



论文:
https://arxiv.org/pdf/2412.09262
代码:
https://github.com/bytedance/LatentSync#
1. 背景介绍和动机
1.1 唇型同步Lip Sync与音频驱动人像动画Audio-driven Portrait Animation的区别
很多人可能会把口型同步和音频驱动人像动画混淆,这两个任务有相似之处,但其实是完全不同的任务,主要区别在于输入:
- 口型同步的输入输出:视频+音频->视频
口型同步更像是一个视频到视频的编辑框架,需要保持嘴巴以外的区域与输入视频一致
- 音频驱动人像动画的输入输出:图像+音频->视频
音频驱动人像动画更像是一个图像到视频的动画框架,可以改变头部的运动,甚至面部表情,整体框架的差异导致了
- 唇形同步:Wav2Lip、Diff2Lip、StyleSync、MuseTalk、MyTalk
- 音频驱动的肖像动画:EMO、Hallo、EchoMimic、VASA-1、DreamTalk、SadTalker
1.2 Lip Sync方法
- 基于扩散模型,目前sota
- 基于其他GAI模型,如GAN,VAE.
局限:GAN难收敛,训练不稳定(通用问题);VAE不清晰。
1.3 基于扩散的现有主流框架
1.3.1 单阶段方法
允许模型轻松泛化不同的个体,而无需进一步微调特定身份。然而,这些方法仍然存在一些
局限性:具体来说,在像素空间中执行扩散过程(图1 a),由于硬件要求过高,限制了其生成高分辨率视频的能力。
1.3.2 两阶段方法
第一阶段从音频中生成嘴唇运动,第二阶段根据运动合成视觉外观(图1 b)。
局限性:这个两阶段方法是细微的不同声音可能会映射到相同的运动表示,从而导致与语音的情感语气相关的细微表达丢失。
1.3.3 提出了 LatentSync
这是一种基于音频条件潜在扩散模型的新型端到端口型同步框架,无需任何中间 3D 表示或 2D 标志。LatentSync 利用稳定扩散SD强大的生成能力直接捕捉复杂的视听相关性,从而生成动态逼真的说话视频(图1 c)。
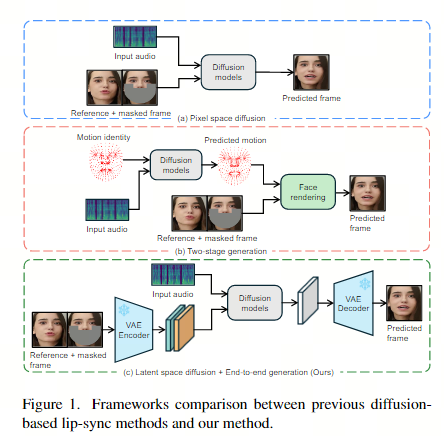
2. 方法
2.1. latent sync框架:
基于图像到图像扩散,因此需要蒙版图像作为输入。
沿通道维度连接不同的输入,使 U-Net 的总输入为 13 个通道(噪声潜伏期为 4 个通道,掩码为 1 个通道,掩码帧为 4 个通道,参考帧为 4 个通道)。
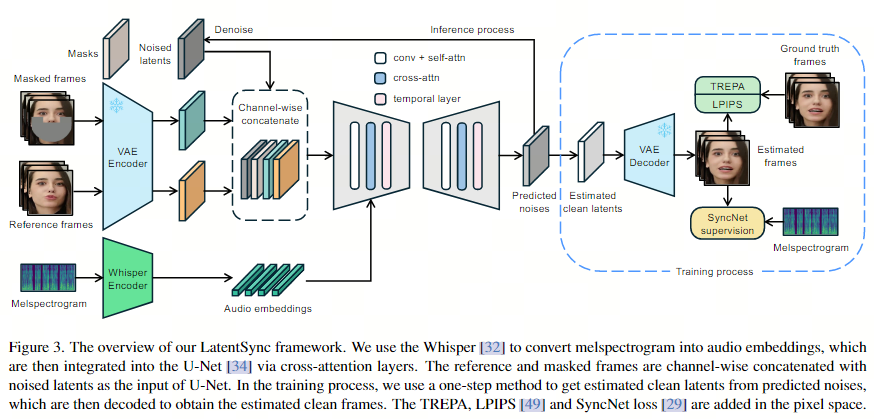
2.2. 音频层
使用预训练的音频特征提取器 Whisper来提取音频嵌入。嘴唇运动可能会受到周围帧的音频的影响,更大范围的音频输入也为模型提供了更多的时间信息。因此,对于每个生成的帧,将来自多个周围帧的音频捆绑在一起作为输入。为了将音频嵌入集成到 U-Net中,使用了原生的交叉注意层。
