







前言:主要内容阐述了深度学习中常见的实验问题与实验技巧,包括消融实验、对比实验的做法及相关指标,数据集的分配问题,深度学习改进实验的顺序,预训练权重对改进和精度的影响,YAML 模型结构图的绘制,训练的可重现性,pytorch 模块内结构图的绘制,创新性,模块加入结构的方法,判断模型收敛与过拟合的方法,模型训练结果,以及上采样和下采样等内容。主要面向深度学习小白初学者,尤其是与图像相关的内容。
目录
1.深度学习常见实验问题与实验技巧
1.1 消融实验的做法
控制变量思想
可分为两种:堆叠模式和组合模式
例如我做了一个yolov11的改进,我改进点有三个(这里简称为①、②、③)。
适用于大部分同学的是堆叠模式:
实验一:基准模型(baseline),也就是原版yolo11
实验二:yolo11+①
实验三:yolo11+①+②
实验四:yolo11+①+②+③
适用于与要求比较高的同学是组合模式:
实验一:基准模型(baseline),也就是原版yolo11
实验二:yolo11+①
实验三:yolo11+②
实验四:yolo11+③
实验五:yolo11+①+②
实验六:yolo11+①+③
实验七:yolo11+②+③
实验八:yolo11+①+②+③
1.2 对比实验的做法
在所有实验开始前,先选择部分模型控制好超参数进行跑 baseline,假如我选择了yolov5,yolov7 volov8,假如最高的是 yolov7,那么我可以选择使用 yolov7进行改进,这样就避免在消融实验做完后,上面要求需要增加跟其他模型的对比的时候发现其他模型比改进后的模型精度都要高的情况!
不同论文同数据集的对比实验应该怎么做?如果没有别人的源码,一般情况下是比较难复现,这种情况一般都是引用。对于超参数问题一般不需要理会,可以理解为每个论文都在适合自己模型的超参数上训练和测试。
需要注意:消融和对比实验中的超参数设定,无论是学习率还是 batchsize 还是 epoch 都必须得一致!保持实验环境和机器的一致性(涉及到随机种子的问题)
1.3 消融实验和对比实验的指标
最常用:Param,FLOPs,Size,FPS,Precision,Recall, mAP50,mAP75,mAP50-95 (前四个为性能指标,其余后面的是精度指标)
还有一种(精度指标和COC0 指标选择其一):COC0 指标 如下图

最常用指标
- Param(参数数量):指模型中可训练参数的总数。参数数量直接反映了模型的复杂度,模型的参数越多,通常意味着它具有更强的表达能力,但同时也会增加模型的训练时间和内存需求。例如,一个具有数百万参数的大型模型可能能够学习到更复杂的特征,但在资源有限的环境中可能难以部署和训练。
- FLOPs(浮点运算次数):即每秒浮点运算次数,用于衡量模型在处理输入数据时所需的计算量。FLOPs 越高,表明模型在推理过程中需要进行更多的计算操作,这会影响模型的运行效率和实时性。对于一些对实时性要求较高的应用场景,如自动驾驶、实时视频监控等,低 FLOPs 的模型更具优势。
- Size(模型大小):表示模型文件占用的存储空间大小。较小的模型大小不仅便于存储和传输,还能在资源受限的设备(如移动设备、嵌入式设备)上更高效地运行。在实际应用中,模型大小是一个重要的考虑因素,特别是对于需要在多个设备上部署的模型。
- FPS(每秒帧数):主要用于衡量模型在处理视频流或连续图像数据时的实时处理能力。FPS 越高,模型能够处理的图像帧数就越多,从而提供更流畅的处理效果。在实时视频处理任务中,如视频目标检测、视频跟踪等,高 FPS 是保证系统性能的关键指标之一。
- Precision(精确率):定义为预测为正例的样本中实际为正例的比例。它反映了模型预测的准确性,即模型在识别出的正例中有多少是真正的正例。例如,在目标检测任务中,精确率表示检测出的物体中有多少是正确识别的。
- Recall(召回率):指实际为正例的样本中被正确预测为正例的比例。召回率衡量了模型对正例的捕捉能力,即模型能够找到多少真正的正例。在一些应用场景中,如医疗诊断、安全监控等,高召回率是非常重要的,因为我们希望尽可能不漏掉真正的正例。
- mAP50(平均精度均值,IoU 阈值为 0.5):平均精度均值(mAP)是目标检测任务中常用的评价指标。mAP50 表示在交并比(IoU)阈值为 0.5 时的平均精度均值。IoU 是衡量预测框与真实框之间重叠程度的指标,当 IoU 大于等于 0.5 时,认为预测框是一个有效的检测结果。mAP50 主要关注模型在检测目标时的准确性,在 IoU 阈值为 0.5 的情况下,综合评估模型对不同类别目标的检测性能。
- mAP75(平均精度均值,IoU 阈值为 0.75):与 mAP50 类似,mAP75 是在 IoU 阈值为 0.75 时的平均精度均值。相比 mAP50,mAP75 对检测框的准确性要求更高,因为 IoU 阈值从 0.5 提高到了 0.75。这意味着模型需要更精确地定位目标物体,才能获得较高的 mAP75 分数。mAP75 更能反映模型在精确检测目标方面的能力。
- mAP50 - 95(平均精度均值,IoU 阈值从 0.5 到 0.95 以 0.05 步长):mAP50 - 95 是一个综合评估指标,它计算了在 IoU 阈值从 0.5 到 0.95 以 0.05 步长变化时的平均精度均值。这个指标能够更全面地反映模型在不同 IoU 阈值下的性能,对模型的检测精度和稳定性进行了更细致的评估。它考虑了不同程度的目标重叠情况,能更准确地衡量模型在各种复杂场景下的表现。
训练完成后可看精度指标(最右边四个)是否平缓(收敛)

COCO 指标
COCO(Common Objects in Context)指标是在 COCO 数据集上进行目标检测、实例分割等任务时常用的评价指标体系。COCO 数据集包含了大量的自然图像,涵盖了多个常见的物体类别,具有丰富的标注信息。
COCO 指标与上述提到的一些通用指标有相似之处,但也有其独特的特点和计算方式。例如,COCO 指标中的 AP(Average Precision)与 mAP 类似,用于衡量模型在不同 IoU 阈值下的平均精度。不过,COCO 指标在计算 AP 时,考虑了更多的细节和场景,并且对不同类别的目标进行了更细致的评估。
COCO 指标体系还包括其他一些重要的指标,如 AR(Average Recall),用于衡量模型在不同 IoU 阈值下的平均召回率;以及针对不同尺度目标的检测指标,如 AP_small、AP_medium 和 AP_large,分别反映了模型对小、中、大尺度目标的检测性能。
这些指标在消融实验和对比实验中起着关键作用,通过对这些指标的分析和比较,可以深入了解模型的性能特点,发现模型的优势和不足,从而有针对性地对模型进行改进和优化。同时,这些指标也为不同模型之间的公平比较提供了客观依据。
轻量化需要看参数量和计算量,然后精度的跌幅在一个点左右
FPS不是计算量和参数量下降就提升,FPS还要看结构和模型的复杂度
提点的情况下,不要大力出奇迹,参数量和计算量最好20%增幅内
1.4 数据集分配问题
建议尽量分训练、验证、测试
比例一般为6:2:2或者7:1:2
训练集用于模型的学习和参数优化,它是模型训练的基础。在训练过程中,模型通过对训练集的学习来调整自身的参数,以适应任务的要求。验证集则用于评估模型在训练过程中的性能,帮助我们确定模型是否过拟合或欠拟合。通过验证集的反馈,我们可以调整模型的超参数,从而提高模型的泛化能力。测试集则用于评估模型在真实场景下的性能,它独立于训练集和验证集,用于检验模型的最终效果。
2.深度学习改进实验顺序
改进的方案一般有以下内容:
1.替换 backbone.(例如 fasternet,efficientViT...)---成本相比低,掉点率较高
2.改进 backbone.(在 backbone 上添加注意力,更换主干模块,例如使用 Fasternet 中的 FasterBlock
改进 C2f)---成本相比高
3.替换 neck.(例如 BiFPN 替换 PAFPN...)---成本相比低,掉点率相比高
4.改进 neck.(改进 neck 中的融合方式,添加注意力...)---成本相比高
5.改进检测头(DyHead,轻量化,解耦头...)--提点率相比高
6.改进损失函数.(Focalloss,sildeloss,loU...)--成本最低,可作为额外增加堆工作量、不额外增加推理时间、不增加模型大小--只要提点,白赚
7.模型剪枝、蒸馏.---对模型没有任何影响,模型定型后,堆工作量很大,可做很多对比实验
8.数据增强
推荐顺序:
1.替换 backbone.(例如 fasternet, efficientViT...)---成本相比低,掉点率较高
2.替换 neck.(例如 BiFPN 替换 PAFPN...)---成本相比低
3.改进 backbone.(在 backbone 上添加注意力,更换主干模块,例如使用 Fasternet 中的 FasterBlock
改进 C2f)---成本相比高,掉点率相比高
4.改进 neck.(改进 neck 中的融合方式,添加注意力...)---成本相比高,
5.改进检测头(DyHead,轻量化,解耦头...)---提点率相比高
6.改进损失函数.(Focalloss,sildeloss.loU...)--成本最低,无损,可作为额外增加堆工作量、不额外增加推理时间、不增加模型大小--只要提点,白赚
7.模型剪枝、蒸馏.---对模型没有任何影响,无损,模型定型后,堆工作量很大,可做很多对比实验
多尝试,做实验,看效果
3.深度学习中预训练权重对改进和精度的影响
1.预训练权重对模型的影响。
一般情况下,载入预训练权重,模型训练效果会更好,精度要高,收敛速度快。
更庞大的数据集比体量小的数据集的预训练权重效果要好(网络能学习到的特征就越来越多)
2.改进模型的时候,在什么情况下可以使用预训练权重,在什么情况下不使用预训练权重?
