







 本文介绍了Python中的BeautifulSoup库用于HTML解析,如何进行POST请求登录网站,以及正则表达式的基础知识和在信息提取中的应用,同时提到了Scrapy爬虫框架的使用。
本文介绍了Python中的BeautifulSoup库用于HTML解析,如何进行POST请求登录网站,以及正则表达式的基础知识和在信息提取中的应用,同时提到了Scrapy爬虫框架的使用。
fh.close()
#若搜索关键词为中文
keywd1=“亚马孙”
keywd1=urllib.request.quote(keywd1) #利用quote对中文进行编码
url1=“http://www.baidu.com/s?wd=”+keywd1
req=urllib.request.Request(url1)
data=urllib.request.urlopen(req).read()
fh=open(“C:/Users/admin/Desktop/a.html”,“wb”) #二进制
fh.write(data)
fh.close()
**②post请求(登录某些网站)**
#post请求
import urllib.request
import urllib.parse
url=“https://www.iqianyue.com/mypost/” #地址
login=urllib.parse.urlencode(
{“name”:“1121640425@qq.com”,“pass”:“123”}
).encode(“utf-8”) #登录数据
req=urllib.request.Request(url,login)
data=urllib.request.urlopen(req).read()
fh=open(“C:/Users/admin/Desktop/a.html”,“wb”)
fh.write(data)
fh.close()
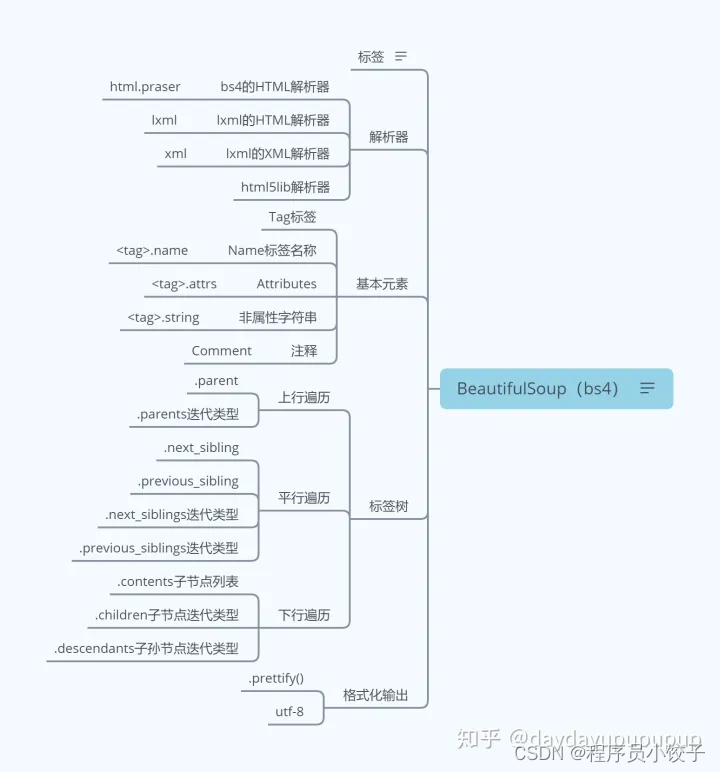
### 三、bs4库
功能:解析、遍历、维护标签树。
...
* 标签名 p
* 属性名称 class
* 属性值 title
3.1 BeautifulSoup支持的解析器
1.Python标准库:内置库、执行速度适中、文档容错能力强;
2.lxml HTML解析器:速度快,文档容错能力强(推荐);
3.lxml XML解析器:速度快,唯一支持xml的解析器;
4.html5lib:最好的容错性、以浏览器方式解析文档,生成HTML5格式的文档。
具体用法:soup=BeautifulSoup(markup,from\_encoding=“编码方式”)
html = “”"
The Dormouse's story
Once upon a time there were three little sisters; and their names were Elsie , Lacie and Tillie; and they lived at the bottom of a well.
...
""" from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') print(soup.prettify()) #输出清晰的树形结构
Beautifu Soup将复杂的HTML文档转化为树形结构,每个节点都是Python对象:
* Tag:标签;
* NavigableString:被包裹在tag内的字符串;
* BeautifulSoup:表示一个文档的全部内容,大部分时候可以看做一个tag对象,支持遍历文档树和搜索文档树的方法;
* Comment:特殊NavigableString,会以特殊格式输出,比如注释类型。
3.2 基本用法
搜索文档树:tag.name\_按顺序获得第一个标签

