







目录
逻辑回归就是解决二分类问题的利器,比如:是否为垃圾邮件。
逻辑回归是一种用于二分类问题的统计学习方法,它的目标是通过对输入特征的线性组合应用一个逻辑函数(也称为sigmoid函数)来预测输入属于两个类别之一的概率。
sigmoid函数:
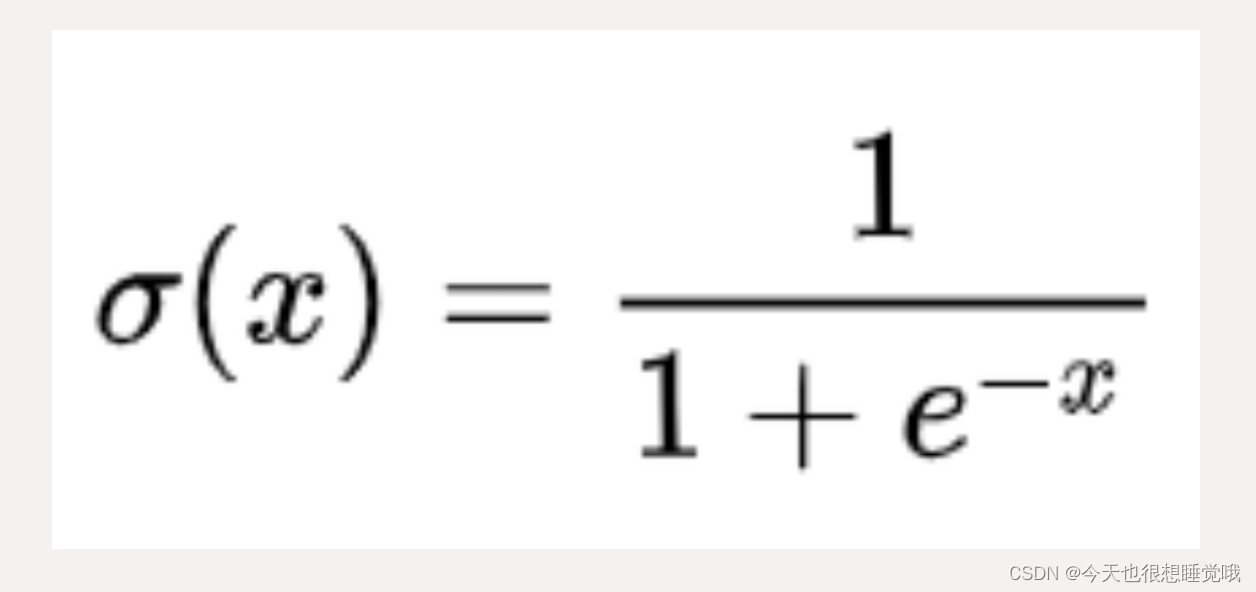
即将一组不同的特征值输入,利用sigmoid函数计算,得到一个值,这个值代表为正的概率(以0.5为阈值)大于0.5为A,小于0.5为B(类别)。

逻辑回归的损失函数
逻辑回归的损失函数:对数似然损失


例题:

如何计算损失函数值?
设大于0.5的类别为A,小于为B,sigmoid函数值为S。如果是A类别,则损失值为-log(S);如果是B类别,损失值为-log(1-S);累加所有的值。
逻辑回归的API
from sklearn.model_selection import GridSearchCV
from sklearn.linear_module import LogisticRegression
# 定义正则化参数的候选值
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100]}
# 创建逻辑回归模型
logreg = LogisticRegression(solver=‘liblinear’,penalty=‘l2’)
#solver:二分类用liblinear 多分类用libfgs penalty为正则化的种类
# 使用GridSearchCV进行交叉验证和网格搜索
grid_search = GridSearchCV(logreg, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("Best C: ", grid_search.best_params_)
# 得到最佳模型
best_logreg = grid_search.best_estimator_
# 在测试集上进行预测
y_pred = best_logreg.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print("Accuracy: ", accuracy)
print("Confusion Matrix: \n", conf_matrix)上述代码中运用了网格搜索,其中超参数C的取值:
C是正则化强度的倒数:C的取值越小,惩罚的力度越大,正则化的效力越强,鲁棒性越好,参数 θ 会逐渐被压缩得越来越小。
penalty的取值代表用L1正则化还是L2正则化















 7836
7836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