目标检测有Backbone, Neck,Head。
第一种情况,可以使用预训练权重:只改Head的情况下(可选择Head+剪枝+蒸馏去丰富工作量),拉高整体精度
第二种情况,可以使用预训练权重:改动Neck或Head(需要做变动修改预训练权重),拉高整体精度
第三种情况,不使用预训练权重:改动Backbone(提取特征用)(因为条件不统一了,改进模型与改进前模型的起步条件不一样了)
3.改进不推荐加预训练权重
4.模型改了结构后,可以指定去加载预训练权重,有可能很多对不上
5.在实验环境变量中,都没有加预训练权重,改进的模型有提升则证明有效
6.一般建议不加预训练权重
4.画YAML模型结构图
配置文件上的结构图相对好画,不同于在代码去搭建网络的结构图。接下来介绍一下在配置文件上的结构图绘制
也就是个连线游戏,例如下面的yolov5的结构图,主要看第一个参数from。
from为-1表示继承自上一层,-2表示继承自上上一层,其他数字表示接入自其它数字的层。
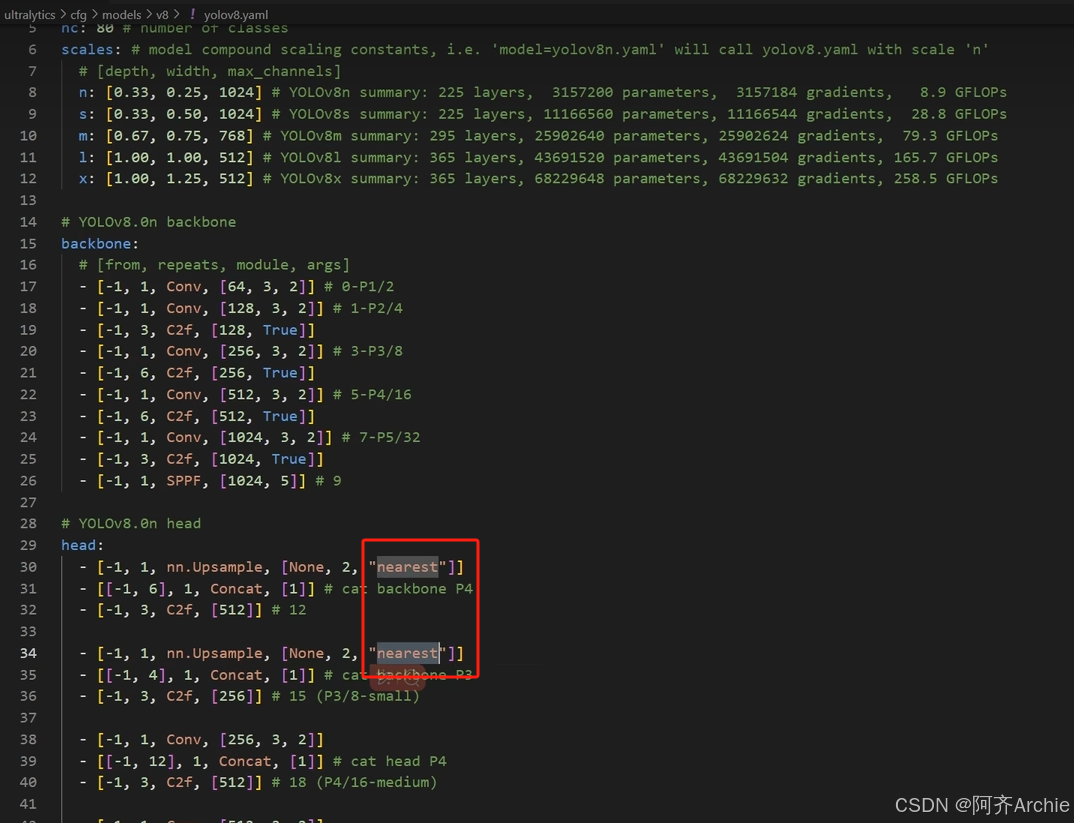
主干backbone提供不同下采样尺度的一个特征图,例如0-P1/2表示2倍下采样;7-P5/32表示32倍下采样,同时7、8、9层都是32倍下采样,32倍下采样一般都取第9层也就是最后的输出
yolo系列是有5个不同的下采样倍数的特征图,如下2倍、4倍...到32倍(例如输入图像是640*640,32倍就是640/32),需要的是特征图的最后输出
0-P1/2
1-P2/4
2-P3/8
3-P4/16
4-P5/32
在对模型主干修改改进时,主干的序号是从第四层开始


如下为yolov5的结构图

例如,下面的-1就是直接顺着连线,配合上图结构图来看

例如这个【-1,6】

配合上图结构图来看,就是下面这个部分,第12层有来自11层(-1)也有第6层

