







这里写目录标题
第1章 传统计算机视觉基本原理(图像的建模)
1.1 传统的计算机视觉
在2012年之前,CV的主要研究方法是使用人工设计(hand-designed)的图像特征来完成各种任务(见下图)。

1.2 不足
这些特征都是人为预设的,图像的处理基于这些预设的特征,如颜色特征、外形特征等等。人为特征的最大缺陷是:不同场合的特征不一样,不同场景,需要建立不同的模型,适应性差。
传统的图形学管线(pipeline)中,输出图像需要经过建模、材质贴图、光照、渲染等一系列繁琐的步骤。

第2章 基于深度学习DNN的计算机视觉的基本原理(图像的判定)
2.1 基于深度学习的计算机视觉DNN
2012年,随着使用深度神经网络(Deep Neural Network, DNN) 在ImageNet的分类任务上取得了巨大成功,图像处理的任务由认为构建图像特征发展成,机器自己发现图像的特征。
如下图所示,DeepNet能够自动发现输入图像(RGB通道的像素),并根据发现的特征,完成某种任务。这些DNN包括:全连接网络、卷积网络CNN、时序网络RNN/LSTM.
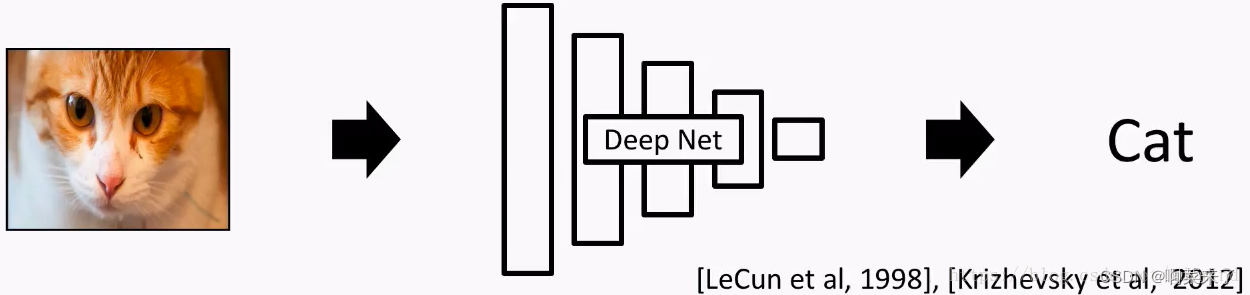
基于网络自动发现的图像特征, 可以完成的任务包括(不限于)
(1)物体识别(Object detection) [Redmon etal., 2018]
(2)对人体肢体的理解(Human understanding) [Guler et al., 2018]
(3)自动驾驶(Autonomous driving) [Zhao et al., 2017]

2.2 DNN的不足
之前的DNN可能是输入一幅图像,输出一个标签(比如说猫),那我们能不能输入“猫”这个字,输出一张猫的照片呢?
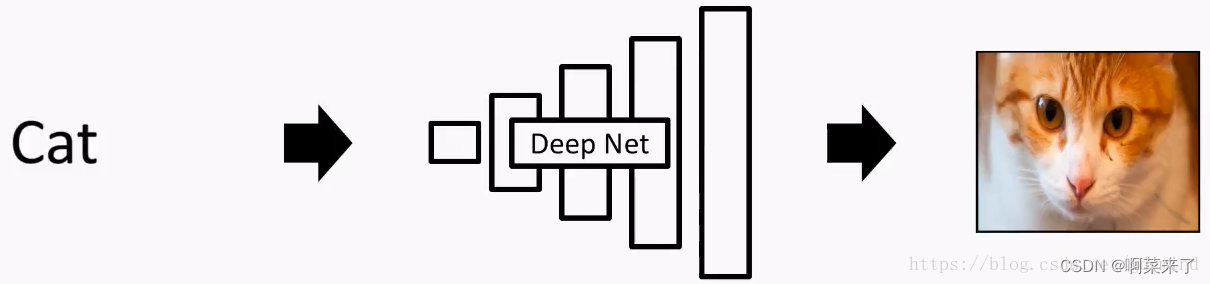
很遗憾,答案是No!
因为这种任务实在太复杂啦!
我们很难让DNN凭空输出图像这样的高维数据(High dimensional data)(这里的“高维”可以理解成数据量大)。
实际上,在很长一段时间里,DNN只能输出数字这种简单的、低分别率的小图像,就像下面这样:
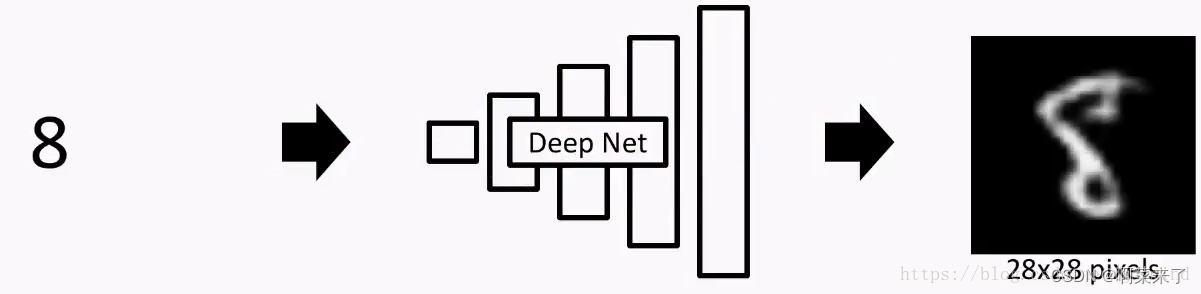
而想要生成想游戏场景这类的图片,DNN这种方法根本没用。
第3章 常规生成对抗网络GAN的基本原理(不受控的图像的生成)
3.1 常规生成对抗网络GAN
2014年,一个叫做生成对抗网络(Generative Adversarial Network)——也就是大名鼎鼎的GAN——的东西横空出世。作者是下面这位小哥和他的小伙伴们:


