






找到【课程介绍】
Datawhale开源教程链接: https://github.com/datawhalechina/fantastic-matplotlib
本项目重点在两个层面帮助读者构建matplotlib的知识体系:
从图形,布局,文本,样式等多维度系统梳理matplotlib的绘图方法,构建对于绘图方法的整体理解。
从绘图API层级,接口等方面阐明matplotlib的设计理念,摆脱只会复制粘贴的尴尬处境。

目录
第三回:布局格式定方圆
头文件:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号一、子图
1. 使用 plt.subplots 绘制均匀状态下的子图
fig, axs = plt.subplots(2, 5, figsize=(10, 4), sharex=True, sharey=True)
fig.suptitle('标题', size=20)
for i in range(2):
for j in range(5):
axs[i][j].scatter(np.random.randn(10), np.random.randn(10))
axs[i][j].set_title('第%d行,第%d列'%(i+1,j+1))
axs[i][j].set_xlim(-5,5)
axs[i][j].set_ylim(-5,5)
if i==1: axs[i][j].set_xlabel('横坐标')
if j==0: axs[i][j].set_ylabel('纵坐标')
fig.tight_layout() fig, axs = plt.subplots(2, 5, figsize=(10, 4), sharex=True, sharey=True) | |
|
返回元素分别是画布和子图构成的列表。 第一个数字为行,第二个为列,不传入时默认值都为1。
用双重for循环来遍历设置每个子图。 最后一句 |  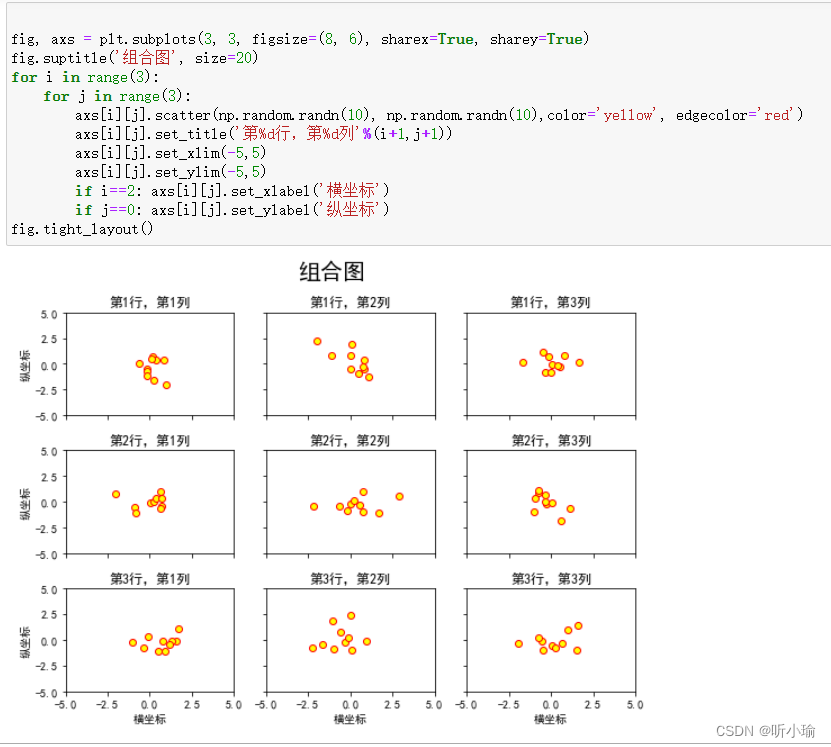 |