获取所有标签?
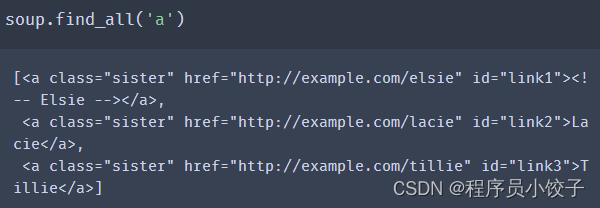
tag.contents可以将tag的子节点以列表方式输出

tag.children,对tag的子节点进行循环
tag.descendants,子孙节点

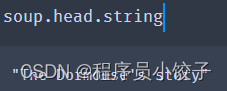
tag.string,获取tag(只有一个子节点)下所有的文本内容
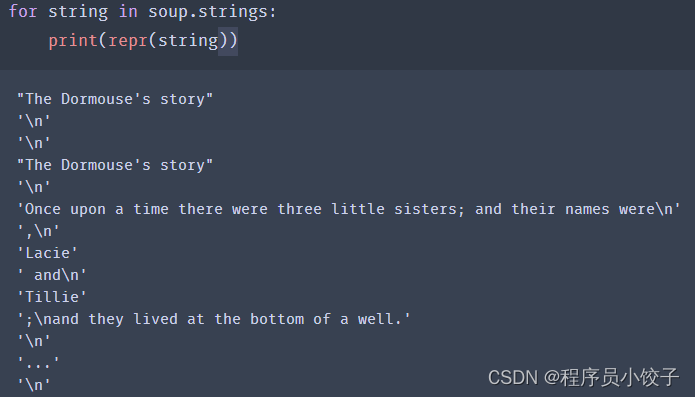
迭代的方式找出所有的文本内容
soup.get\_text() #从文档中获取所有的文字内容

