






论文:
[2410.06885] F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
代码:
1. 动机(Motivation)
1.1 简化现有框架
现有非自回归TTS模型(如E2 TTS)依赖复杂的音素对齐和文本编码器,导致收敛速度慢、鲁棒性差(如生成困难案例时失败率高)。
解决:
(1)主干网络采用DiT(替换U-Net),通过adaLN-zero条件注入机制融合文本和语音特征。去除长跳跃连接(Long Skip),简化计算流程,降低推理延迟。
1.2. 提升对齐能力
E2 TTS的文本与语音对齐存在语义和声学特征的高度耦合问题,导致生成结果不够自然和忠实。
解决:
(1)Conv2NeXT模块作为条件实现对齐
1.3. 优化推理效率
扩散模型推理速度慢(如RTF高),需在保持生成质量的同时提升效率。
解决:
(1)提出了一种叫Sway Sampling的推理采样策略。
2. 模型原理及其贡献点
2.1. 原理框架上属于TTS主流模型中的
(1)基于语言模型 自回归
(2)基于流匹配模型 非自回归
2.2. 贡献点
2.2.1. 填充实现对齐
摒弃了传统的音素对齐模型、时长预测器和复杂文本编码器,直接通过填充文本字符至与语音帧等长(使用填充符)作为输入,简化了流程。(即 仅用了填充实现对齐,参考的E2 TTS模型),下图为E2和 F5框架图。
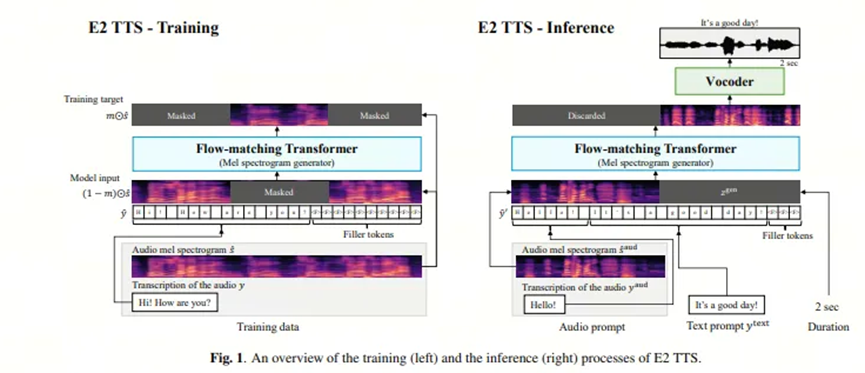
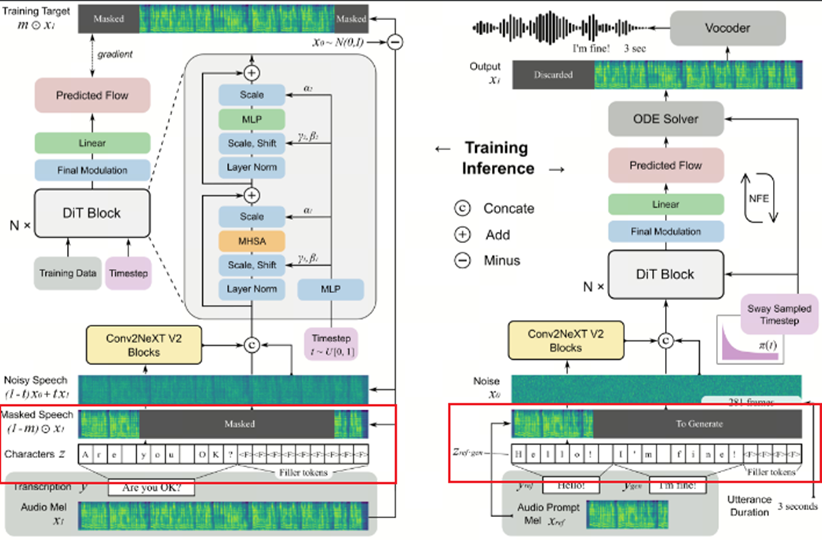
2.2.2. 扩散Transformer架构
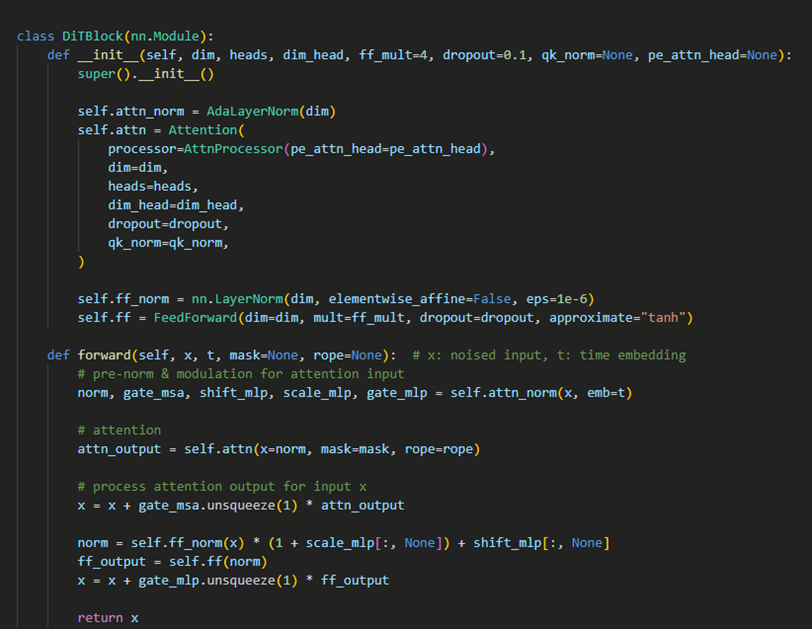
整体模型框架参考E2 TTS模型,在E2 TTS模型基础加入了DIT模块。替代传统U-Net,通过自注意力机制捕捉长程依赖,降低计算复杂度.
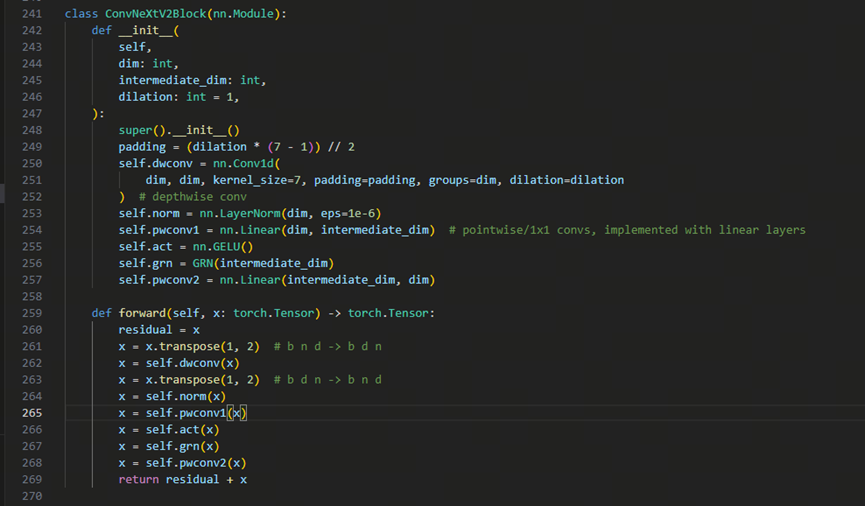
2.2.3. Conv2NeXT模块
在输入前加入Conv2NeXT模块作为条件实现对齐。增强文本与语音模态的隐式对齐能力,解决了E2 TTS中语义与声学特征纠缠的问题 (Conv2NeXT模块原理:在原理的图像上mask一部分,迫使模型能学到更多全局和局部特征)