如下为yolov5.yaml文件,这个 YAML 文件完整地定义了 YOLOv5 模型的结构,包括骨干网络、头部以及相关参数。通过这些配置,可以构建出用于目标检测的 YOLOv5 模型。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv5 object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/yolov5
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 1024]
l: [1.00, 1.00, 1024]
x: [1.33, 1.25, 1024]
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C3, [128]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C3, [256]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 9, C3, [512]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C3, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv5 v6.0 head
head:
- [-1, 1, Conv, [512, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C3, [512, False]] # 13
- [-1, 1, Conv, [256, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C3, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 3, C3, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C3, [1024, False]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
参数部分
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 1024]
l: [1.00, 1.00, 1024]
x: [1.33, 1.25, 1024]
nc:表示模型要检测的类别数,这里设置为 80。scales:定义了不同模型规模的缩放常数。每个规模(如n、s、m、l、x)都有对应的深度(depth)、宽度(width)和最大通道数(max_channels)。这些常数用于调整模型的大小和复杂度。
骨干网络(Backbone)部分
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C3, [128]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C3, [256]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 9, C3, [512]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C3, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 9
这部分定义了 YOLOv5 的骨干网络结构。每个列表项表示一个网络层,格式为[from, number, module, args]:
from:表示当前层输入来自哪一层。-1表示来自上一层。number:表示该层的重复次数。module:表示要使用的模块类型,如Conv(卷积层)、C3(自定义的 C3 模块)、SPPF(空间金字塔池化 - 快速版)。args:表示模块的参数。例如,Conv的参数[64, 6, 2, 2]表示输出通道数为 64,卷积核大小为 6,步长为 2,填充为 2。