### 四、正则(信息提取)
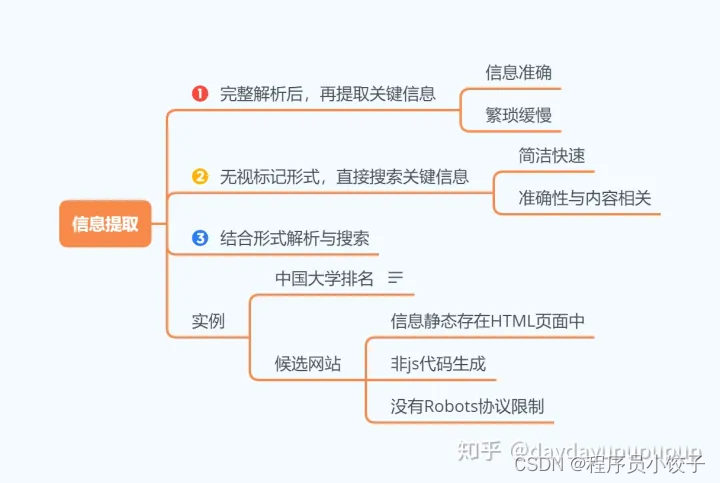
* 中国大学排名案例
import requests
from bs4 import BeautifulSoup
import bs4
#爬取信息
def getHtmlText(url):
try:
res=requests.get(url,timeout=30)
res.raise_for_status()
res.encoding=res.apparent_encoding
return res.text
except:
print(“error”)
return “”
#提取信息
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,“html.parser”)
for tr in soup.find(“tbody”).children:
if isinstance(tr,bs4.element.Tag): #检测tr标签的类型
tds=tr(‘td’)
ulist.append([tds[0].string,tds[1].string,tds[2].string])
#打印信息
def printUnivList(ulist,num): #学习数量
tplt=“{0:10}\t{1:{3}12}\t{2:^9}” #{}域,格式化输出
#表头
print(tplt.format(“排名”,“学校”,“地址”,chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
print(“Suc”+str(num))
#chr(12288)中文空格,解决中英文混排的问题
def mian():
uinfo=[]
url=‘http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html’
html=getHtmlText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)
mian()
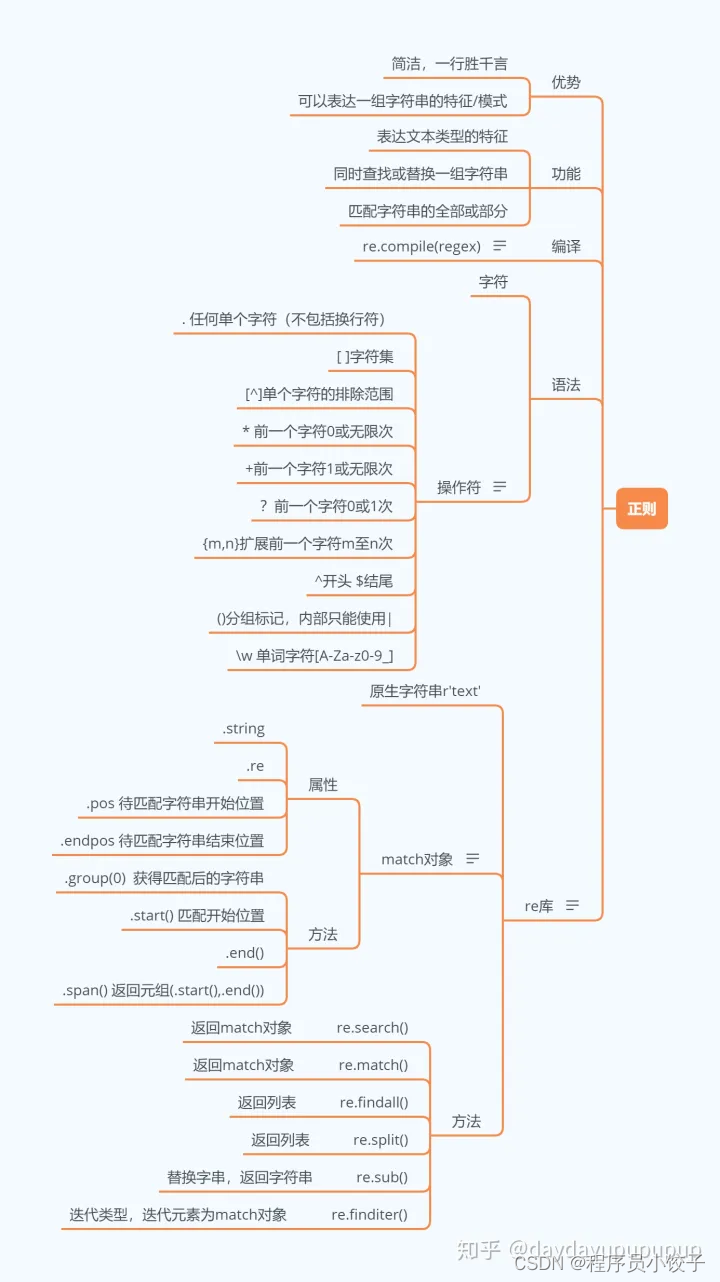
1. 常见的原子类型-正则表达式最基本的单位
a.普通字符(如:a,b,z,0,9)
b.非打印字符(如:制表符\t、换行符\n等)
c.通用字符(可匹配一系列内容,如:可匹配任意一个十进制数\d;可匹配任意一个除十进制数之外的字符\D;可匹配任意一个数字、字母或下划线\w;可匹配任意一个除数字、字母、下划线外的字符\W;可匹配任意一个空白字符\s;可匹配任意一个除空白字符之外的字符\S)

d.原子表(原子表内的原子处于同一地位,如:[jsz])