2.2.4. Sway采样策略
提出了一种流步数推理Sway采样策略 ,显着提高了模型在参考文本的忠实度 和 说话者相似性的性能。提升采样速度
具体为什么能实现 提高了模型在参考文本的忠实度 和 说话者相似性的性能没讲的很清楚。仅笼统的说了一下。


2.2.5 总结方法核心
通过简化输入建模、优化扩散架构与采样策略,实现高效且高质量的非自回归语音合成。
2.1.1.1. 输入建模简化(Input Representation Simplification)
文本填充对齐:
- 直接通过填充符()将文本序列扩展至目标语音帧长度,避免传统音素对齐或复杂文本编码器。
ConvNeXt特征提取:
- 利用ConvNeXt的卷积层次结构,从填充后的文本中提取多尺度局部特征(如音节、词级信息)。
- 增强文本与语音的隐式对齐能力,解决现有方法中语义与声学特征耦合的问题。
2.1.1.2. 扩散Transformer架构(Diffusion Transformer, DiT)
主干网络替换:
- 采用DiT(Diffusion Transformer)替代传统U-Net,通过自注意力机制捕捉长程依赖,降低计算复杂度。
条件注入机制:
- 使用adaLN-zero(自适应层归一化)将文本特征与语音隐变量融合,提升条件生成质量。
架构轻量化:
- 去除U-Net的长跳跃连接(Long Skip),简化推理流程,降低延迟(减少约40% GFLOPs)。
2.1.1.3. Sway Sampling(动态流步骤采样策略)
目标:
- 优化推理时流步骤(flow step)的采样分布,平衡生成质量与效率。
- 数学设计:fsway(u;s)=u+s⋅(cos(2πu)−1+u) 参数s<0:控制分布偏向早期步骤(如u∈[0,0.5]),优先生成语音轮廓,提升稳定性。
优势:
- 在固定采样次数(如16 NFE)下,减少后期冗余计算,WER降低5(2.53→2.42)。
- 通用性:可迁移至其他流匹配模型(如E2 TTS)。
2.2.6 方法亮点
端到端轻量化:
- 从输入建模到架构设计均简化流程,无需音素对齐或复杂文本编码器。
效率与质量平衡:
- DiT加速训练(节省30%时间)与推理(RTF=0.15);