2.3. SyncNet 监督
(类似于CLIP架构的网络,可以计算音频视频同步与否,输入音频和视频,输出二分类)
2.3.1. 唇形同步中的捷径学习问题
唇形同步方法通常基于视频到视频的修复框架,该模型接收掩码帧和音频作为输入。出乎意料的是,音频条件ldm倾向于根据嘴唇周围的视觉信息来预测嘴唇运动,如面部肌肉、眼睛和脸颊,而忽略了音频信息. 因此文章进行了一个实验来验证捷径学习问题的存在和SyncNet监督在缓解这个问题方面的有效性
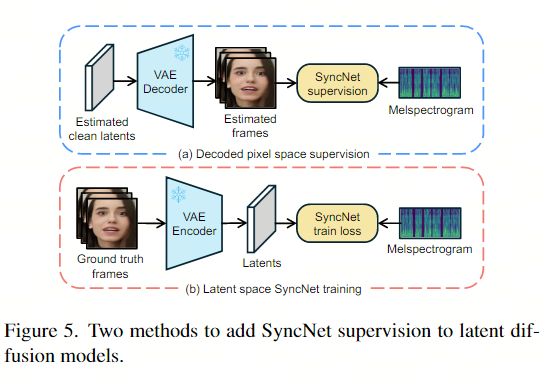
2.3.2. 解码像素空间SyncNet 监督
模型在噪声空间中进行预测,而 SyncNet 需要图像空间中的输入。为了解决这个问题,使用预测的噪声一步估计。另一个问题是模型在潜在空间中进行预测。文章探索了两种将 SyncNet 监督添加到潜在扩散模型中的方法:(a) 解码像素空间监督,以与wav2lip相同的方式训练 SyncNet。(b) 潜在空间监督,需要在潜在空间中训练 SyncNet。此 SyncNet 的视觉编码器输入是通过 VAE编码获得的潜在向量。发现与在像素空间中训练相比,在潜在空间中训练 SyncNet 的收敛性更差。推测这是由于 VAE 编码过程中唇部区域的信息丢失造成的。潜在空间 SyncNet 的收敛性较差也导致监督扩散模型的音频唇部同步准确度较差。因此,在 LatentSync 框架中使用解码像素空间监督。
2.4. 两阶段训练
在第一阶段,我们不解码到像素空间,也不添加 SyncNet 损失。第一阶段的目的是让 U-Net 使用大批量大小来学习视觉特征。因此,第一阶段的训练目标只有一个简单的损失:
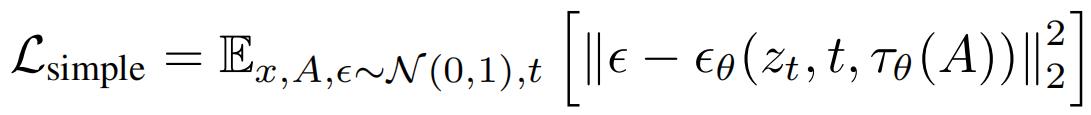
第二阶段,我们使用解码像素空间的监督方法添加 SyncNet 损失。我们将 SyncNet 的输入帧长度增加到16。通过使用 16 个解码的视频帧和相应的音频序列,SyncNet 损失可以公式化为:
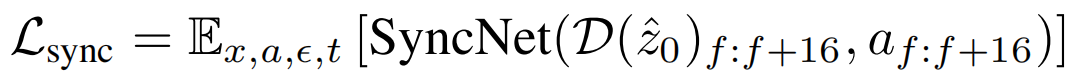
由于口型同步任务需要生成嘴唇、牙齿和面部毛发等细节区域,我们使用 LPIPS 来改善 U-Net 生成的图像的视觉质量。
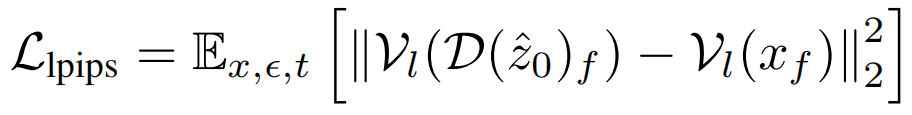
此外,为了提高时间一致性,我们还采用了提出的时域表示对齐TREPA。