2.元字符-正则表达式中具有特殊含义的字符
* . 匹配任意字符
* ^ 匹配搜索字符串开始的位置
* $ 匹配字符串结束的位置
* 匹配前面字符的0次、1次、多次
? 匹配前面字符的0次、1次
* 匹配前面字符的1次、多次
{n} 表示左括号前的原子恰好出现n次
{n,} 表示左括号前的原子至少出现n次
{n,m} 表示左括号前的原子至少出现n次,最多出现m次
| 模式选择符,或
() 用于提取内容
3.模式修正符-在不改变正则表达式的前提下,调整匹配结果
re.I #让正则表达式不区分大小写
* re.M #可以进行多行匹配
* re.L #△本地化识别匹配
* re.U #根据unicode字符解析字符
* re.S # 使得 . 可以匹配换行符,通常.无法匹配换行符
4.贪婪模式和懒惰模式
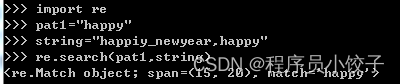
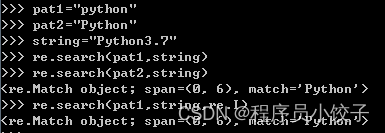
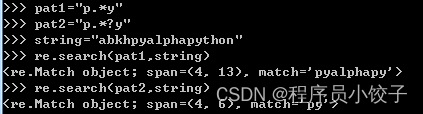
贪婪模式:尽可能多的匹配字符,覆盖的范围更广
pat1=“p.\*y”
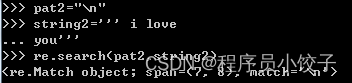
懒惰模式:尽可能少的匹配字符,可以更精确的定位
pat2=“p.\*?y”
### 5.正则表达式函数
* re.search() #从左至右搜索,只会输出首次满足匹配条件的内容
* re.match() #从头搜索符合条件的字符/字符串,待搜索的字符必须在最开始的位置
* re.sub() #替换
* re.complie(pattern).findall(string) #全局匹配函数
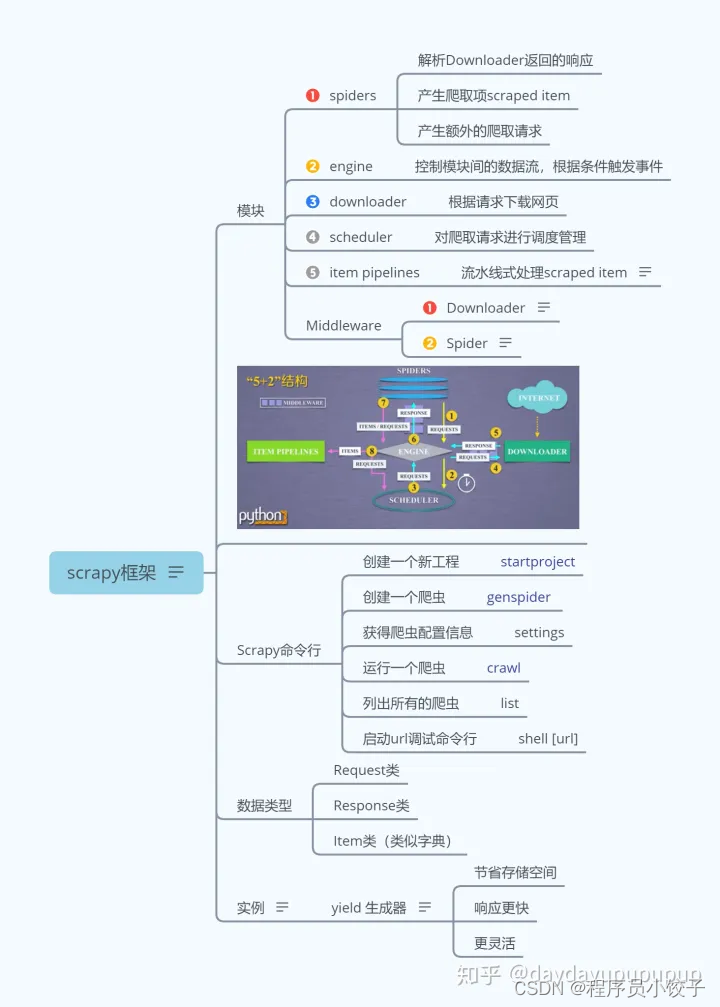
### 五、Scrapy爬虫框架
**读者福利:知道你对Python感兴趣,便准备了这套python学习资料**
>
> 👉[[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]]]( )(**安全链接,放心点击**)
>
>
>
**对于0基础小白入门:**
>
> 如果你是零基础小白,想快速入门Python是可以考虑的。
> 一方面是学习时间相对较短,学习内容更全面更集中。
> 二方面是可以找到适合自己的学习方案
>
>
>
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等习教程。带你从零基础系统性的学好Python!
### 零基础Python学习资源介绍
* ① Python所有方向的学习路线图,清楚各个方向要学什么东西
* ② 600多节Python课程视频,涵盖必备基础、爬虫和数据分析
* ③ 100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论
* ④ 20款主流手游迫解 爬虫手游逆行迫解教程包
* ⑤ 爬虫与反爬虫攻防教程包,含15个大型网站迫解
* ⑥ 爬虫APP逆向实战教程包,含45项绝密技术详解
* ⑦ 超300本Python电子好书,从入门到高阶应有尽有
* ⑧ 华为出品独家Python漫画教程,手机也能学习
* ⑨ 历年互联网企业Python面试真题,复习时非常方便
### 👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

### 👉Python必备开发工具👈
**温馨提示:篇幅有限,已打包文件夹,获取方式在:文末**
### 👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
### 👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

### 👉100道Python练习题👈
检查学习结果。

### 👉面试刷题👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
### 一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

### 二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

### 三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

### 四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

### 五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

### 六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









