






Huggingface又上不去了?这里有个新的解决方案!
最近,由于来自东方的某种神秘力量,导致Huggingface登陆不上去了或者访问速度特别慢。这让我们这些依赖Huggingface和一些其他平台托管的数据集进行“炼丹”的炼丹师们深感烦恼。现在的解决方案基本是都是自己想办法“科学上网”,但众所周知,科学上网不仅得“氪金”,速度慢还不稳定。
但是!最近在阿里云上发现了一个好地方——计算巢数据集市场,可以完美解决大家的问题,让这堵“墙”变成“任意门”~~计算巢数据集是一个高效获取数据集的解决方案,旨在加速企业在人工智能、大数据和云计算(AIGC)创新转型过程中的数据处理环节,从计算巢数据集下载想要的数据集,可以走阿里云内网,速度超乎想象!!
下面给大家实测一下从计算巢下载数据集的过程。
订阅并下载数据
- 首先访问计算巢数据集市场,浏览或搜索你感兴趣的数据集。
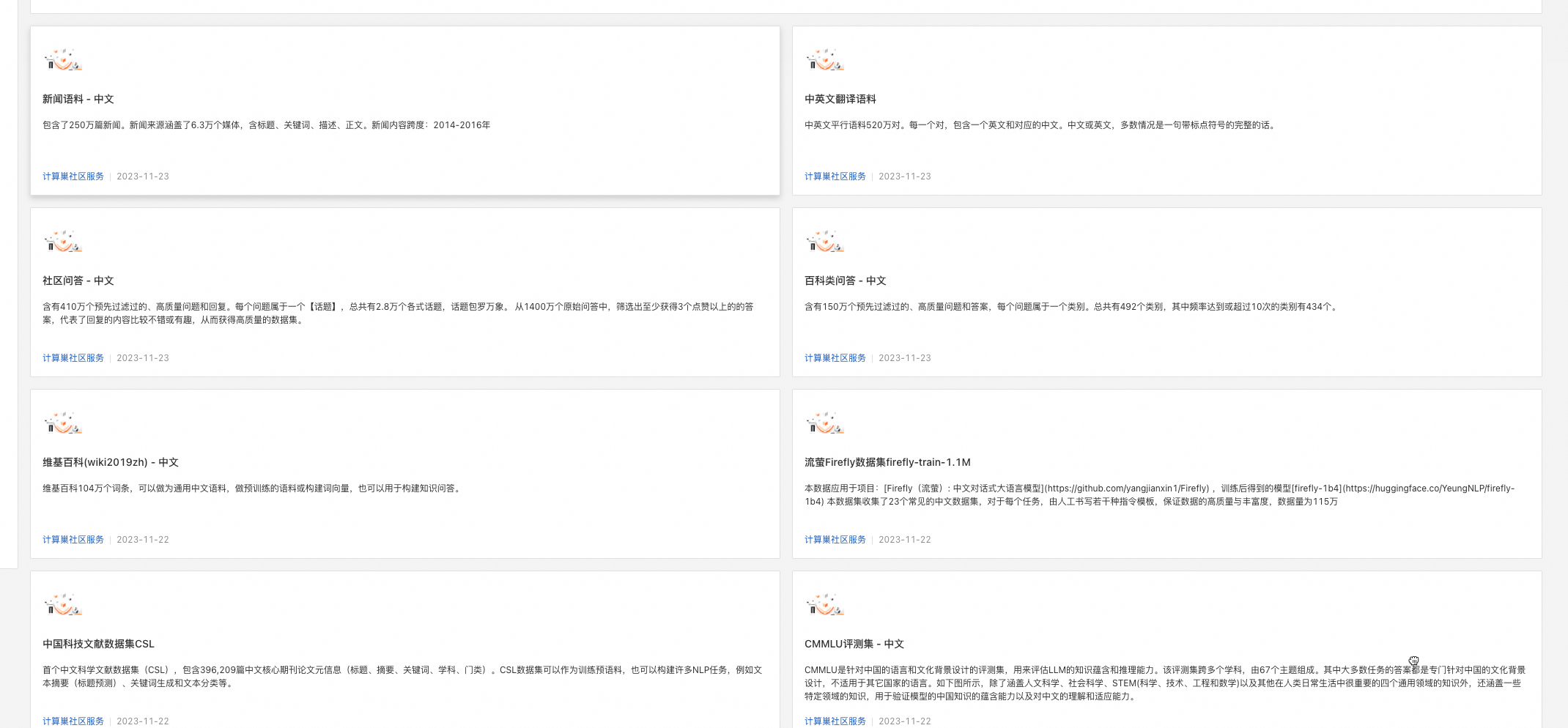
- 点击对应的数据集卡片,进入数据集主页。
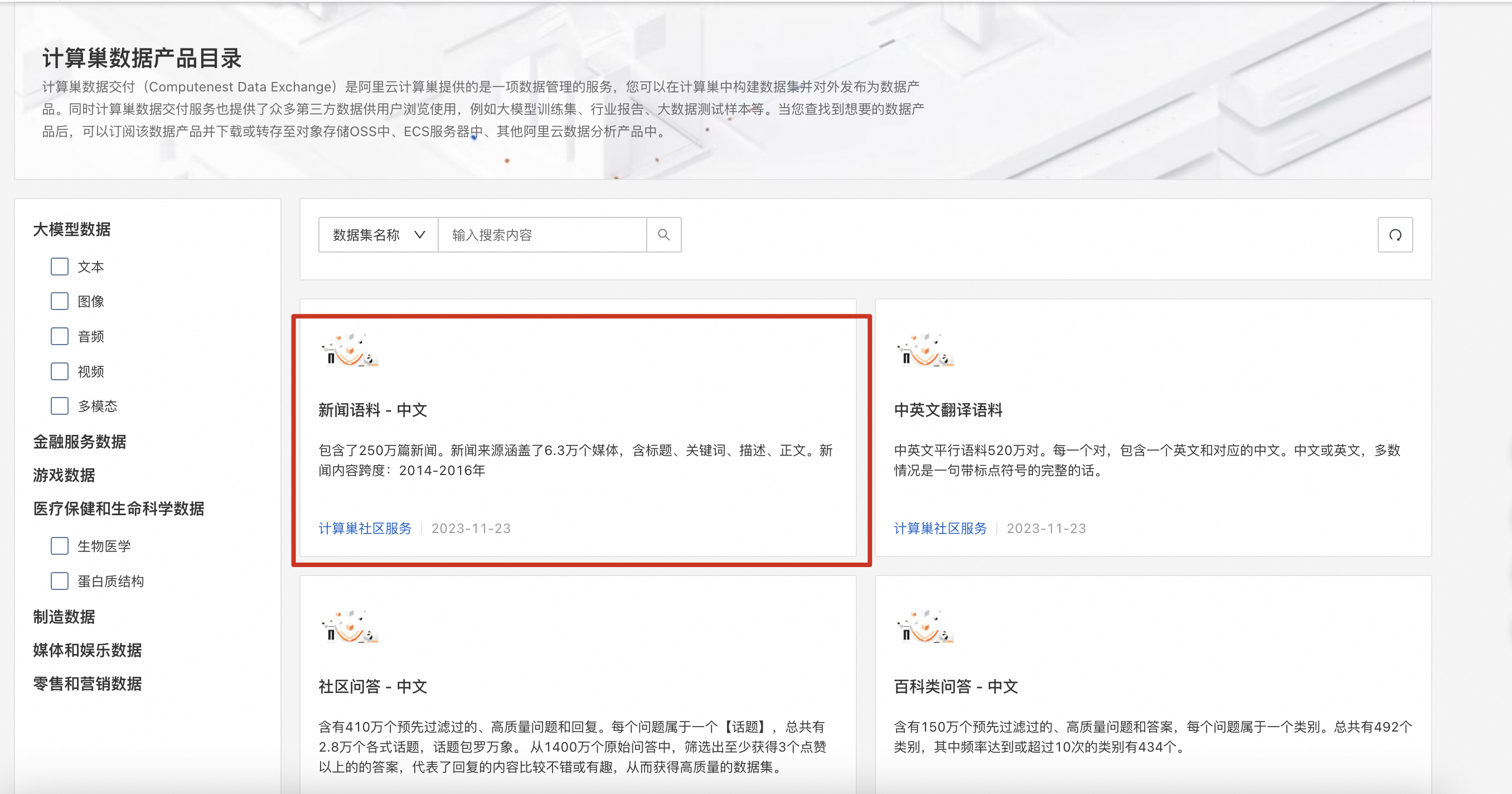
- 点击数据集名称下方的订阅案例,即可免费获得查看和下载该数据集的权限。注意,是完全免费!!!,当然前提是你得准备好自己的阿里云账号,没有也没关系,用手机号注册很快的~