TREPA(Temporal Representation Alignment) 将生成的图像序列的时间表示与真实图像序列的时间表示对齐。该方法背后的见解是,仅仅使用单个图像之间的距离损失只能提高单个生成图像的内容质量,但不能增强生成的图像序列的时间一致性。相反,时间表示可以捕获图像序列内的时间相关性,使模型能够专注于提高整体时间一致性。我们采用了大规模自监督视频模型 VideoMAE-v2 (输入mask的视频,输出完整视频,通过计算重建帧与原始帧之间的相似度(如均方误差)来衡量模型的性能)来提取时间表示。由于其在大规模未标记数据集上进行无监督训练,该模型的时间表示表现出强大的泛化能力、鲁棒性和高信息密度。TREPA 直接采用均方误差 (MSE)来测量时间表示之间的距离。
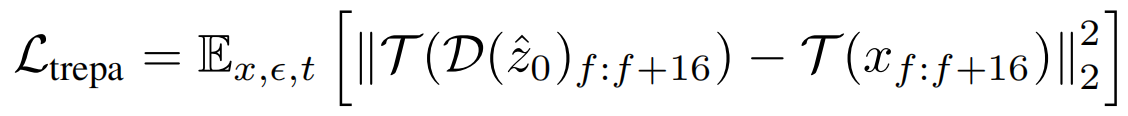
时间层向 U-Net 添加了时间自注意层,以增强时间一致性。我们最初尝试将时间层应用于 LatentSync,但发现它严重损害了口型同步准确性。相比之下,我们的 TREPA 不仅避免损害口型同步准确性,甚至在一定程度上提高了口型同步准确性。我们假设这是因为时间层向 U-Net 添加了额外的参数,导致反向传播中的一些梯度分布到时间层参数上,削弱了音频交叉注意层参数的学习。另一方面,TREPA 不添加额外的参数;为了提高时间一致性,模型必须更有效地依赖音频窗口中的信息(因为我们知道口型同步模型使用音频窗口来捕获时间信息)。因此,音频交叉注意层得到了进一步的训练和加强。另一个有趣的发现是,TREPA 还可以用于提高 Wav2Lip的时间一致性和口型同步准确性。理论上,任何一次生成多个连续帧的视频生成模型都可以利用 TREPA 来增强时间一致性。
第二阶段训练的总loss函数是:
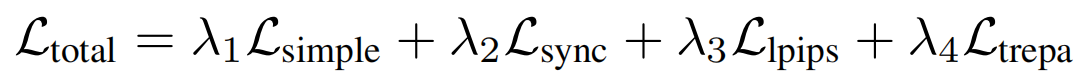
2.5. 混合噪声模型
为了确保模型正确地学习时间信息,输入噪声也需要具有时间一致性;否则模型将无法正确学习。最简单的方法是将相同的噪声应用于所有帧。我们进一步发现,用混合噪声模型训练的扩散模型表现出更好的时间一致性。我们在两个训练阶段都使用了混合噪声模型,并在推理阶段将相同的初始潜在噪声应用于视频中的所有帧。
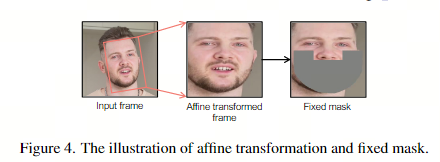
2.6. 仿射变换(数据预处理)
在数据预处理阶段,采用仿射变换实现面部正面化。这种方法有助于模型有效地学习面部特征,特别是在侧面视图等具有挑战性的场景中。
3. 实验
3.1. 训练集:
只用了开源的VoxCeleb2和HDTF,先用HyperIQA排除低质量(不知道内部有没有大型自有数据集,效果应该能提不少)
3.2. 实现:
完整的数据处理步骤包括以下步骤:
- 删除损坏的视频文件。
- 将视频 FPS 重新采样为 25,并将音频重新采样为 16000 Hz。
- 通过 PySceneDetect 进行场景检测。
- 将每个视频分成 5-10 秒的片段。
- 根据人脸对齐检测到的特征点对人脸进行仿射变换,然后调整大小为 256×256.
