







 深度学习的应用场景:图像搜索、自动驾驶、用户行为分析、文字识别、虚拟现实和激光雷达等等基于深度学习的计算机视觉同时可以对其他学科产生影响: 在计算机图形学的动画仿真和实时渲染技术; 材料领域的显微镜分析技术; 医学图像分析处理技术; 实施评估师生课堂表现和考场行为的智慧教育; 分析运动员比赛表现技术等数据集: 2007年,普林斯顿大学李飞飞团队基于 WordNet 的层级结构开始搭建 ImageNet 数据集。最 终 在 2
深度学习的应用场景:图像搜索、自动驾驶、用户行为分析、文字识别、虚拟现实和激光雷达等等基于深度学习的计算机视觉同时可以对其他学科产生影响: 在计算机图形学的动画仿真和实时渲染技术; 材料领域的显微镜分析技术; 医学图像分析处理技术; 实施评估师生课堂表现和考场行为的智慧教育; 分析运动员比赛表现技术等数据集: 2007年,普林斯顿大学李飞飞团队基于 WordNet 的层级结构开始搭建 ImageNet 数据集。最 终 在 2

深度学习的应用场景:图像搜索、自动驾驶、用户行为分析、文字识别、虚拟现实和激光雷达等等
基于深度学习的计算机视觉同时可以对其他学科产生影响:
在计算机图形学的动画仿真和实时渲染技术;
材料领域的显微镜分析技术;
医学图像分析处理技术;
实施评估师生课堂表现和考场行为的智慧教育;
分析运动员比赛表现技术等
数据集:
2007年,普林斯顿大学李飞飞团队基于 WordNet 的层级结构开始搭建 ImageNet 数据集。最 终 在 2009 年 公 开 。 如 今 ImageNet 数 据 集 包 含 超 过 14 000 000 张带标签的高清图像、超过 22 000 个类别。
2010 年开始举办的 ILSVRC 图像分类比赛成为计算机视觉领域的重要赛事,用于评估图像分类算法的准确率。ILSVRC 比赛数据集是 ImageNet 的一个子集,包含 1000 类、数百万张图片。
2018 年谷歌 发 布 了 Open Image 数 据 集[33],包 含 了 被 分 为 6 000 多 类 的 900 万 张 带 有 目 标 位 置 信 息 的 图 片
1.通用深度神经网络模型综述
1998年LeCun提出LeNet,由2个卷积层和3个全连接层组成,又称作LeNet-5,结构如图所示,被广泛的应用于手写数字识别。
缺点:在小数据集上表现良好,在大数据集上表现一般

2012年 AlexNet被提出,首次将深度学习技术应用到大规模图像分类领域,采用5层卷积层和3层全连接层,激活函数使用RELU取代了sigmoid,用dropout方法取代了权重衰减缓解过拟合。在ImageNet上取得了17%的错误率,结构如图所示。

2014提出ZFNet,通过反卷积可视化CNN学习到的特征,在ImageNet上取得了11.7%的错误率;
2015年提出GoogleNet,提出了一种Inception模块,错误率降到了6.7%。如图 3 所示。这种结构基于网络中的网络(Network in network,NiN)的思想[24],有 4条分支,通过不同尺寸的卷积层和最大池化层并行提取信息,1 × 1 卷积层可以显著减少参数量,降低模 型复杂度。GoogLeNet 一共使用 9 个 Inception 模块,和全局平均池化层、卷积层及全连接层串联。

2015年,VGGNet被提出,重复使用3*3的卷积核和和2*2的池化层,将深度网络加深到了16-19层,如图所示。

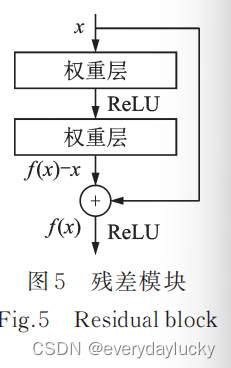
2016年,何凯明团队提出了ResNet,将 top‑5 错误率降至 3.6%。ResNet 最深可达 152 层,以绝对优势获得了目标检测、分类和定位3个赛道的冠军。该研究提出了残差模块的跳接结构,每 1 个残差模块里有 2 个相同输出通道的 3×3 卷积层,每个卷积层后接 1 个 BN(Batch nor‑ malization)层和 ReLU 激活函数。跳接结构可以使数据更快地向前传播,保证网络沿着正确的方向深化,准确率可以不断提高。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2364
2364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