plt.figure()
# 子图1
plt.subplot(2,2,1) #两行两列中第一个
plt.plot([1,2], 'r')
# 子图2
plt.subplot(2,2,2) #两行两列中第二个
plt.plot([1,2], 'b')
#子图3
plt.subplot(224)
# 当三位数都小于10时,可以省略中间的逗号,这行命令等价于plt.subplot(2,2,4)
plt.plot([1,2], 'g'); plt.subplot(2,2,1) | |
还有种方式是使用subplot这样基于pyplot模式的写法,每次在指定位置新建一个子图,并且之后的绘图操作都会指向当前子图,本质上subplot也是Figure.add_subplot的一种封装。 | 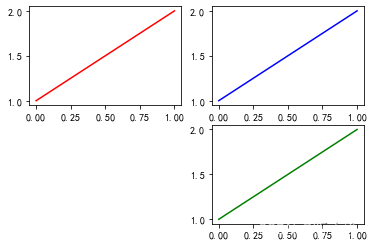 |
在调用subplot时一般需要传入三位数字,分别代表总行数,总列数,当前子图的index(也就是横着数第几个) | |
| 注: # plt.plot([1,2], 'r') 中1,2为y的坐标,x可省略,默认[0,1..,N-1]递增 # 当三位数都小于10时,可以省略中间的逗号,这行命令等价于plt.subplot(2,2,4) | |
【属性拓展】
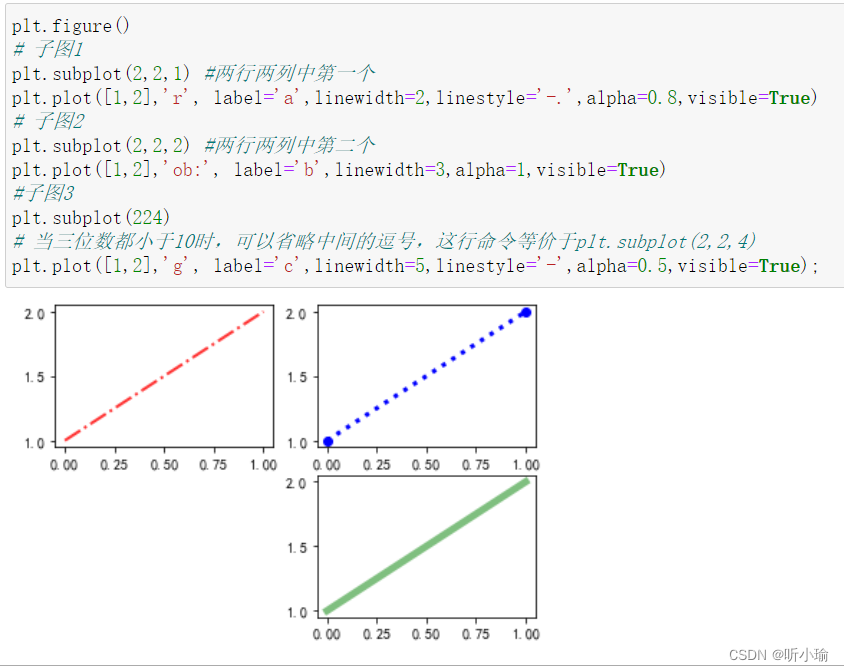
由于尝试某些线性失败,整理了所有可用类型。
"格式控制字符串"最多可以包括三部分, "颜色", "点型", "线型"
除了"格式控制字符串", 还可以在后面添加关键字=参数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
color=['b','g','r','c','m','y','k','w']
line_style=['-','--','-.',':']
dic1=[[0,1,2],[3,4,5]]
x=pd.DataFrame(dic1)
dic2=[[2,3,2],[3,4,3],[4,5,4],[5,6,5]]