- 模型推理,采样用的DDIM
- 移除同步置信度低于 3 的视频,并将音视频偏移调整为 0。
- 计算 hyperIQA 分数,并删除分数低于 40 的视频。
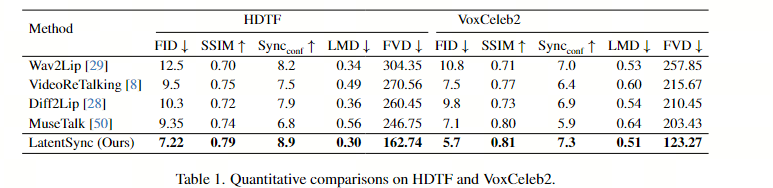
3.3. 训练和结果评估:
使用 8 x H100 80GB,第一阶段训练大约需要 14 天,第二阶段大约需要 1-2 天。

4. 使用文档
4.1. 推理
激活虚拟环境:conda activate latentsync
进入工作目录:cd /mnt/nvme/proj_dev/agent_workspace/liujian/LatentSync
使用推理:bash ./inference.sh
注意!使用推理之前配置inference.sh文件
例子:
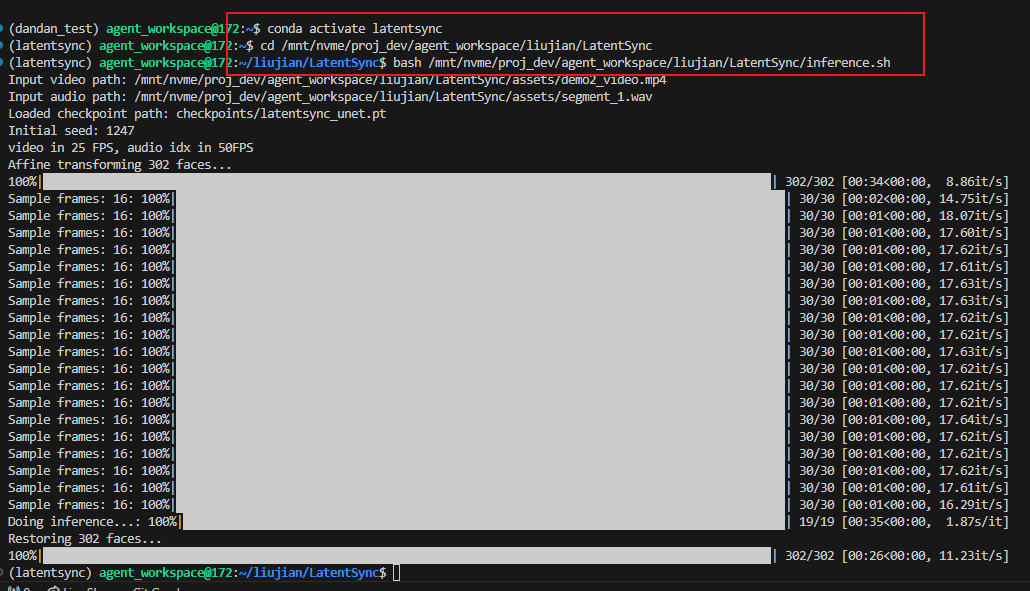
其中包括模型路径、推理步数(越高越好 范围[20-50])、指导尺度(越高越好 范围[1-3])、输入视频路径、输入音频路径、输出路径,如下
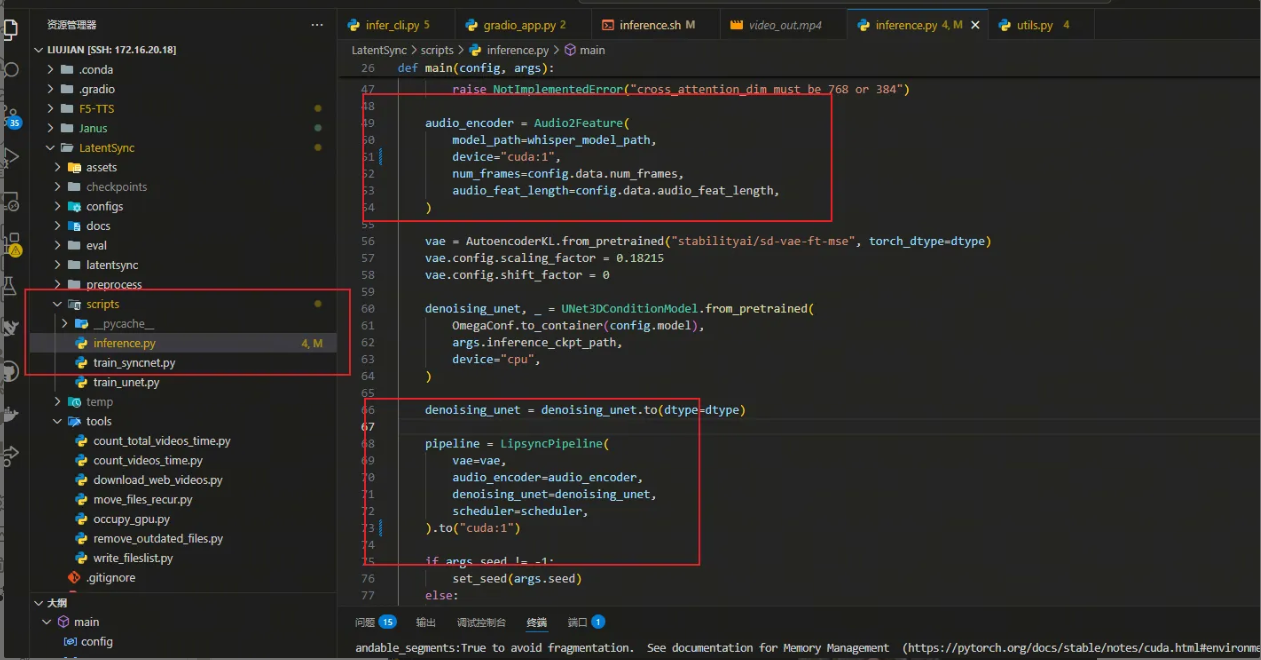
如果显卡被占用可以修改inferenc.py文件,这里我用的是cuda:1,如下
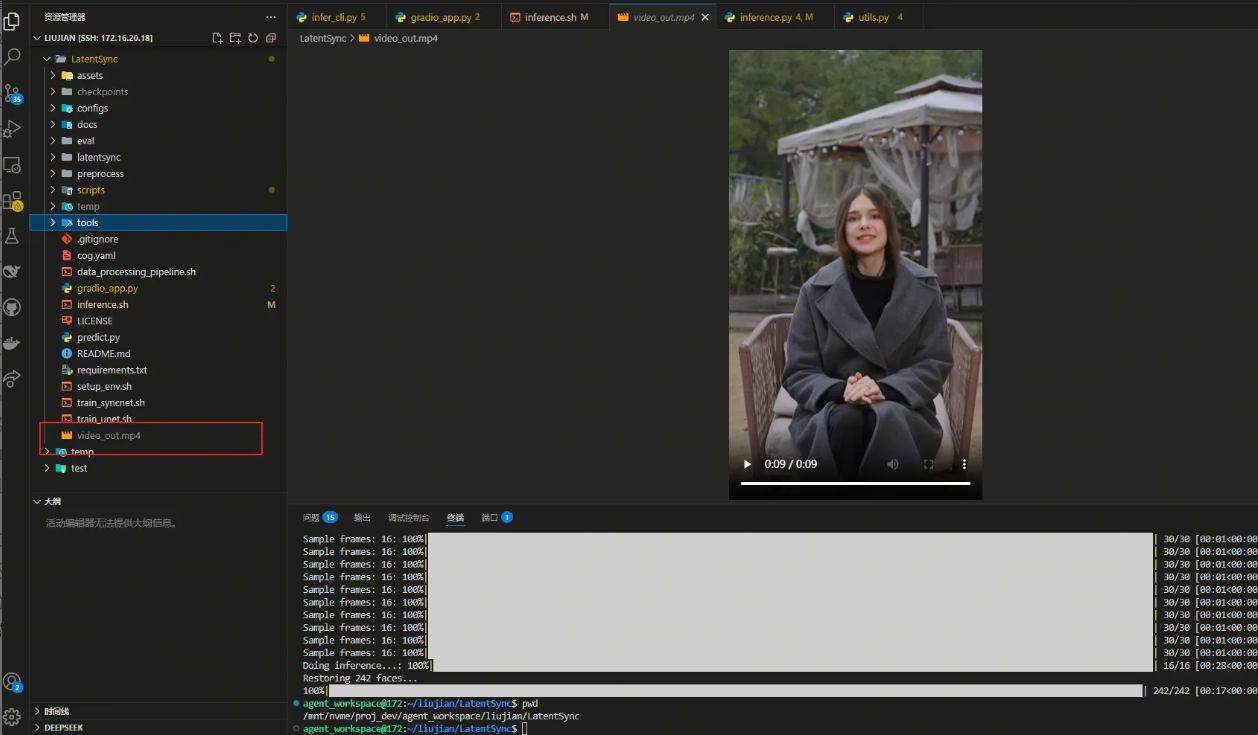
运行完成后在目录输出视频,如下
4.2. 模型再训练