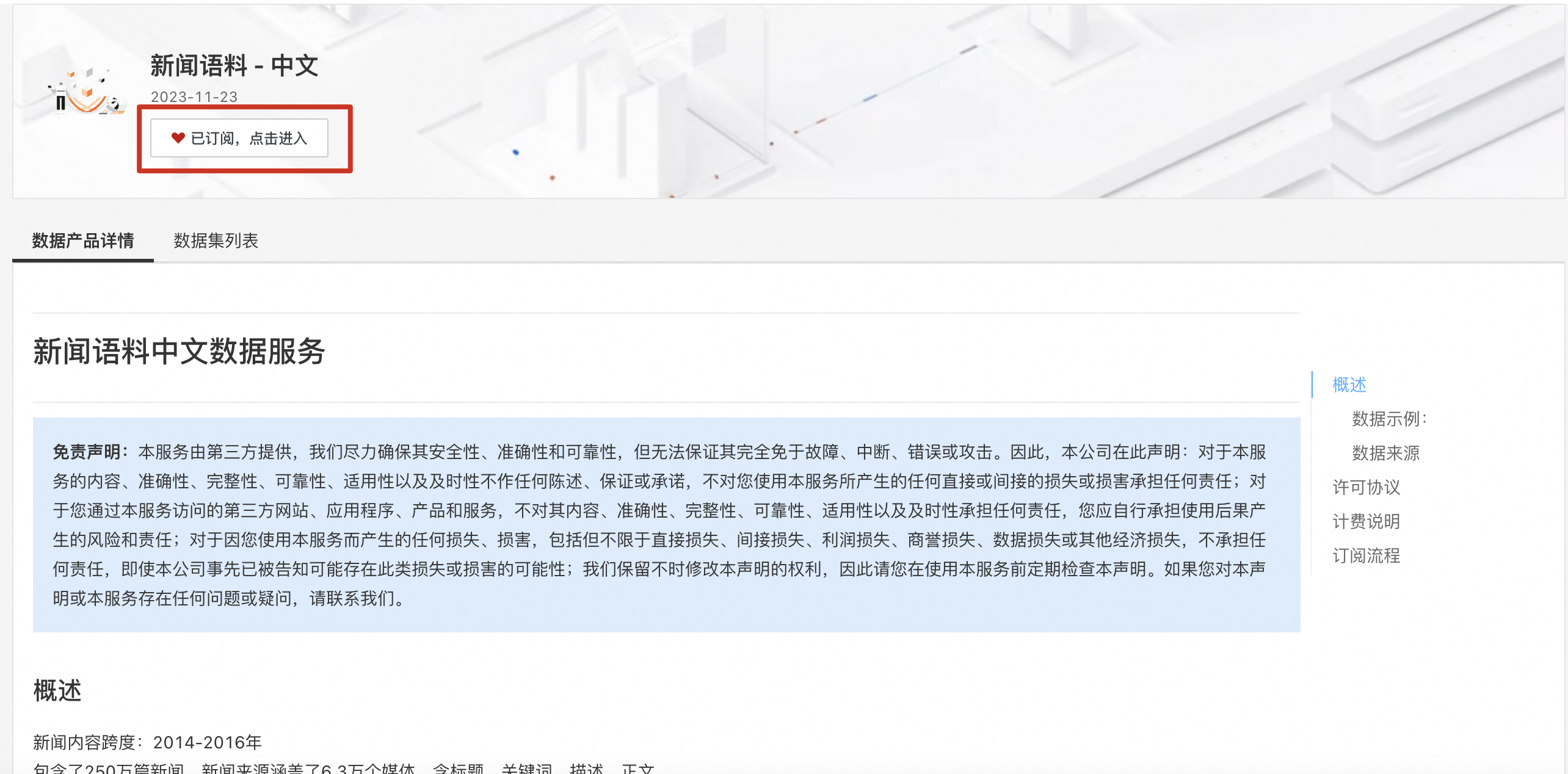
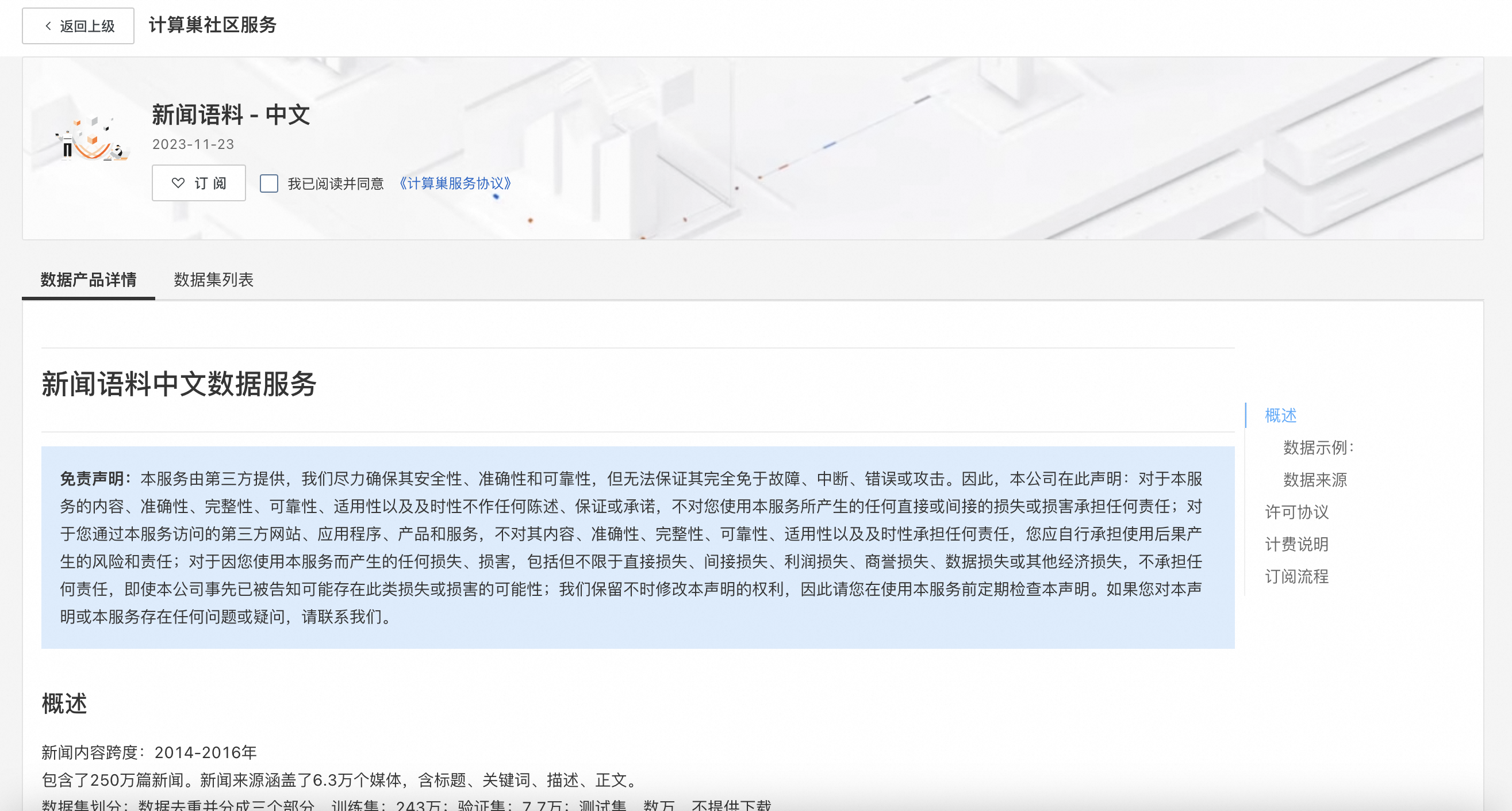
- 点击上方的订阅按钮进入到数据集详情页面,这里可以看到刚刚订阅的数据集的相关信息。点击“详情”就可以到我们最期待的数据集下载页面啦~
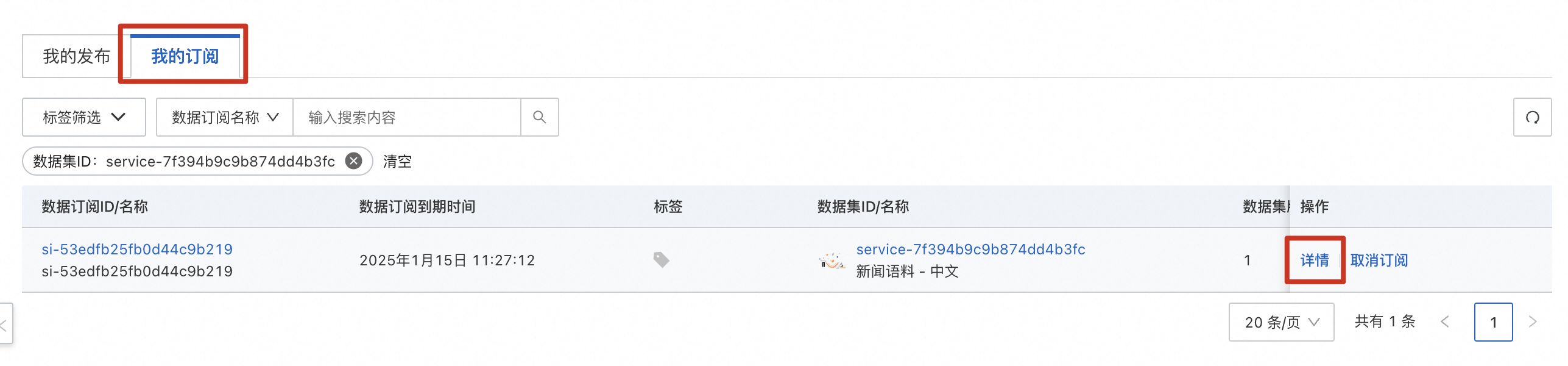
- 在详情页面点击“数据集”Tab,点击数据集名称左边的“+”展开菜单,就可以看到“导出到OSS”和“下载”按钮了。“导出到OSS”可以通过阿里云内网加速将数据集免费导入你自己的OSS存储,“下载”按钮可以将数据集下载到本地。
这里亲测,两种方式都比我使用“魔法”访问Huggingface快得多~注意,是快得多~~~
现在已经支持的数据集
据阿里云官方人员介绍,这个数据集市场正在不断完善和集成其他常用的数据集,目前已经支持的数据集有以下这些:
中文医学指令精调数据集
**简介:**医学知识库围绕疾病、药物、检查指标等构建,字段包括并发症,高危因素,组织学检查,临床症状,药物治疗,辅助治疗等,可以利用该数据集对ChatGLM或者LLaMA模型进行训练,提高模型在医疗领域的问答效果