y=pd.DataFrame(dic2)
# 循环输出所有"颜色"与"线型"
for i in range(2):
for j in range(4):
plt.plot(x.loc[i],y.loc[j],color[i*4+j]+line_style[j])
plt.show()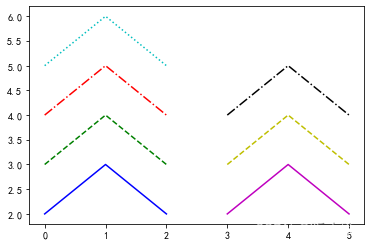
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
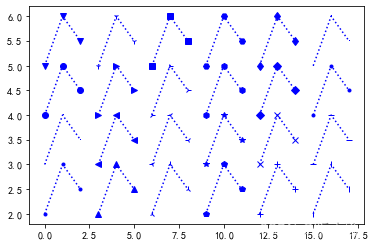
marker=['.',',','o','v','^','<','>','1','2','3','4','s','p','*','h','H','+','x','D','d','|','_','.',',']
dic1=[[0,1,2],[3,4,5],[6,7,8],[9,10,11],[12,13,14],[15,16,17]]
x=pd.DataFrame(dic1)
dic2=[[2,3,2.5],[3,4,3.5],[4,5,4.5],[5,6,5.5]]
y=pd.DataFrame(dic2)
# 循环输出所有"点型"
for i in range(6):
for j in range(4):
plt.plot(x.loc[i],y.loc[j],"b"+marker[i*4+j]+":") # "b"蓝色,":"点线
plt.show()
除了常规的直角坐标系,也可以通过projection方法创建极坐标系下的图表
N = 150
r = 2 * np.random.rand(N)
theta = 2 * np.pi * np.random.rand(N)
area = 200 * r**2
colors = theta
plt.subplot(projection='polar')