先下载所有 checkpoint,下载文章在 VoxCeleb2 和 HDTF 数据集上发布了一个准确率为 94% 的预训练 SyncNet,用于监督 U-Net 训练。也可以本地重新训练一个SyncNet。
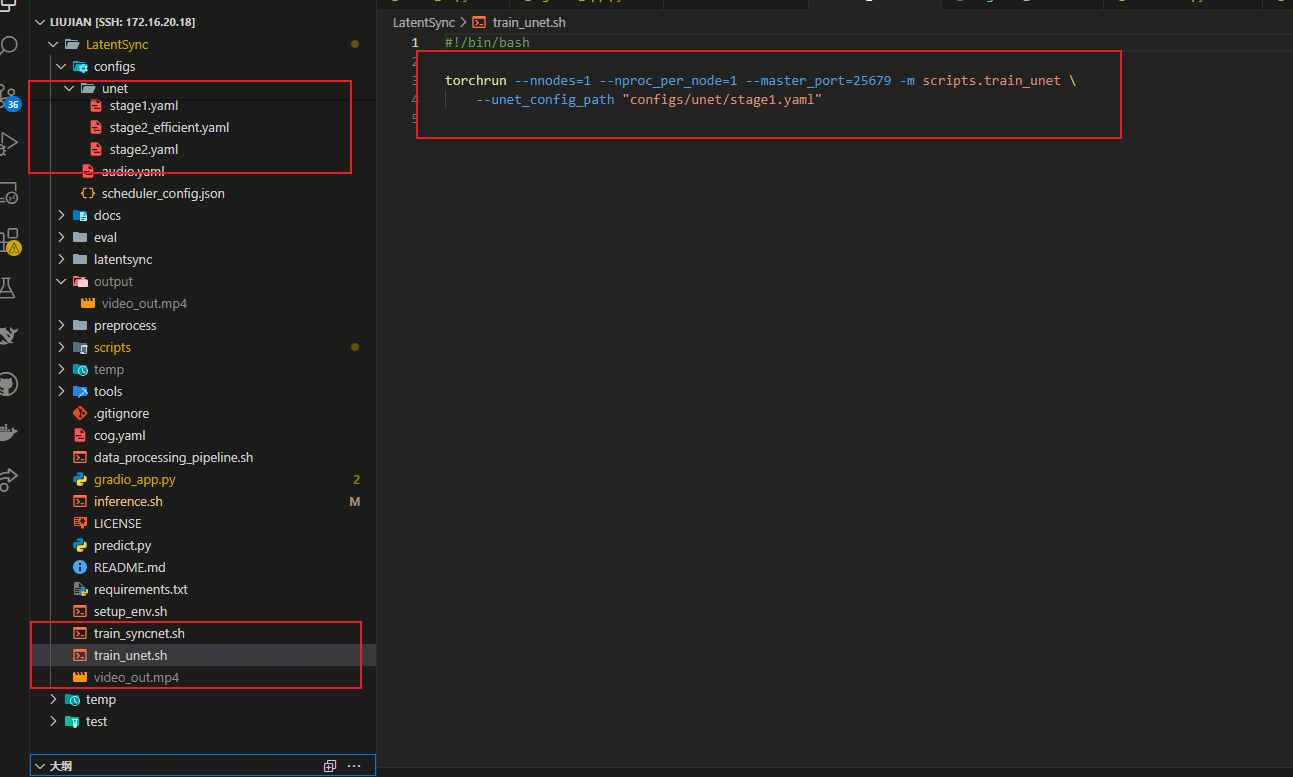
使用脚本 ./train_unet.sh
在上述脚本中修改配置文件可以选择对应的阶段训练和参数。
更改 U-Net 配置文件中的参数,以指定数据目录、检查点保存路径和其他训练超参数。为方便起见,准备了一个用于编写数据文件列表的脚本。运行以下命令:
python -m tools.write_fileslist
4.3. 训练 SyncNet