头部(Head)部分
# YOLOv5 v6.0 head
head:
- [-1, 1, Conv, [512, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C3, [512, False]] # 13
- [-1, 1, Conv, [256, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C3, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 3, C3, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C3, [1024, False]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
这部分定义了 YOLOv5 的头部结构,用于检测目标。头部主要包括上采样、连接和检测等操作:
- 上采样和连接操作:通过上采样将高分辨率特征图与低分辨率特征图进行连接,以融合不同尺度的特征信息。
Detect模块:最后将不同尺度的特征图输入到Detect模块中进行目标检测,输出检测结果。[17, 20, 23]表示输入来自第 17、20 和 23 层,nc表示类别数。
如果结构复杂,也可以采用如下方式所示画的表示结构
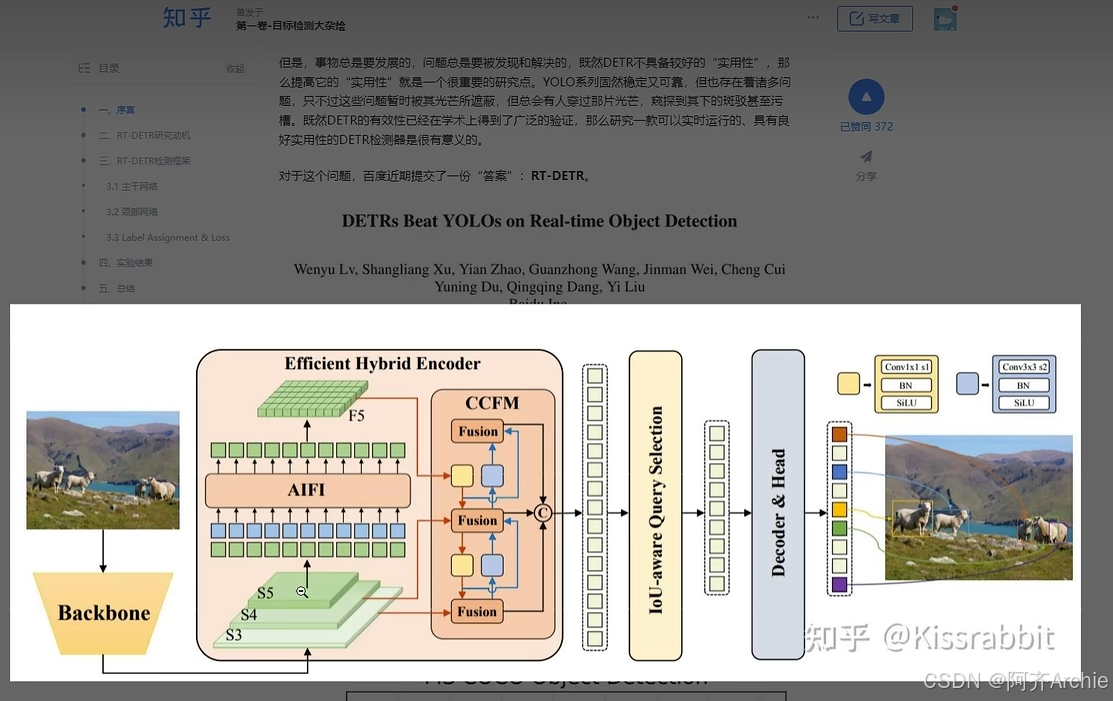
5.深度学习中训练的可重现性
- 随机种子固定了,不代表百分之百能重现结果。
- 有 Upsample(等非确定性算法)模块训练可重现性较低。
- 训练可重现性需要设置 pytorch,random,numpy 的随机种子。