plt.scatter(theta, r, c=colors, s=area, cmap='hsv', alpha=0.75);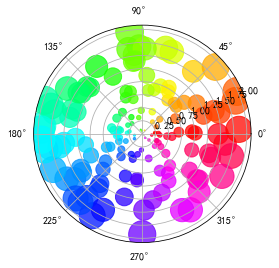
练一练
请思考如何用极坐标系画出类似的玫瑰图
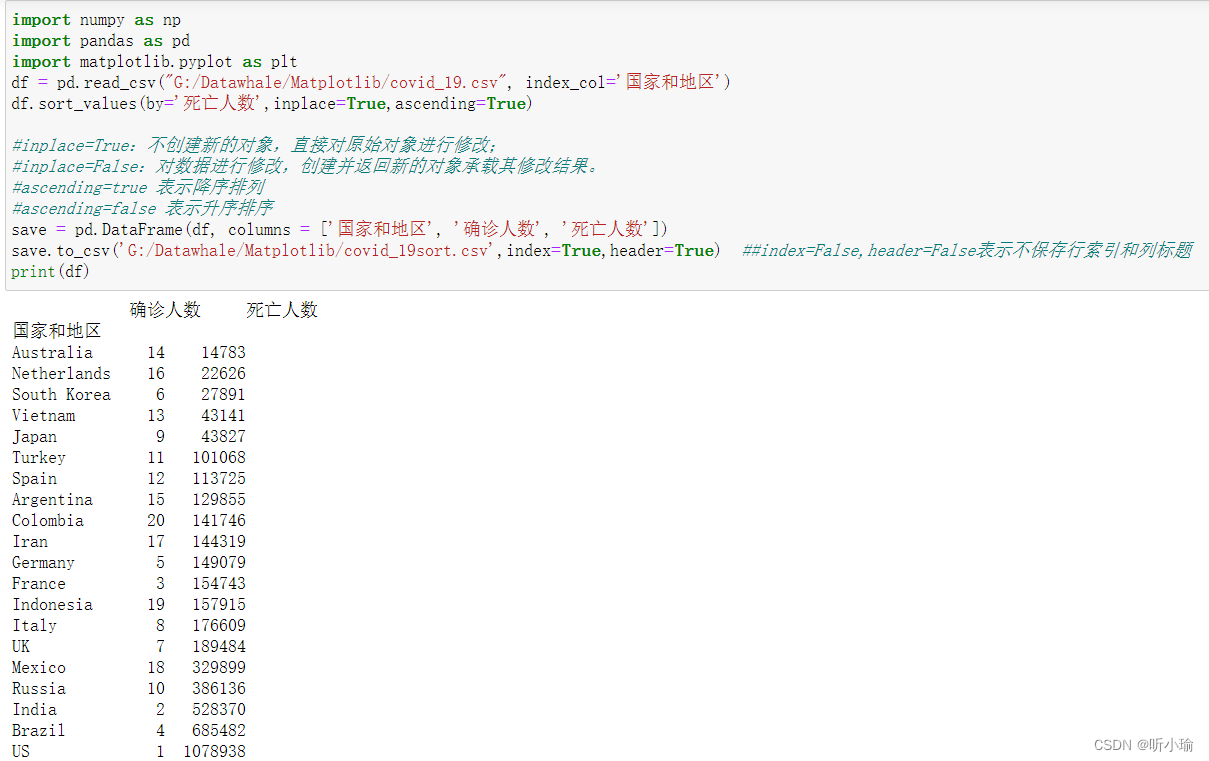
| 确诊 | 国家和地区 | 死亡 |
| 1 | US | 1078938 |
| 2 | India | 528370 |
| 3 | France | 154743 |
| 4 | Brazil | 685482 |
| 5 | Germany | 149079 |
| 6 | South Korea | 27891 |
| 7 | UK | 189484 |
| 8 | Italy | 176609 |
| 9 | Japan | 43827 |
| 10 | Russia | 386136 |
| 11 | Turkey | 101068 |
| 12 | Spain | 113725 |
| 13 | Vietnam | 43141 |
| 14 | Australia | 14783 |
| 15 | Argentina | 129855 |
| 16 | Netherlands | 22626 |
| 17 | Iran | 144319 |
| 18 | Mexico | 329899 |
| 19 | Indonesia | 157915 |
| 20 | Colombia | 141746 |
数据来源:疫情实时大数据
确诊人数前20的国家死亡人数
2022/9/20 11:51:00
先排序:
# 获取数据
ex1 = pd.read_csv('G:/Datawhale/Matplotlib/covid_19sort.csv')
data=ex1[0:20]
# 设置画布
fig = plt.figure(figsize=(12,10))
r=data['死亡人数'].tolist()
# 计算角度
n=data.shape[0]
print(n)