订阅地址:https://computenest.console.aliyun.com/dataset/service/service-b23ee2aeb8fa4784bd31/detail/cn-hangzhou
示例数据:
{"context": "问题:患者反复出现反酸、烧心等症状,考虑为Barrett食管,需要注意哪些并发症?\n回答: ", "target": "根据知识,Barrett食管的并发症包括消化性溃疡、反流食管炎、胃肠道出血、贫血、肿瘤等,需要引起注意。"}
{"context": "问题:两岁女童出现发热、呼吸浅而快等症状,经过检查诊断为毛细支气管炎,治疗措施是什么?\n回答: ", "target": "给予鼻导管吸氧等方式进行支持治疗,并视情况使用抗生素治疗"}
{"context": "问题:患者赵先生最近出现恶心、呕吐等症状,经过检查发现患有胆石性胰腺炎,是否会影响生育和生活?\n回答: ", "target": "胆石性胰腺炎对于生育和生活的影响并不大,但是如果没有得到及时和有效的治疗,病情可能会不断恶化,对患者的生活和健康造成更严重的影响。因此,需要及时进行治疗,并根据医生的建议进行饮食和生活方面的调整,以保持良好的身体状态和生活质量。"}
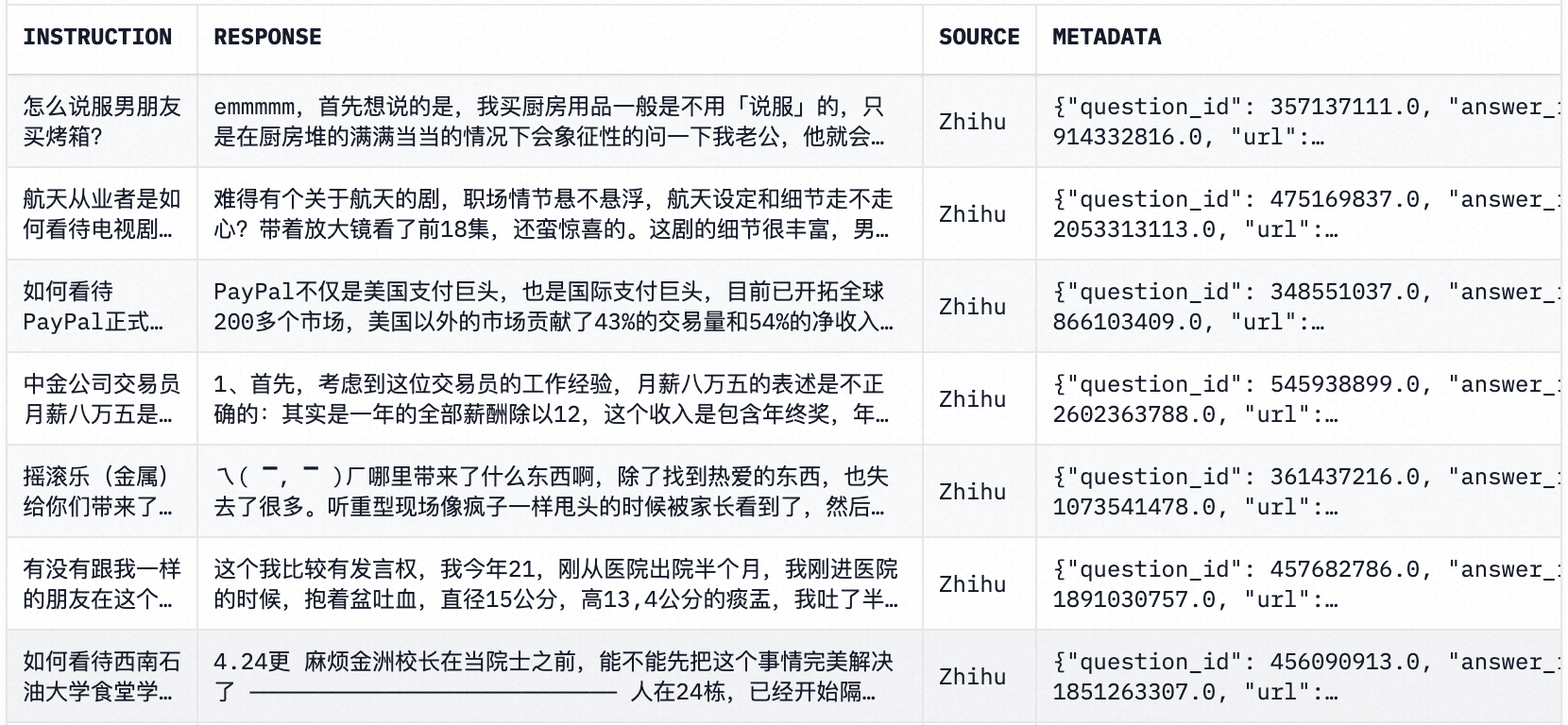
知乎问题答案数据集
**简介:**知乎问题答案,一个问题,多个答案,根据赞同数量排序
订阅地址:https://computenest.console.aliyun.com/dataset/service/service-63a78222b0d1499ca75c/detail/cn-hangzhou
示例数据:
CMMLU - 中文多任务语言理解评估
**简介:**CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。此外,CMMLU中的许多任务具有中国特定的答案,可能在其他地区或语言中并不普遍适用。因此是一个完全中国化的中文测试基准。
订阅地址:https://computenest.console.aliyun.com/dataset/service/service-007b4d87338548279dba/detail/cn-hangzhou
示例数据:数据集中的每个问题都是一个多项选择题,有4个选项,只有一个选项是正确答案。数据以逗号分隔的.csv文件形式存在
| Question | A | B | C | D | Answer | |
|---|---|---|---|---|---|---|