- 训练可重现性对于多线程 DataLoader有一定设置的要求。
- 跨设备可复现性基本不可能实现。
- 并行算法的随机性一定程度上会影响训练可复现性。
- Pytorch中设置确定性算法时大概率会导致训练变慢。
- cudnn.benchmark在固定尺寸输入的时候会加速训练,但是会让训练可复现性失效。
6.画pytorch模块内的结构图
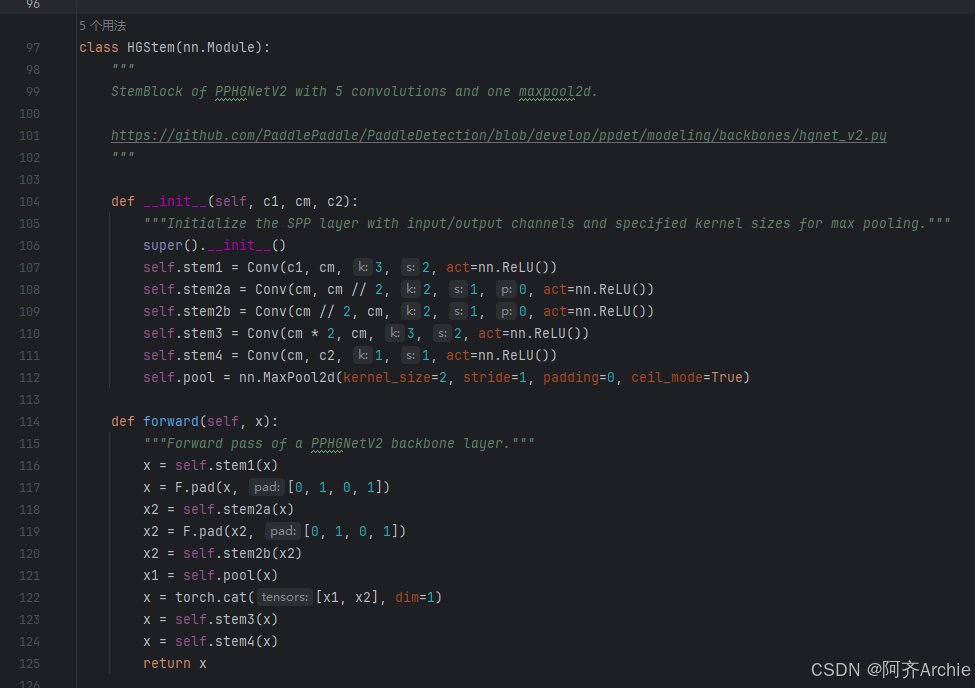
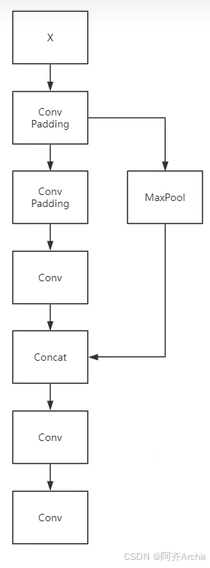
如下所示,是HGStem模块的结构图
结合程序和模块结构图你可以对照理解一下,然后可以去美化它
有X、X1、X2,下面的forward是画图的走向,上面的init是具体是什么内容,需要注意取特征图(X、X1、X2)的最后一层输出
如果有一些比较很复杂的模块,比如复合函数都写三四十行,这些模块可以不必要细化了,引用论文的就可,或者说就直接写描述一下来自xxx
7.创新性
加注意力机制创新性较弱,除非这个注意力机制是新提的,模块也是最新的模块(发论文)
或者能提点,可以作为工作量
尽量少碰注意力机制,第二个少碰的就是backbone
例如最近的多模态,比较新颖的图
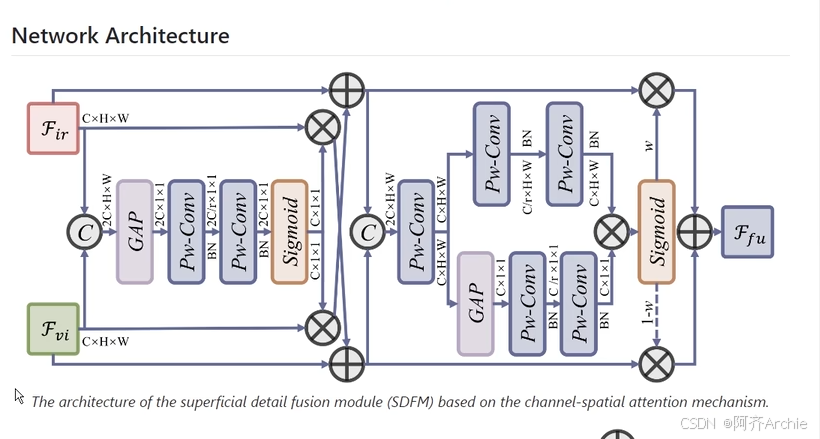
再例如,今天看到的一个论文挺适合自己的这个结构的,拿过来稍微改一下融合到自己的模型里,就提出了新的一个结构
描述上要有理有据,例如,根据xxx缺点,xxx去改进,改进的目的可以xxx,提出了xxx结构,解决了xxx问题
写的结论源于实验结果,内容来引导模块
难在结构是否提点,不是难在创新结构,可以拆拆补补能解决问题即可
总的改进能提升1-2个点,最好是至少2个点左右,才有可能发paper,或者提升很小但创新性很高,所以不是仅看提升多少就能发paper
工作量可以看一下自己想投paper的期刊文章的工作量
8.写模块加入结构里