theta=np.linspace(0, np.pi*2, len(r), endpoint=False) # 360度等分成n份
# 极坐标
ax = plt.subplot(111,projection = 'polar')
# 顺时针并设置N方向为0度
ax.set_theta_direction(-1)
ax.set_theta_zero_location('N')
# 在极坐标中画柱形图
ax.bar(theta,r,width=2*np.pi/n,color=np.random.random((n,3)),align="edge" )
#每个柱的顶部显示文本【没调好】
#r1=data['国家和地区'].tolist()
#for angle,height in zip(theta,r1):
# ax.text(angle+0.03,height+105,str(height),fontsize=5)
plt.axis('off') # 不显示坐标轴和网格线
#显示一些简单的中文图例
plt.rcParams['font.sans-serif']=['SimHei'] # 黑体
ax.set_title('疫情确诊人数前20的国家死亡人数',fontdict={'fontsize':20})
#for angle,t,time in zip(theta,r,data['Time'].to_list()):
# ax.text(angle+0.03,t,str(time) )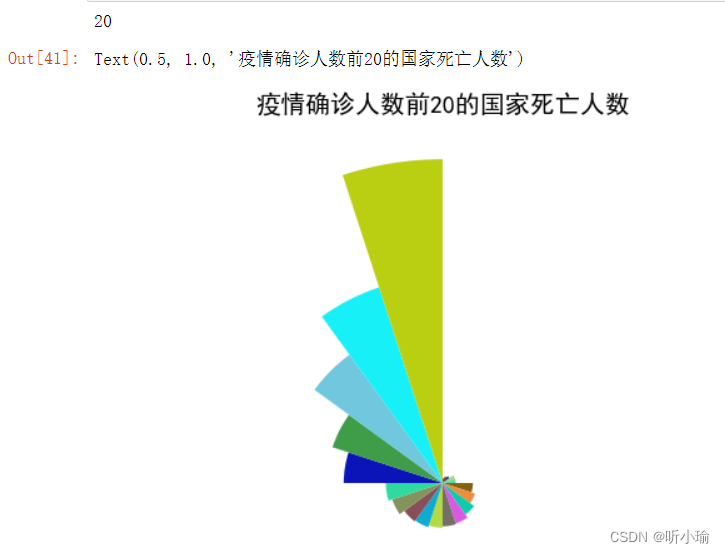
文字标签还未实现。
注:UnicodeDecodeError:'utf-8' codec can't decode byte 0xd5 in position 2: invalid continuation byte 中文报错解决:用python3读csv文件,出现UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 0: invalid con_moledyzhang的博客-CSDN博客
【拓展】
