







 MOTSLAM是一个结合多目标跟踪和单目深度估计的动态SLAM系统,能同时追踪和估计3D动态物体。通过高层对象关联提升特征匹配的鲁棒性,并用束调整优化相机和物体位姿。该系统在单目设置中处理动态场景,提供对物体姿态和形状的精确估计。
MOTSLAM是一个结合多目标跟踪和单目深度估计的动态SLAM系统,能同时追踪和估计3D动态物体。通过高层对象关联提升特征匹配的鲁棒性,并用束调整优化相机和物体位姿。该系统在单目设置中处理动态场景,提供对物体姿态和形状的精确估计。
论文信息
题目:
MOTSLAM:MOT-assisted monocular dynamic SLAM using single-view depth
MOTSLAM:基于单视图深度估计的运动辅助单目动态SLAMestimation
论文地址:
https://arxiv.org/pdf/2210.02038.pdf
发表期刊:
2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
标签
目标跟踪算法、联合优化动态静态背景
摘要
本文提出MOTSLAM,一种具有单目配置的动态视觉SLAM系统,可以跟踪动态物体的姿态和边界框。MOTSLAM首先执行多目标跟踪(MOT),并关联2D和3D边界框检测,以创建初始3D目标。然后,采用基于神经网络的单目深度估计方法获取动态深度特征;最后,使用一种新的光束平差方法联合优化相机位姿、物体位姿以及静态和动态地图点的位姿。
内容简介
MOTSLAM通过单目深度估计解决了单目配置下动态3D结构的模糊性问题。同时,通过将MOT与3D目标检测相结合,MOTSLAM获得了比现有非单目方法更准确的六自由度姿态和周围物体形状。我们的主要贡献如下
第一个视觉SLAM系统,仅以单目帧作为输入,在没有任何运动和物体先验的情况下,可以同时跟踪周围的六自由度动态物体。
在进行低层特征关联之前,首先借助MOT进行对象的高层关联,使得低层关联具有更好的性能和鲁棒性。
通过从MOT中进行关联的3D目标检测来精确初始化对象的姿态和形状,并通过后端对象束调整进行细化。
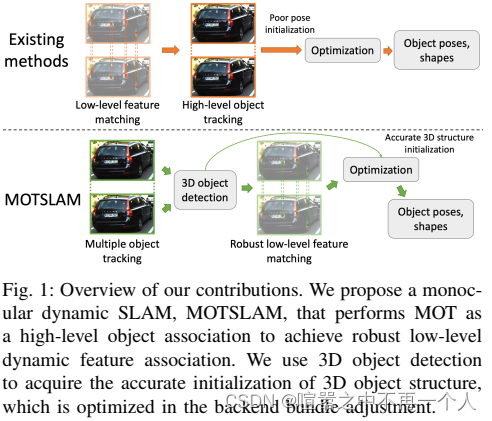
为了获得准确和鲁棒的动态物体3D结构,将多目标跟踪(MOT)纳入框架。特别是,通过基于2D的MOT技术将检测到的2D和3D边界框关联起来。MOTSLAM有效地结合了几种深度学习技术,包括2D/3D目标检测、语义分割和单视图深度估计。首先使用深度单目深度获取可能的动态特征;然后,采用基于二维检测的MOT算法,该算法首先进行高层特征点的关联,使得低层特征点的关联更加简单和鲁棒,即使在非连续帧中也能实现;
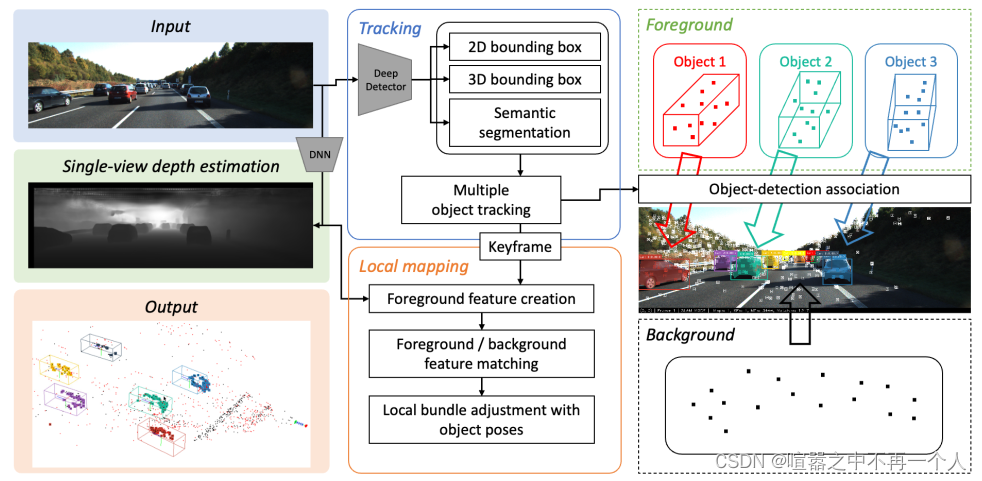
MOTSLAM建立在ORB-SLAM3[25]之上。它以单目序列帧作为输入。对于每一帧,ORB[26]提取与2D/3D目标检测、语义分割和单视图深度估计一起执行。然后应用MOT来创建新对象或将现有对象关联到当前检测。如果一个特征在实例内部有其2D观察结果,则将其分配给该实例并识别为具有语义分割的前景特征。当二维观测值不属于任何实例时,该特征被识别为背景特征。利用估计的深度图计算前景特征的3D位置,并利用物体的姿态在相邻关键帧之间进行关联。最后,对象局部光束平差联合优化相机的位姿、当前物体的位姿以及关联地图点的位姿。
评价
本文提出一种单目动态视觉SLAM,在进行相机跟踪和地图构建的同时,同时跟踪物体的姿态和形状。不同于现有的动态视觉SLAM系统先进行高层目标关联再进行低层特征关联,本文提出首先进行高层目标关联以提供鲁棒且精确的初始化。然后,通过鲁棒初始化来执行低级关联,并通过捆绑调整来优化两者。虽然目前的MOT算法[27]简单有效,但它只利用了二维信息,我们可以利用三维信息对其进行扩展,包括三维边界框和特征,以提高其性能。此外,深度图的质量是整个系统的一个重要限制。为了解决这个问题,可以建立不确定性映射[24]来过滤深度图中的内点,以获得更好的性能。
阅读总结
本文将多目标跟踪算法(MOT)和SLAM(ORB-SLAM3)结合,来解决动态场景中的SLAM问题,个人觉得这个方法比较冗余可能实时性达不到要求。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









