







相关资料
(1)人人都能看懂的GRU - 知乎 (zhihu.com)
引入
在 RNN 那篇博客中提到,根据 RNN 反向传播 BPTT 的特点, RNN 对长时间序列问题难以处理,因为会出现梯度消失和梯度爆炸的问题。详细来说就是当输入序列比较长的时候,RNN 结构也会相应变长,此时根据反向传播中的链式法则,容易使得梯度过大或者过小,也就是 RNN 对越早序列上的数据越容易遗忘。
LSTM 设计的初衷就是使得神经网络对较早输入的数据有更好的记忆力。但是如何能让神经网络对过去的信息也能拥有更好的记忆力成为了难题。如果直接去思考比较难以理解,我们可以类别人类的正常的记忆方式。如果我们早起后重复读一个英语单词 A 五遍,和起床后二十个英语单词各读五遍(其中第一个英语单词也是 A),那么大概率在第一种情况下我们更容易记住 A。这是因为在第二种情况下,有太多别的单词干扰。RNN 的作用也十分类似。如果每个时间点上输入的数据都需要记忆,那么势必越早输入的数据重要性越低。最直接的解决方法可以是使用注意力机制,为不同时间点的输入序列分配不一样的权重,但是对于高维的输入数据,这样无疑会大大加深网络参数量,且不容易训练。但是这种分配注意力(权重)的方法有一点是值得认同的,就是所谓的记忆好与差其实就是比重的高与低。只读一个单词更容易记住,是因为没有别的记忆进行干扰(相对理想的情况下);读二十个单词不容易记住,是因为有大量记忆内容进行干扰,单词 A 所占记忆的比重很低。LSTM 的初衷也是如此,通过一些手段使得重要的信息得以保留,而不重要的信息被抛弃,使得重要的信息所占“记忆”的“比重”变高。
基本原理
LSTM 采用了一种比较巧妙的处理方式,将不同时间点之间连接起来的部分分为“长期记忆线” C C C 和“短期记忆线” h h h。“长期记忆线”类似于 RNN 中的连接方式,用于汇集输入序列上的所有信息;而“短期记忆线”,顾名思义,主要是汇集短期时间内的输入信息,并根据其重要程度,将重要的传给“长期记忆线”,而将不重要的抛弃,这样“长期记忆线”就能够更好地维持其所拥有的信息更加有效。
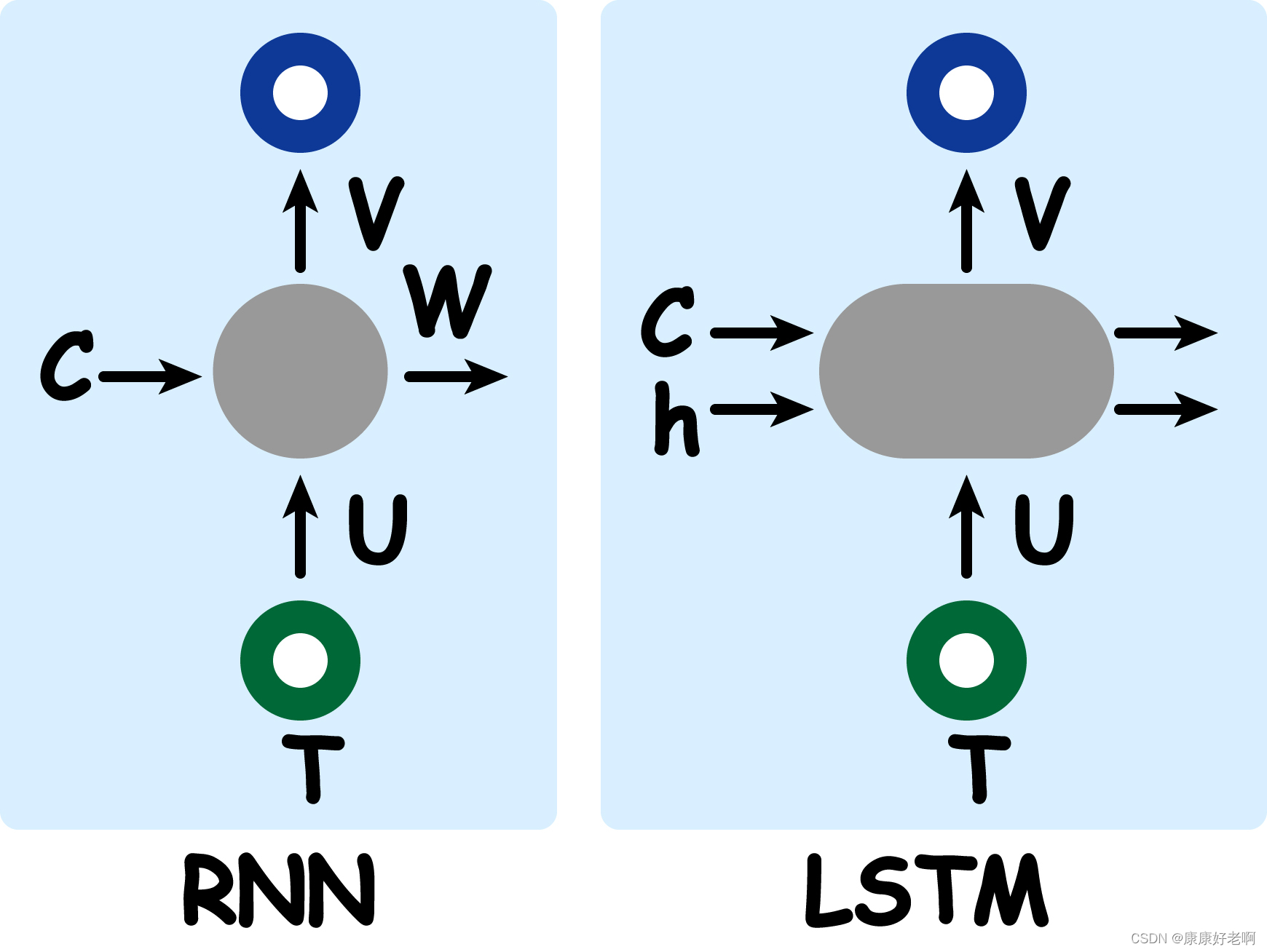
相信大伙在网上也看过 LSTM 内部各种门的各种各样的画法,这里我自己画了一种觉得方便理解。
LSTM 将“短期记忆线” h t − 1 h_{t-1}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