如果要在自己的数据集上训练 SyncNet,可以运行以下脚本。SyncNet 的数据处理管道与 U-Net 相同。
脚本 ./train_syncnet.sh
4.4. 评估
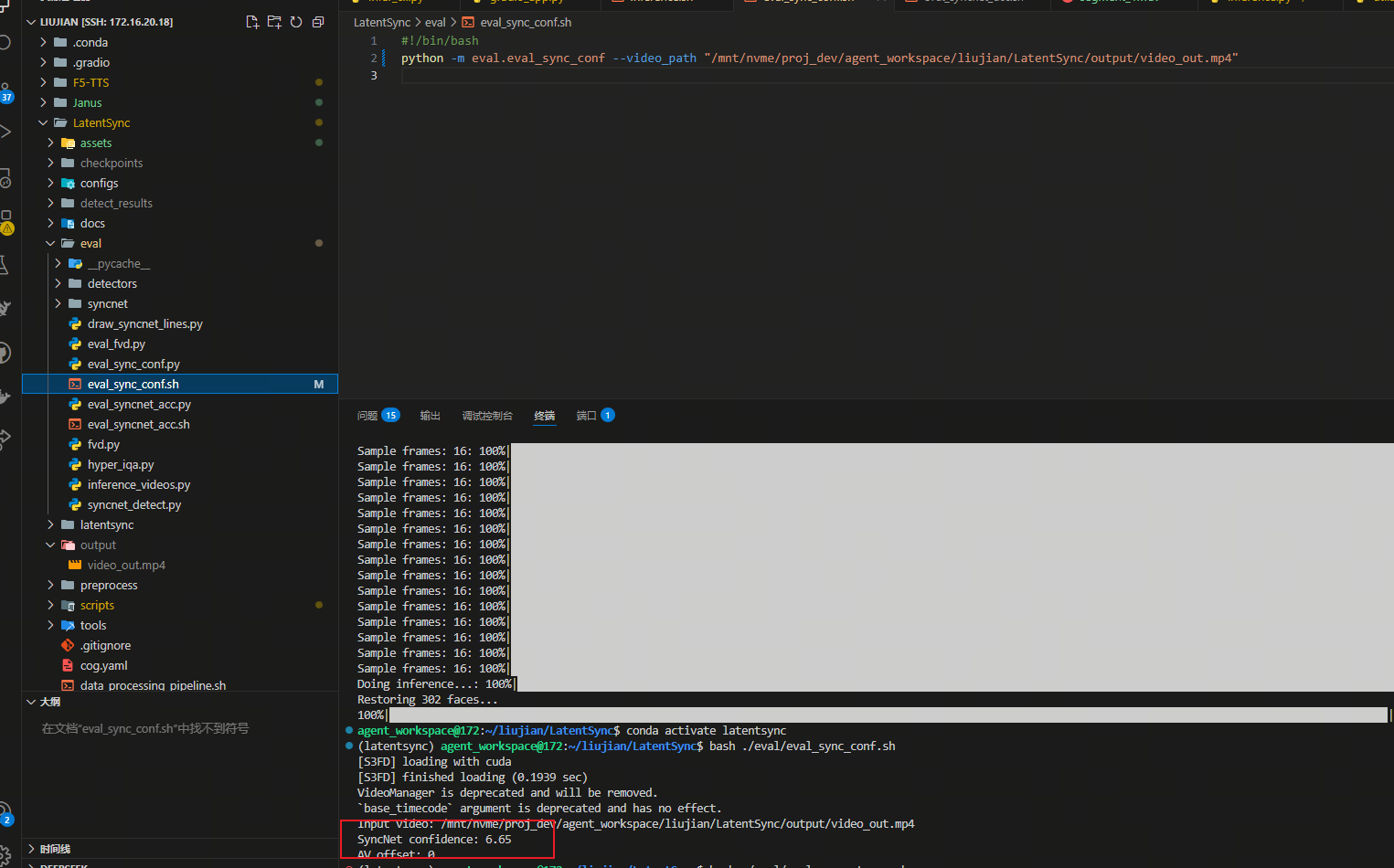
可以通过运行以下脚本来评估生成的视频的同步置信度分数:
./eval/eval_sync_conf.sh
您可以通过运行以下脚本来评估 SyncNet 在数据集上的准确性:
./eval/eval_syncnet_acc.sh

















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









