是含 罕见异常行为或模式 的噪音)
动机:校准单分类,减轻或消除训练集内 “异常污染” 的负面影响,将关注的异常知识引入学习过程,学习耐污染、异常提示的 “数据正态性”
如何 减轻或消除训练集内 “异常污染” 的负面影响?
嵌入不确定性(uncertainty)的新学习目标,自适应地惩罚不确定的预测,鼓励更自信的预测,以确保硬样本的有效学习,并对 “异常污染” 进行软掩盖
为什么使用:深度学习生成式组件 有无法避免的缺陷?
额外组件 本身可能也会受异常污染影响,从而导致伪标记或不正确地去除
为什么现有的自监督代理操作(如:增强噪声等) 有缺陷?
仅更好地学习了数据特征,无法提供 “异常” 的直接相关信息;忽略了:通过简单的数据扰动也可以可靠地模拟时间序列中的真实异常行为
本文提出的、解决“异常污染” 的方法:UMC + NAC

(二) UMC
高斯分布 方差的平方 可表示模型的不确定性:
Q1:如何引入“高斯分布”(Gaussian),作为新的损失函数?
Q1 : How to design a new learning objective that can handle distance distribution ?

Q2:如何:将 所求得的距离 引入至 高斯分布?
Q2 : how to extend the single distance value to its prior distribution ?
将 单个距离值的输出 扩展到 高斯分布:
1. 采用集合方法获得一组预测,估计分布的均值和方差(耗费计算资源)( x )
2. 设置 “旁路隐藏层” ,产生额外的投影输出 d(s*)( √ )

解读:模型对同一样本,作出不确定性预测时,| d(s) - d(s*) | 较大,产生惩罚
(三) NAC
根据异常类型(点、上下文、集群异常)→ 对原时间序列,进行数据扰动(Data perturbation)
→ 手动补充:对关注的异常 的 先验知识:

1. 子序列最后一个观测点 随机选择的一组维度的数据值 替换为 全局极值;(点异常)
2. 基于前 𝑘 个值 的平均值,作为偏移量,填充子序列最后一个观测点;(上下文异常)
3. 从序列末尾区间 [ 1, 0.2𝑙 ] 内随机采段,将这些值均替换为离群值(集群异常)
使用轻量级分类头 c,将各数据样本映射至一个分数。采用均方误差 (Mean Squared Error MSE) 将原始集合的子序列的输出回归到整数 y- = -1,将异常样本的输出回归到整数 y+ = 1
该分支的损失函数定义如下:

(四) 整体框架设计

(五) 超球

(六) 异常分数
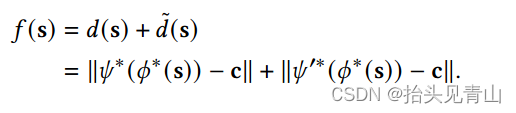
(七) 实验结果

















 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