cmap: 颜色图谱(colormap), 默认绘制为RGB(A)颜色空间。
matplotlib.pyplot.imshow(X, cmap=None)
autumn 红-橙-黄
bone 黑-白,x线
cool 青-洋红
copper 黑-铜
flag 红-白-蓝-黑
gray 黑-白
hot 黑-红-黄-白
hsv hsv颜色空间, 红-黄-绿-青-蓝-洋红-红
inferno 黑-红-黄
jet 蓝-青-黄-红
magma 黑-红-白
pink 黑-粉-白
plasma 绿-红-黄
prism 红-黄-绿-蓝-紫-...-绿模式
spring 洋红-黄
summer 绿-黄
viridis 蓝-绿-黄
winter 蓝-绿Choosing Colormaps in Matplotlib www.matplotlib.org.cn
2. 使用 GridSpec 绘制非均匀子图
非均匀包含两层含义 | |
| 第一是指图的比例大小不同但没有跨行或跨列 | 利用 add_gridspec 可以指定相对宽度比例 width_ratios 和相对高度比例参数 height_ratios: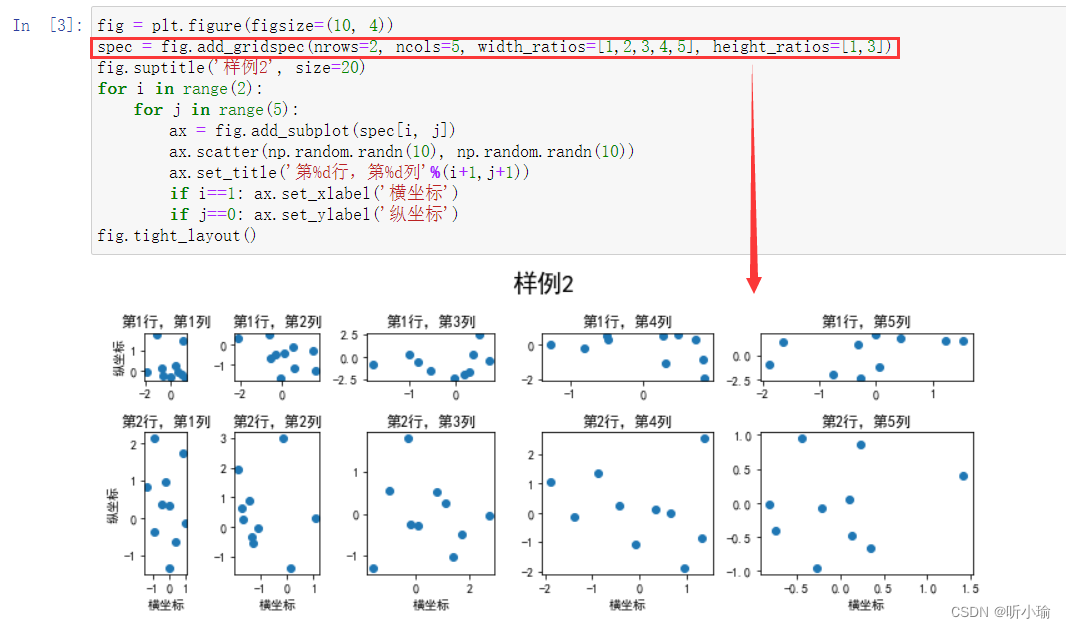 |
| 第二是指图为跨列或跨行状态 | 在上面的例子中出现了
|
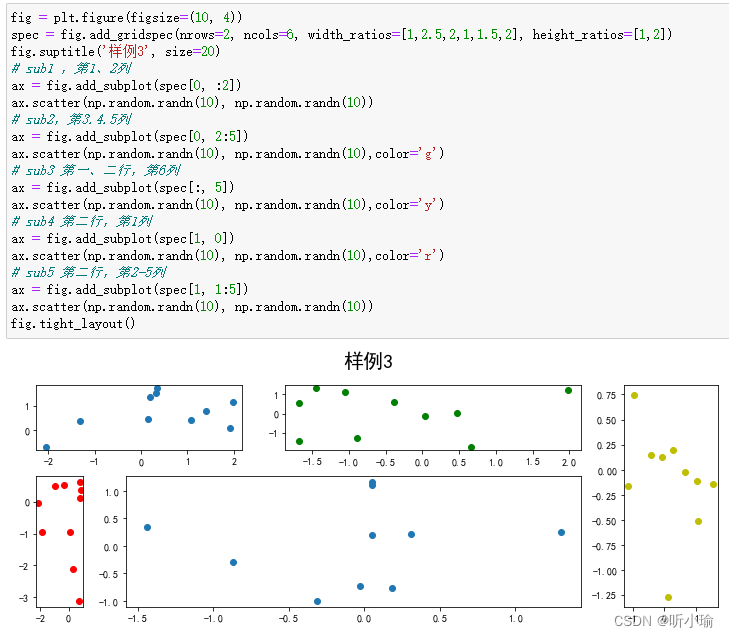
二、子图上的方法
补充介绍一些子图上的方法
常用直线的画法为: axhline, axvline, axline (水平、垂直、任意方向)
使用 grid 可以加灰色网格
使用 set_xscale 可以设置坐标轴的规度(指对数坐标等)
思考题
-
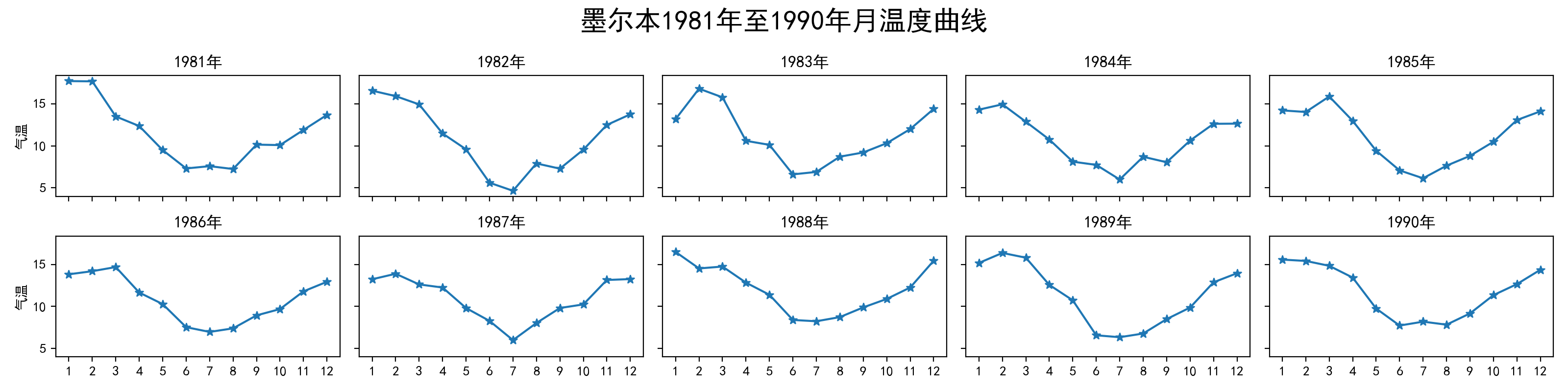
墨尔本1981年至1990年的每月温度情况
数据集来自github仓库下data/layout_ex1.csv
请利用数据,画出如下的图:
path = 'G:/Datawhale/Matplotlib/fantastic-matplotlib-main/data/layout_ex1.csv'