如下为举例如何自己写的模块加入结构里
在block.py文件里
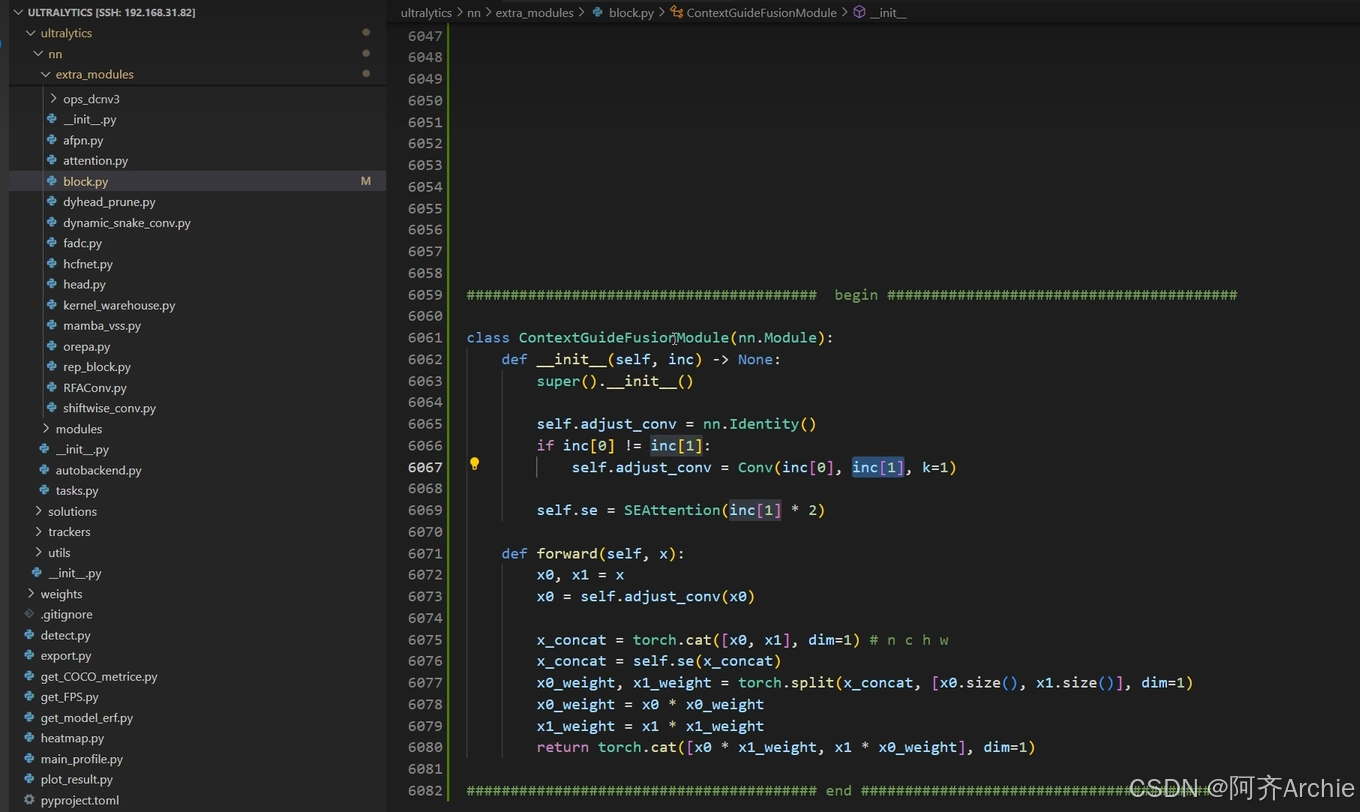
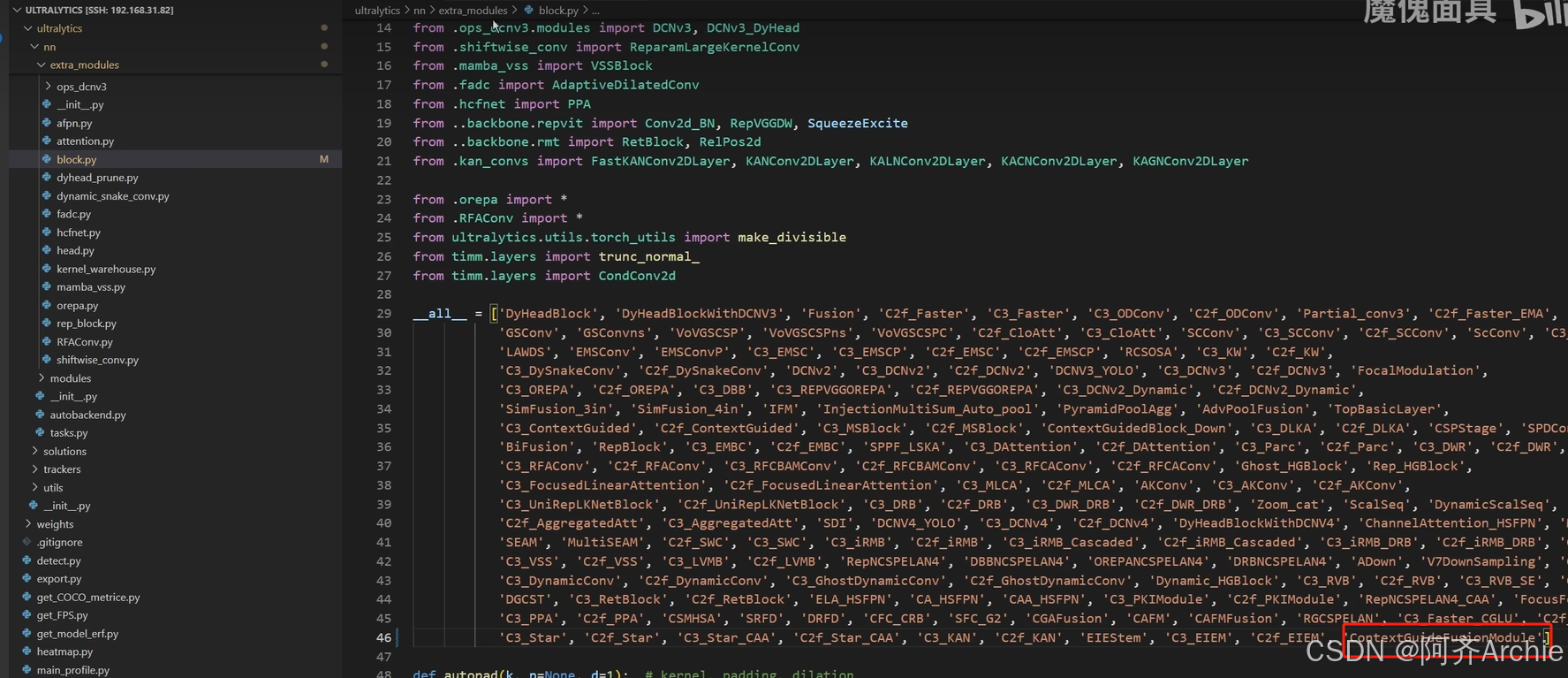
然后在task.py文件里
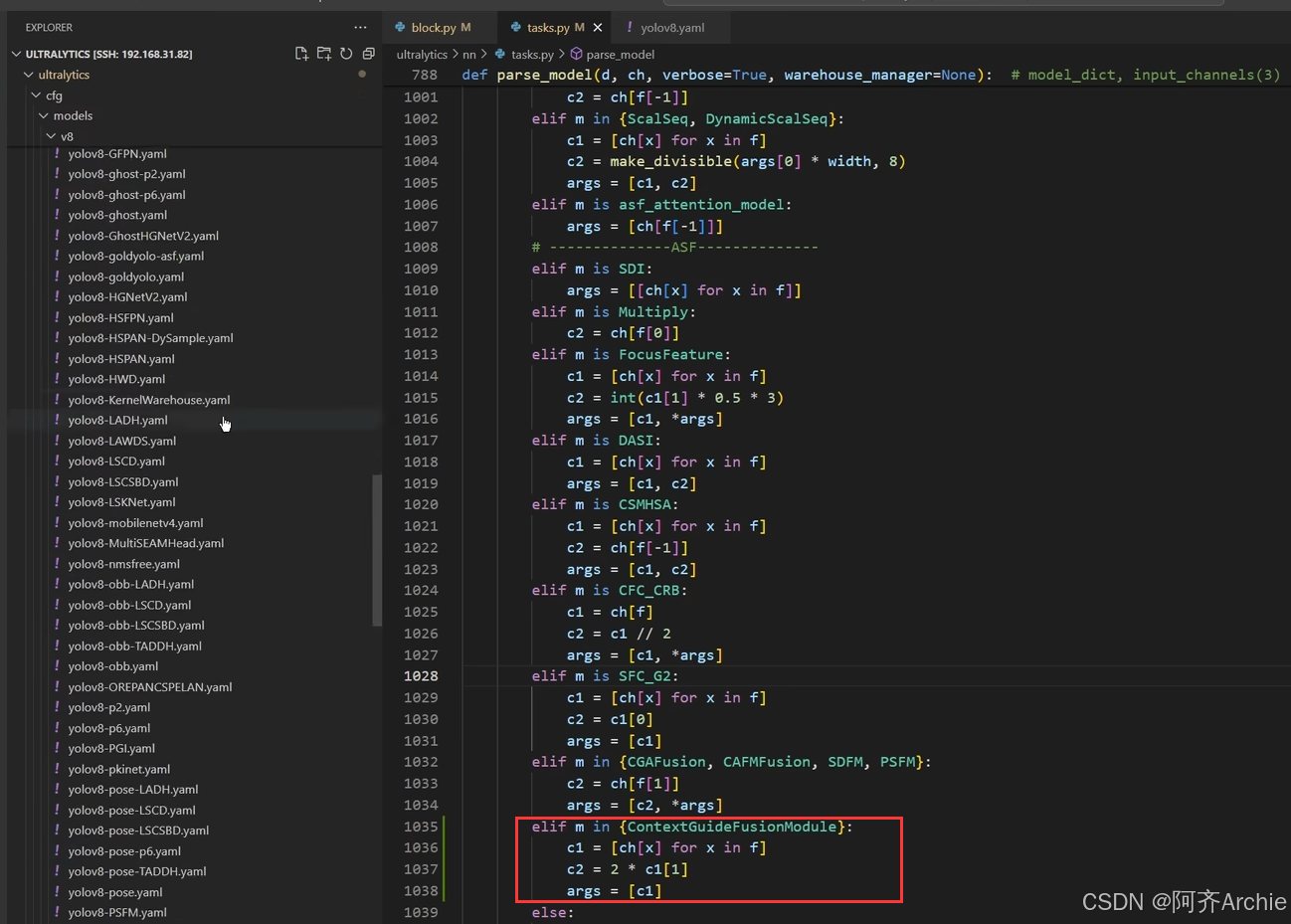
然后新建一个yaml文件
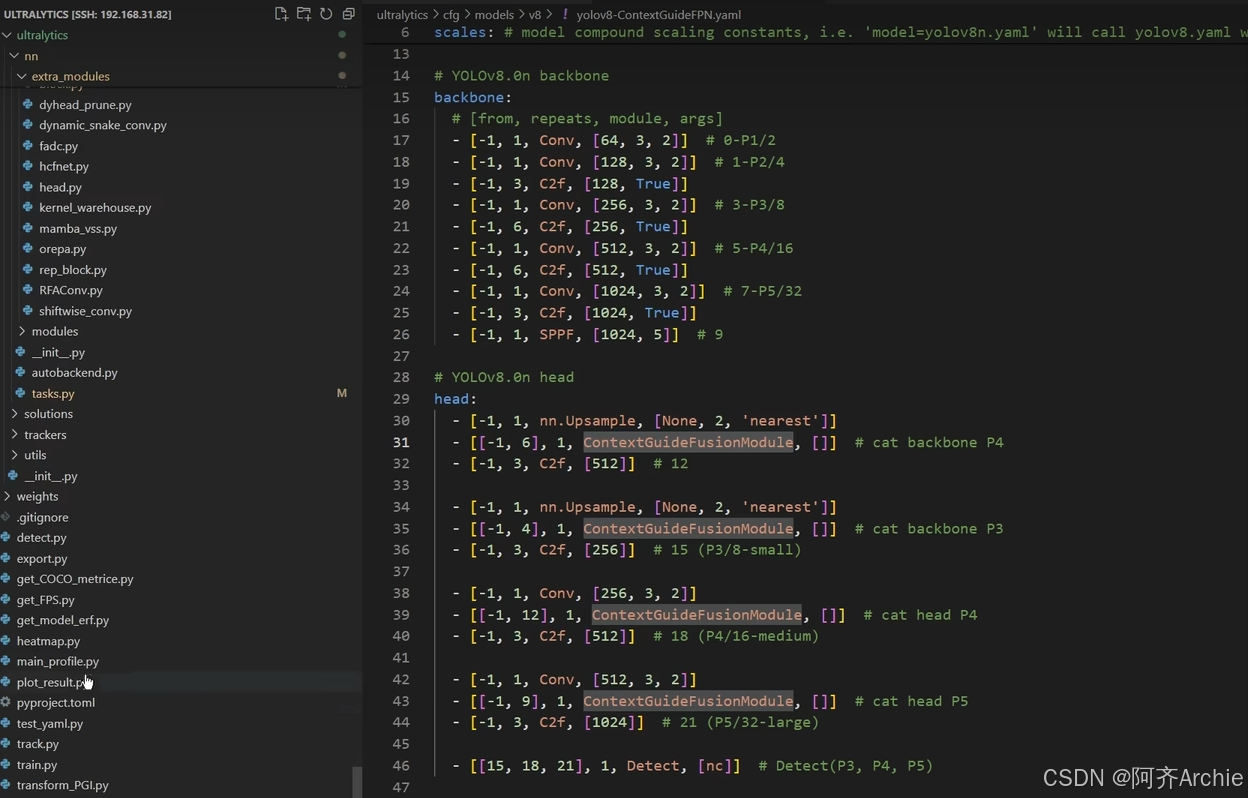
然后main.py引用这个yaml文件运行
9.判断模型已经收敛,模型过拟合
以目标检测为例,来判断模型是否已经收敛
判断依据来看精度曲线
如下图
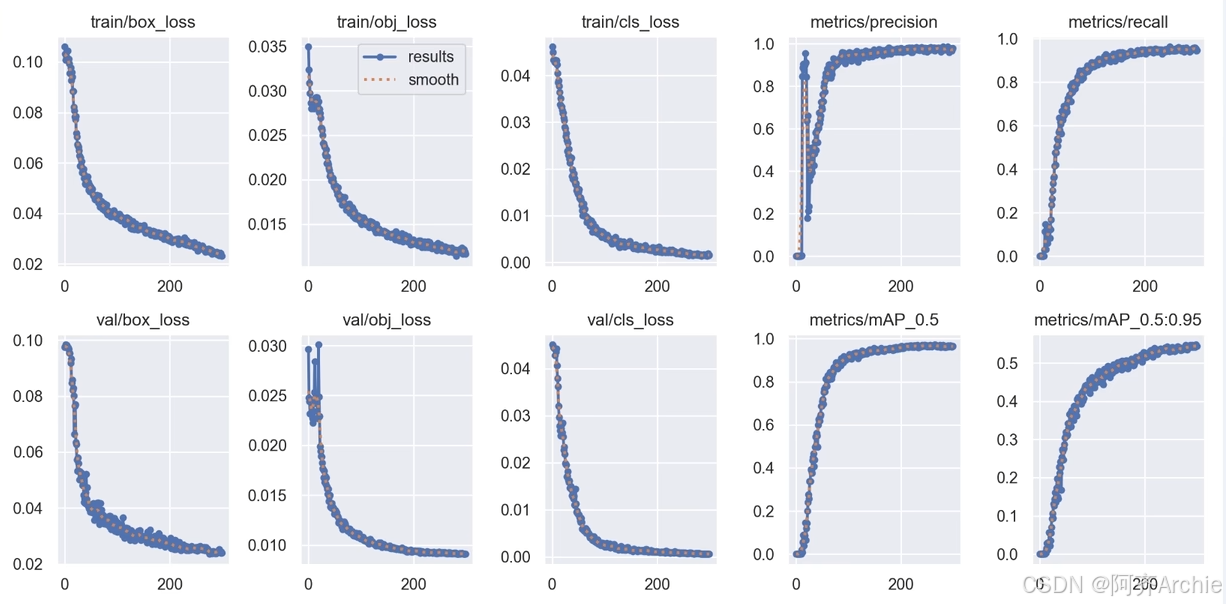
这个图map0.5收敛了(没有上涨趋势),但是map0.5-0.95没有收敛 (有上涨趋势)
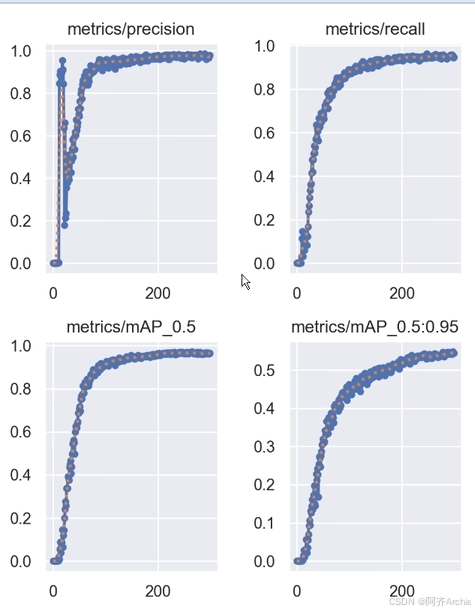
下图都是收敛
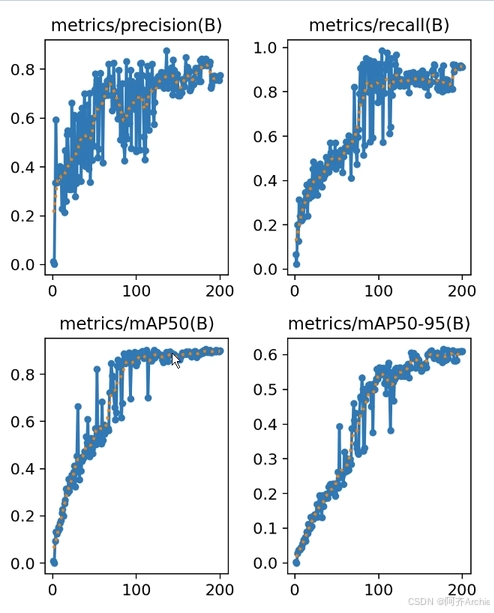
模型过拟合分为两种,一种是曲线上过拟合
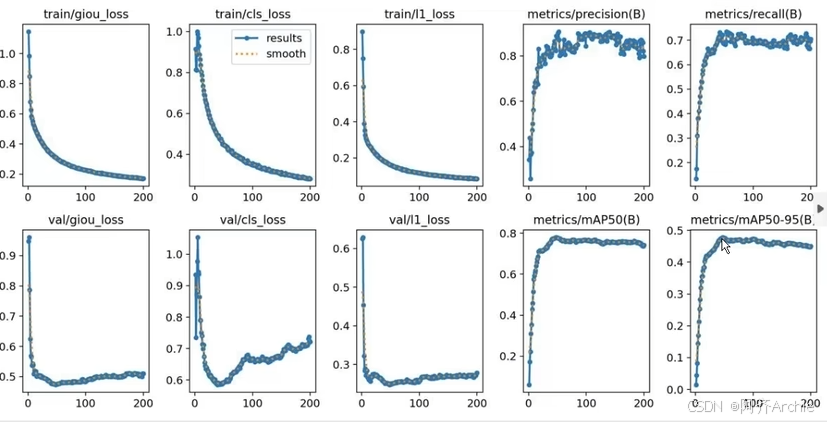
另一种是模型的过拟合,例如yolov8s要比yolov8m的精度高,这就是模型上的过拟合(就是反而用大的模型跑数据集反而精度低)
10.模型训练结果
训练刚开始的信息是在default.yaml文件和main.py文件指定
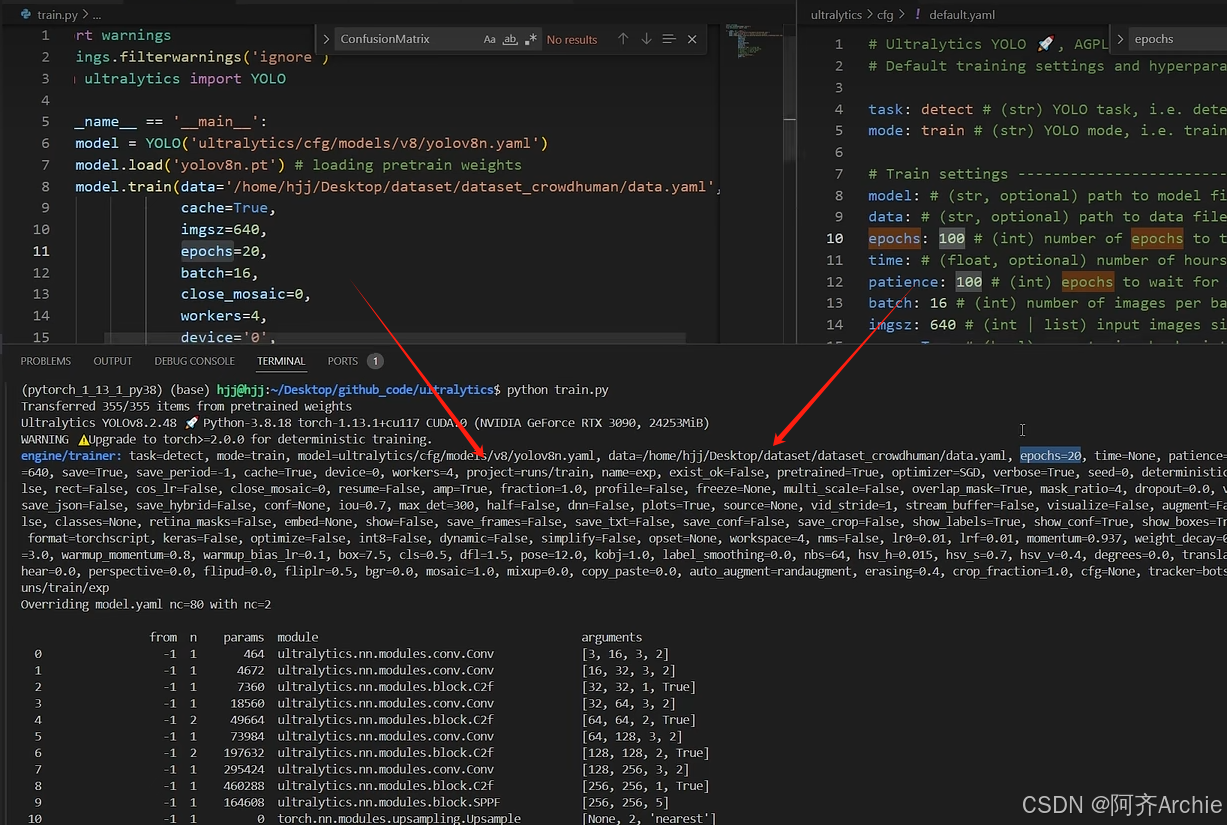
训练过程的精度是验证集的
训练过程的文件大小是不准确的,是包含一些梯度信息、优化器信息在的
训练完成后才会显示真实的size如下
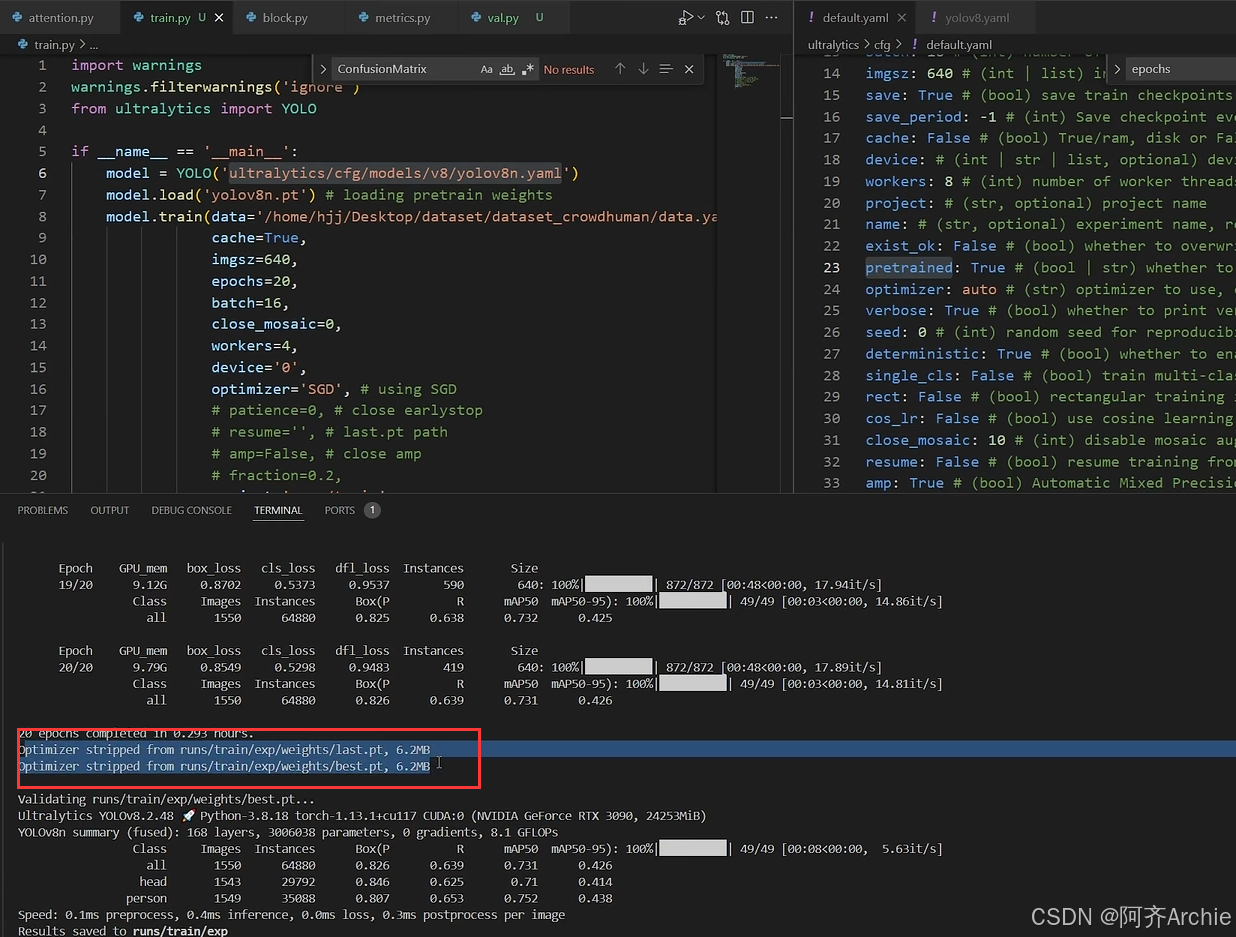
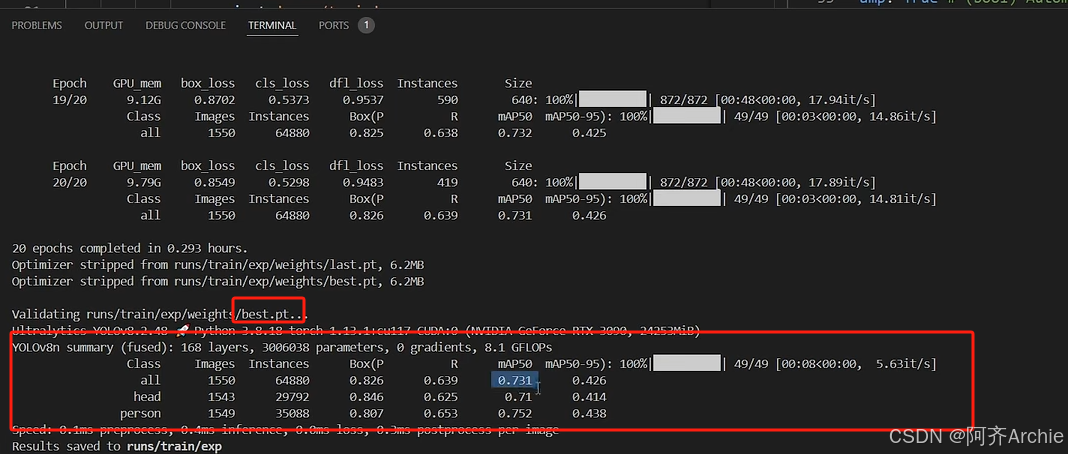
最后的指标是来自best.pt
