






简单做几个decode的方法:
input_sequence = "I like Lakers"
![]()
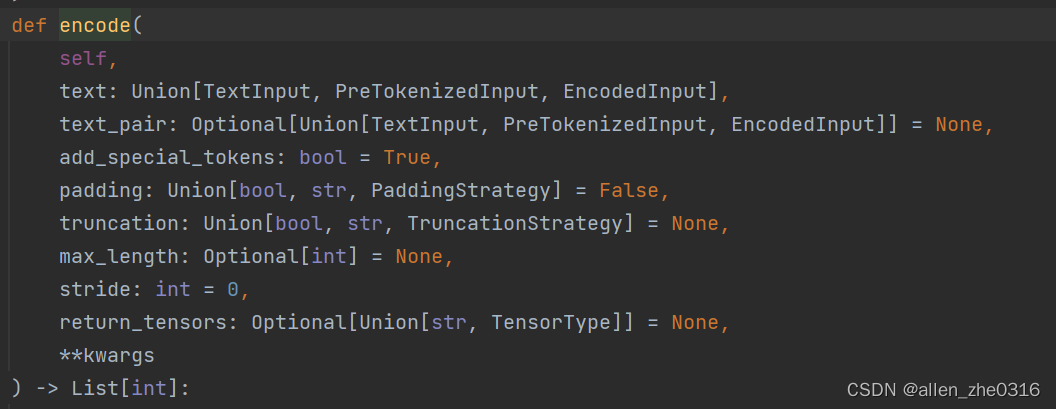
先进行encode,通过查看encode内置函数发现是encode_plus。
我们默认的几个关键参数:
1.text pair 用于确定是否有第二条句子一起作为输入 默认为None
2.add-special_tokens 默认为True
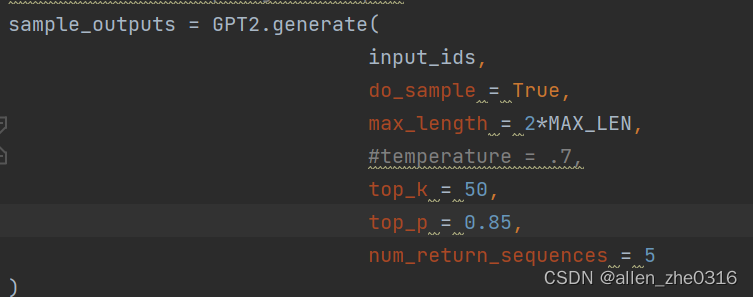
GPT2.generate 默认的decode方式是greedy search:

第一次解码提示性文本就是输入的文本ids
每次解码结束,取出最高可能性的next token 加入到输入的文本ids中,做下一次的解码
greedy search的主要缺点是,它只考虑了当前的高概率词,忽略了在当前低概率词后面的高概率词。
2.Beam Search:

num_beams 指的是每个时刻五条概率最大的路径,并保存。最终输出n个return_sequences。
但是num_return-sequences不能大于num_beams,应该是为了防止极端情况的发生。
no_repeat_ngram_size n设为2 来保证生成的句子中不存在重复的连续两个ids
把这个句子拿出来 感觉还是挺有可读性的
I don't know about you, but there's only one thing I want to do after a long day of work, and that's to sit down and watch a movie."
"I know, I know," you say. "But you're not going to like this one. It's about a guy who has a crush on a girl
3.温度采样
现在我们希望生成的词有创造性一些,它不一定是概率最大的词。我们希望生成的词是概率不那么大的。

如果T为1,那么就是随机从词库中抽取,那么概率大的词还是容易被抽到。但是如果我们对上下同时除以k,那么相当于做了一些归一化,会拉进差距,从而使概率较小的词能够被抽到。但是我们并不希望生成一些非常生僻的词。
可以采用top-k采样:
Top-K 是直接挑选概率最高的 K 个单词,然后重新根据 softmax 计算这 K 个单词的概率,再根据概率分布情况进行采样,生成下一个单词。采样还可以选用 Temperature Sampling 方法。
关于K的选择当然是文本较短的话选择较小的K,反之文本较大就选择较大的K。
I don't know about you, but there's only one thing I want to do after a long day of work. I want to relax, take a shower, get some fresh air, look around…well, you know how it feels to be surrounded by a big, tall pile of junk while trying to get a little work done to help my ...
太优美了
Top-P Sampling (Nucleus sampling) 是预先设置一个概率界限 p 值,然后将所有可能取到的单词,根据概率大小从高到低排列,依次选取单词。当单词的累积概率大于或等于 p 值时停止,然后从已经选取的单词中进行采样,生成下一个单词。采样同样可以选用 Temperature Sampling 方法。
我们也可以结合起来一起使用:















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