df = pd.read_csv(path)
df['Year'] = pd.to_datetime(df['Time']).dt.year
df['Month'] = pd.to_datetime(df['Time']).dt.month
df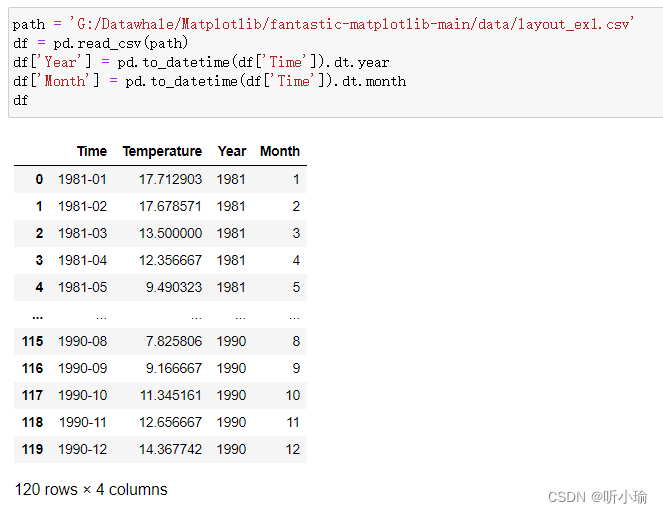
fig,axes = plt.subplots(2,5,figsize =(20,5),sharex=True,sharey=True)
fig.suptitle('墨尔本1981年至1990年月温度曲线',size = 15)
n=0
m=0
m1= 0
for i ,j in df.groupby('Year'):
axes[0][0].set_ylabel('气温')
axes[1][0].set_ylabel('气温')
if m <= 4:
axes[0][m].set_title('{}年'.format(i),size=10)
axes[0][m].plot(j['Month'],j['Temperature'],'*:')
m += 1
else:
axes[1][m1].set_title('{}年'.format(i),size=10)
axes[1][m1].plot(j['Month'],j['Temperature'],'r*:')
axes[1][m1].set_xticks(range(1,13))
m1 += 1
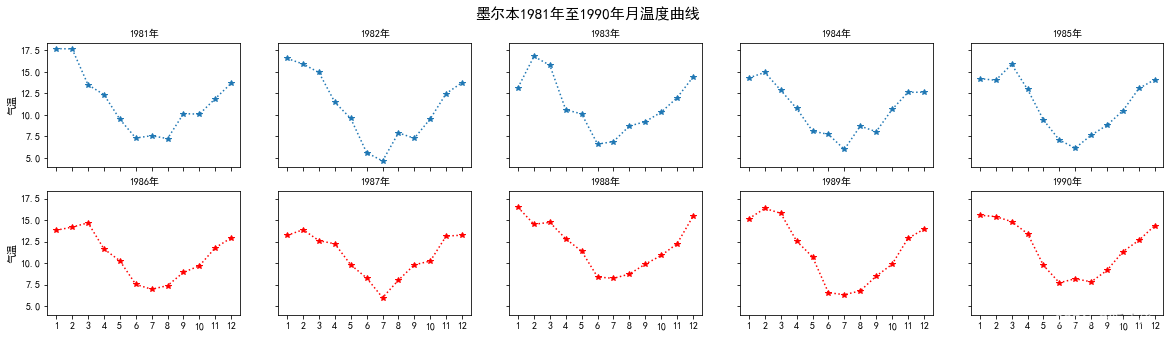
(找到比较简洁易懂的代码修改贴近原题)
-
画出数据的散点图和边际分布
用 np.random.randn(2, 150) 生成一组二维数据,使用两种非均匀子图的分割方法,做出该数据对应的散点图和边际分布图
















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