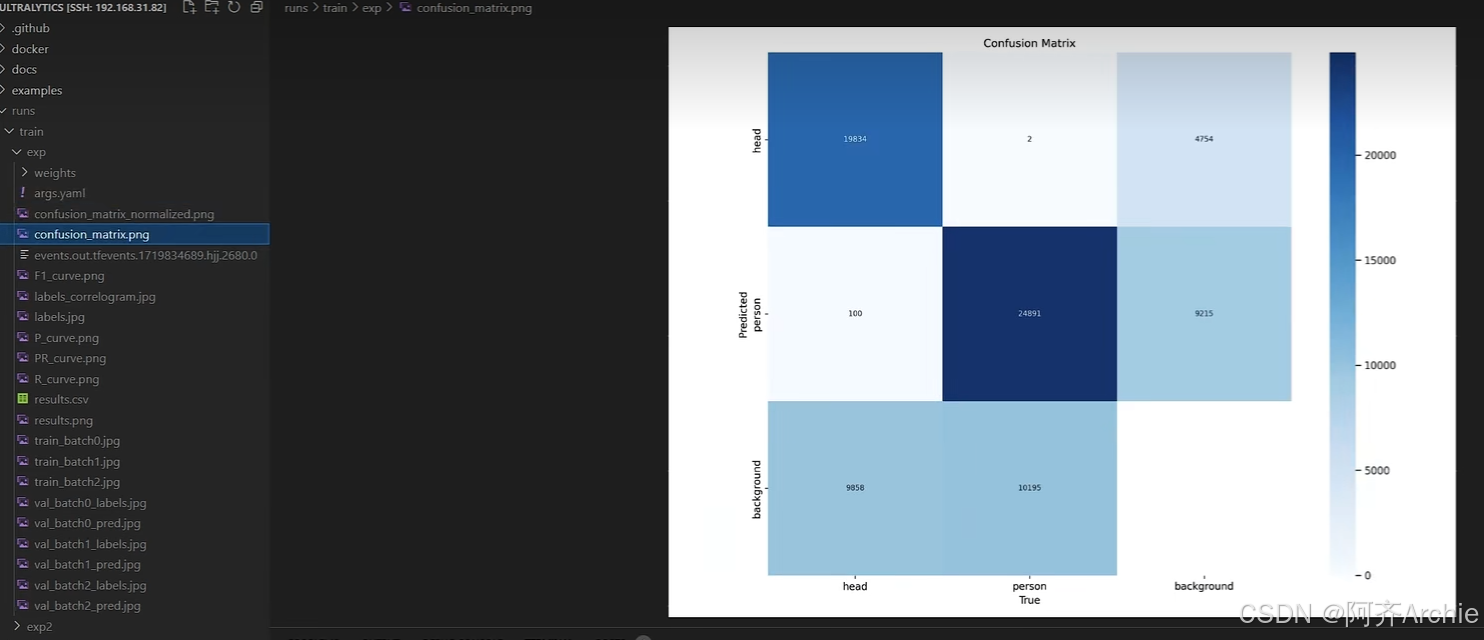
如下图为混淆矩阵
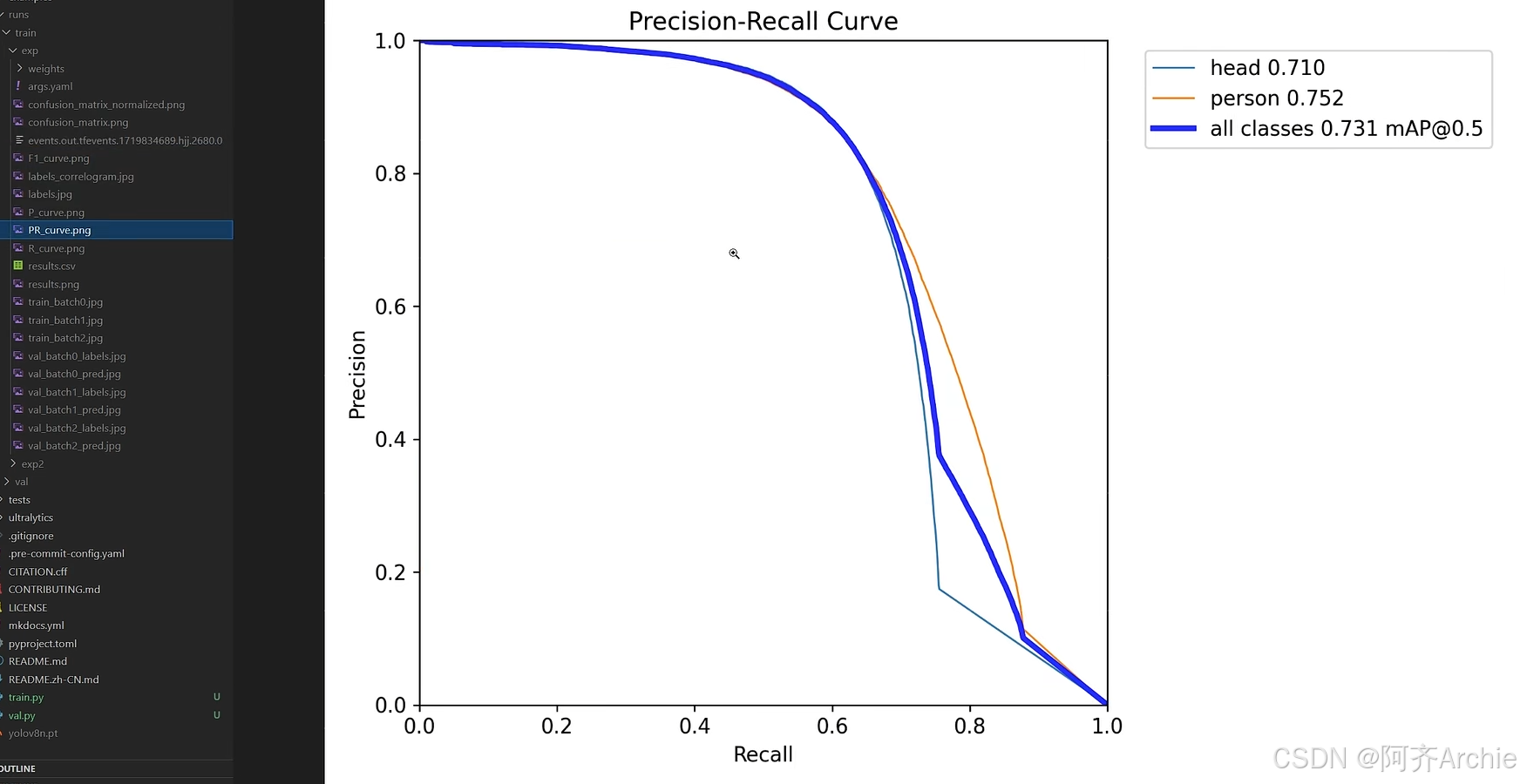
如下是PR曲线图
 如下为F1曲线,如下在0.318置信度达到最高0.72
如下为F1曲线,如下在0.318置信度达到最高0.72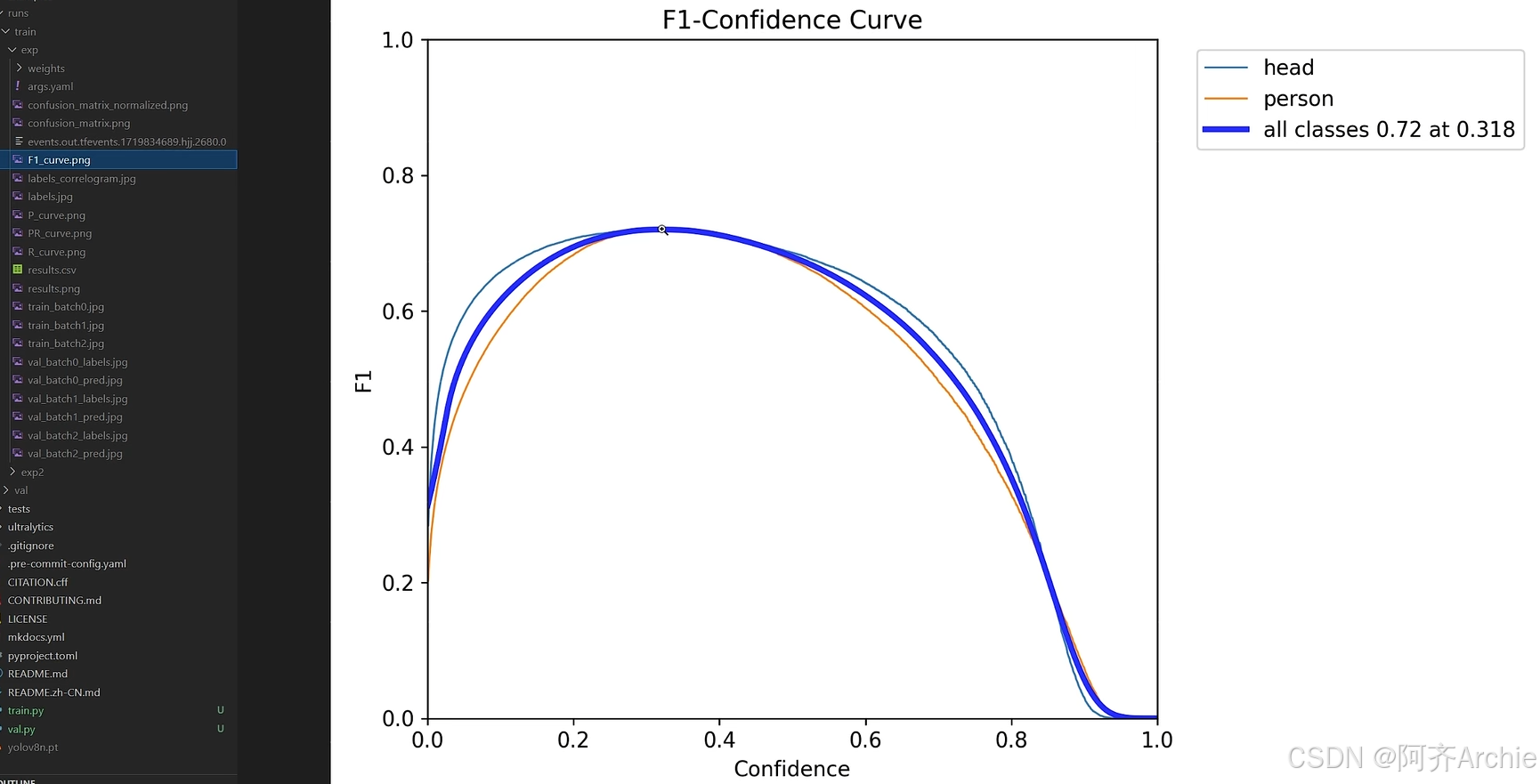
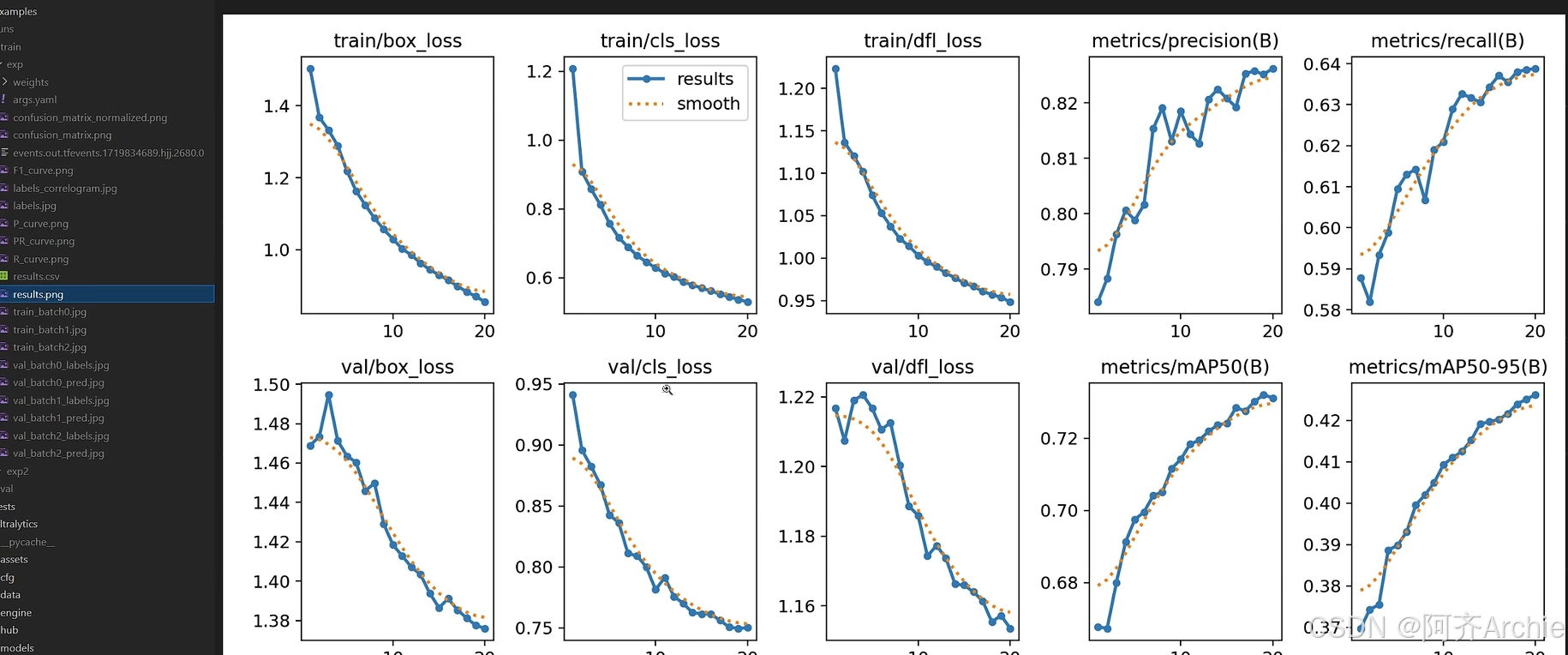
曲线迭代图
计算量和参数量写以下这个,以val.py为主
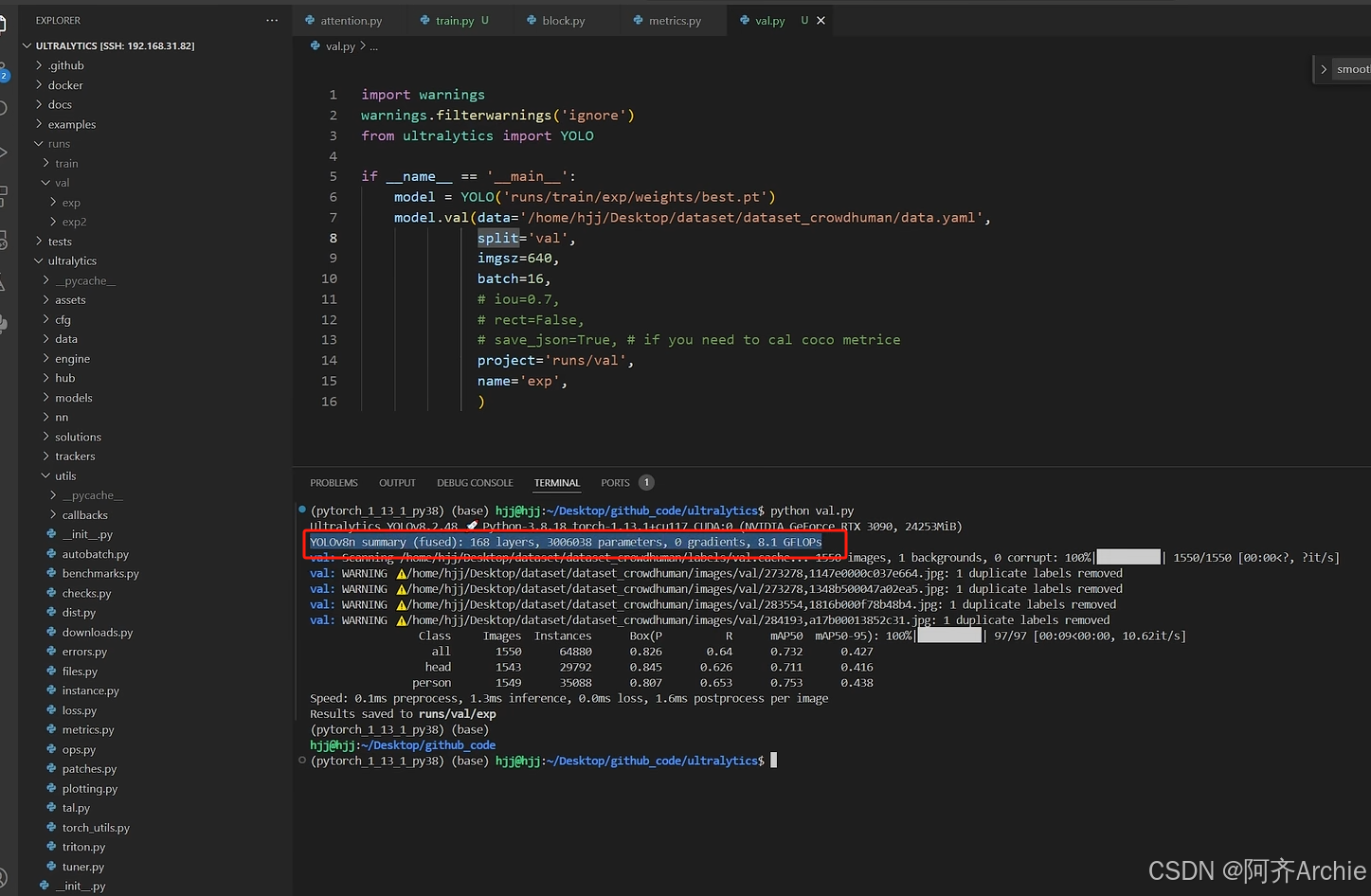
11.上采样和下采样
上采样和下采样,就是对图片进行reset操作(图片分辨率的变化)
上采样:例如图片是40*40像素,经过二倍上采样,尺寸就会乘以2倍,变成80*80。yolov8是用最近邻插值做这个上采样
下采样:例如图片是40*40像素,经过二倍下采样,尺寸就会除以2,变成20*20。yolov8是用步长为2的卷积去做下采样的操作
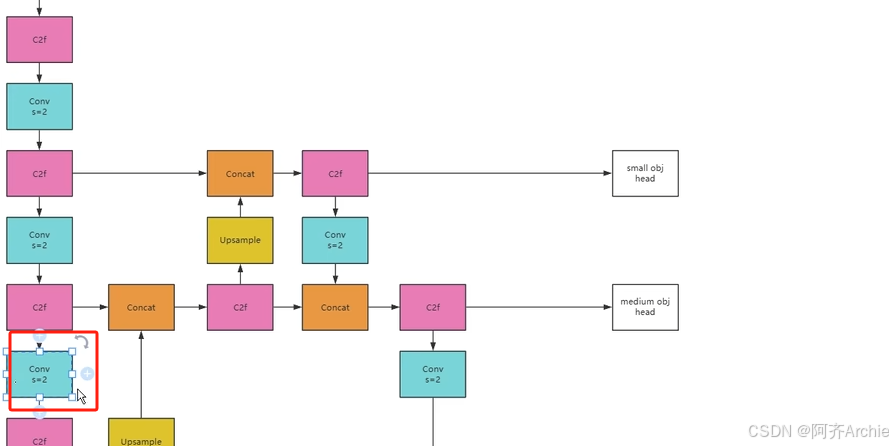
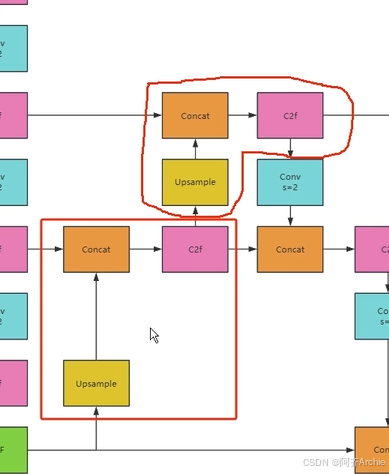
模型结构中的对称性问题:
例如如下yolov8结构中,如下图就是个对称性问题
通道拼接concat要求特征图的尺寸是一样的
其他

自己的图像数据集尺寸不一没关系,yolo会自动进行尺寸统一处理
如果优化器Optimizer参数为auto的时候,会根据迭代次数、数据集量等来自动选择使用SGD还是Adaw。一般项目是SGD
————————学习来自:魔傀面具的个人空间-魔傀面具个人主页-哔哩哔哩视频



















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