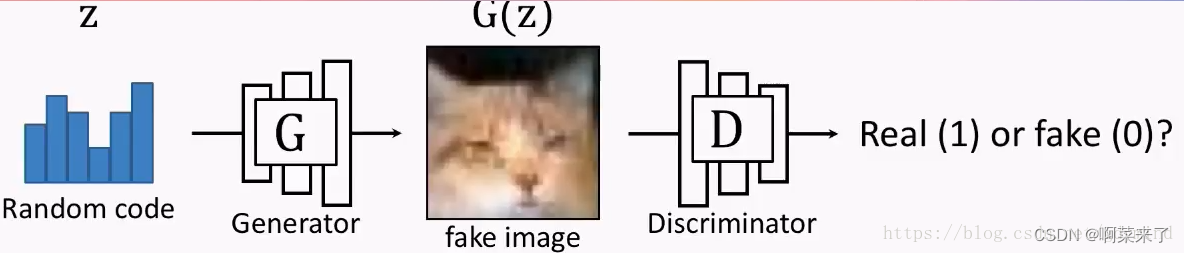

至此,GAN网络可以自己输出多维度的图片数据了。
图像数据具备了真实图片集的公共特征。
生成的高纬度的图像数据会骗过网络的判决器,被判定为真实的图片。
3.2 生成对抗网络的创作本质
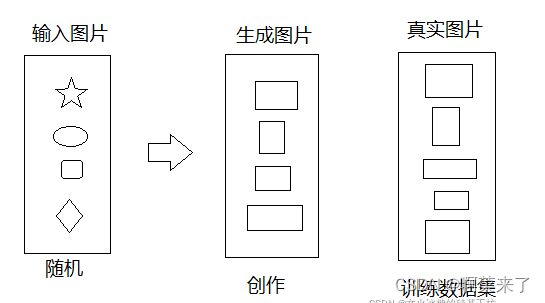
GAN网络输出的创作图片,与输入图片无关
输入:可以是任意的随机数。
输出:与训练集上的真实图片具备相同的特征,但具体是什么样子的,什么尺寸,不受控制。
3.3 生成对抗网络的不足
生成对抗网络虽然能生成高维的图像,该图片与参与网络训练的高纬度的真实图片,具备相同的特征。比如,自动生成人像图像或其它相关的图像。
但图像的生成或输出,与输入之间实际上并没有明显的语义上的对应关系。
(1)输出的图片没有用户控制(user control)能力
在传统的GAN里,输入一个随机噪声,就会输出一幅随机图像。随机图像能够骗过判决网络,具备与真实图片相同的特征。
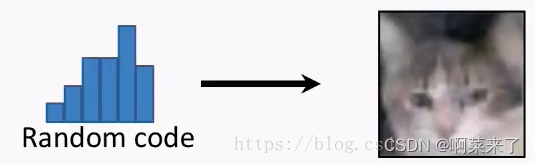
但用户是有想法滴,如果我们想输出的图像是我们想要的那种图像,和我们的输入是对应
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