- Sway Sampling动态优化步骤分布,提升文本忠实性(WER降低)。
可扩展性:
- 支持多语言数据与零样本生成,适配复杂场景(如语码切换)。
总结:
一个基于E2 TTS模型的模型,通过ConvNeXt文本建模、DiT架构轻量化与动态采样策略,解决了传统非自回归TTS的收敛慢、对齐差、推理效率低等痛点,实现了高效、鲁棒的语音合成。
3. 实验
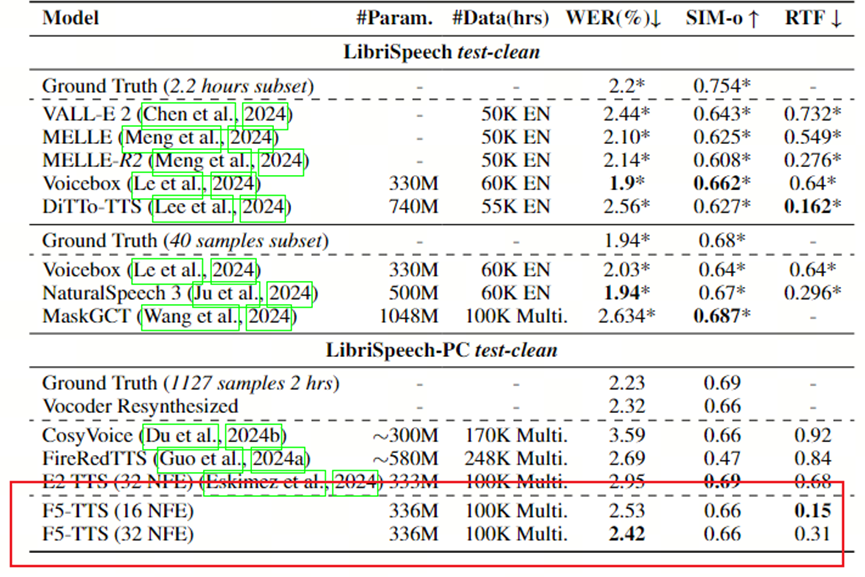
3.1客观评价指标:
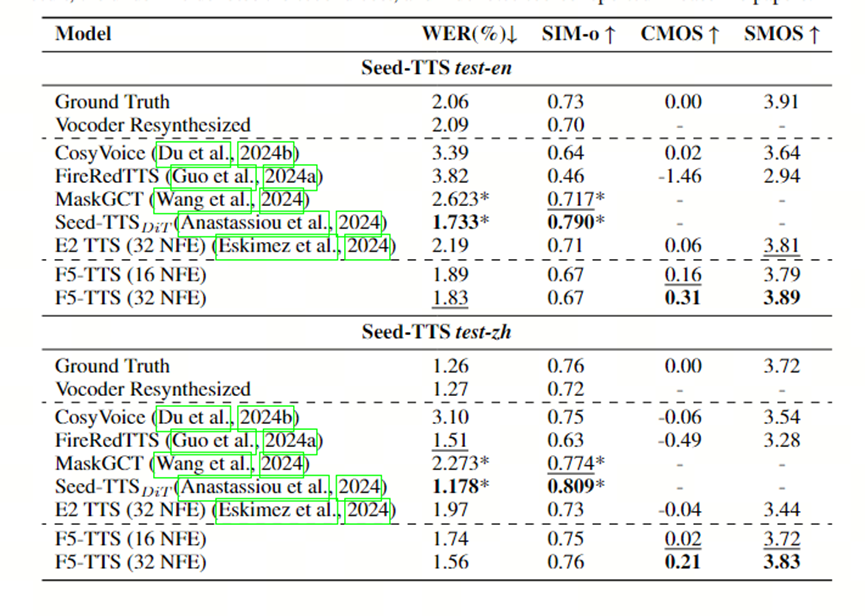
3.2主观评价指标:
3.3消融实验:
ConvNeXt作用:移除后WER上升1.61(4.17→5.78),证明其对文本-语音对齐的关键性。
Sway Sampling:使用后WER降低0.5(2.53→2.42),且可迁移至其他流匹配模型(如E2 TTS)。
DiT架构优势:比U-Net(E2 TTS)节省30%训练时间,。
4. 支持的语种
4.1 初始版本(2024年10月)
支持中文(需使用全拼音输入)和英语(直接输入字母和符号)。目前使用的模型
论文没说但是在词表中看到了日韩的文本拼音,应该支持日文,韩文。
4.2 v1 版本(2025年更新)
扩展支持 法语、意大利语、印地语、日语、俄语、西班牙语、芬兰语 等多语言。
未开源,目前只有demo。
4.3 零样本跨语言生成
无需针对特定语言训练,可通过输入文本的预处理实现跨语言语音合成**(如中文拼音与英语混合输入)**。
5. 多音字,标点符号支持
支持中英文符号,希腊字母等。比如中文逗号‘,’英文逗号‘,’都支持,。
感叹号,句号,逗号,问号等也支持,
5.1 测试结果:
富有情感:感叹号,问号富有情感重音,并且使用感叹号说话节奏会变快,音韵表的欢快。句号停顿会比逗号长。
能区分多音字:使用 拼音代替中文 进行训练,能区分 银行yin 行走 xing 等多音字。
断句停顿:在参考文本没有出现, 。的地方也会出现停顿。
6. 使用文档--语音部分(f5-tts使用方法)
6.1. 命令行运行推理:
f5-tts_infer-cli --model F5TTS_v1_Base \ #模型使用F5TTS_v1_Base
--ref_audio "provide_prompt_wav_path_here.wav" \ #需要克隆的语音参考
--ref_text "The content, subtitle or transcription of reference audio." \ #参考语言的文本(可选)
--gen_text "Some text you want TTS model generate for you." #需要生成语言的文本f5-tts_infer-cli -c custom.toml (custom.toml为你自己写的文档)# F5TTS_v1_Base | E2TTS_Base
model = "F5TTS_v1_Base"
ref_audio = "infer/examples/basic/basic_ref_en.wav"
# If an empty "", transcribes the reference audio automatically.
ref_text = "Some call me nature, others call me mother nature."
gen_text = "I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring."
# File with text to generate. Ignores the text above.
gen_file = ""
remove_silence = false
output_dir = "tests" #输出文件夹
output_file = "infer_cli_basic.wav" #输出文件名字
6.2. Gradio App 运行推理
命令行输入如下,随后本地打开浏览器打开 http://127.0.0.1:7860/
f5-tts_infer-gradio6.4. 注意事项
创建自己的虚拟环境的话,建议使用python=3.10版本;
pytorch别安装到了cpu版本;
第一次运行可能出现缺少一些包,pip install 对应包 即可。

















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