| 0 | 商业伦理学最早出现在 | 英国 | 法国 | 美国 | 意大利 | C |
| 1 | 伦理学的核心是 | 宗教伦理学 | 描述伦理学 | 元伦理学 | 规范伦理学 | D |
| 2 | 下列不属于人的基本权利的时 | 人格平等 | 独立 | 生命 | 自由 | B |
| 3 | 关税的课税客体是 | 进出境的货物 | 消费者 | 海关 | 进出口商 | A |
| 4 | 区域经济从本质上讲是 | 商品经济 | 一体化经济 | 信用经济 | 市场经济 | D |
firefly-train-1.1M
**简介:**收集了23个常见的中文数据集,对于每个任务,由人工书写若干种指令模板,保证数据的高质量与丰富度,数据量为115万本数据应用于项目:Firefly(流萤): 中文对话式大语言模型 ,训练后得到的模型firefly-1b4
订阅地址:https://computenest.console.aliyun.com/dataset/service/service-b16c8bb46bb44db9b49b/detail/cn-hangzhou
示例数据:
{"kind": "NLI", "input": "自然语言推理:\n前提:家里人心甘情愿地养他,还有几家想让他做女婿的\n假设:他是被家里人收养的孤儿", "target": "中立"}
{"kind": "Summary", "input": "在上海的苹果代工厂,较低的基本工资让工人们形成了“软强制”的加班默契。加班能多拿两三千,“自愿”加班成为常态。律师提示,加班后虽能获得一时不错的报酬,但过重的工作负荷会透支身体,可能对今后劳动权利造成不利影响。\n输出摘要:", "target": "苹果代工厂员工调查:为何争着“自愿”加班"}
{"kind": "Couplet", "input": "上联:把酒邀春,春日三人醉\n下联:", "target": "梳妆佩玉,玉王点一娇"}
{"kind": "MusicComment", "input": "生成音乐热评", "target": "1、感謝大家支持!然後就是Jane的人聲真的太好聽了,remix很自然就做出來了哈哈。為了讓人聲情感突出,這版本並沒有用太多搶耳的音色,只保留了一點點自己bass風格的律動感,然後我拿起一把Fender吉他就已經是主旋律了。Anyway , 超榮幸能參與這張專輯的! Enjoy!\n2、这首\n有种退一步现世安稳,进一步天地广阔的感觉\n好适合拿去当剪辑的BGM\n在成长逐渐变得温柔又坚强的那种"}
数据分布如下
维基百科 - 中文
**简介:**104万个词条(1,043,224条; 原始文件大小1.6G,压缩文件519M;数据更新时间:2019.2.7) ,可以做为通用中文语料,做预训练的语料或构建词向量,也可以用于构建知识问答。
订阅地址:https://computenest.console.aliyun.com/dataset/service/service-90c10fd0845e464daf17/detail/cn-hangzhou
示例数据:
百科类问答 - 中文
**简介:**含有150万个预先过滤过的、高质量问题和答案,每个问题属于一个类别。总共有492个类别,其中频率达到或超过10次的类别有434个。 可以做为通用中文语料,训练词向量或做为预训练的语料;也可以用于构建百科类问答;其中类别信息比较有用,可以用于做监督训练,从而构建更好句子表示的模型、句子相似性任务等。
订阅地址:https://computenest.console.aliyun.com/dataset/service/service-c0d46ce948b44f0f99d2/detail/cn-hangzhou
示例数据:

社区问答类 - 中文
**简介:**含有410万个预先过滤过的、高质量问题和回复。每个问题属于一个【话题】,总共有2.8万个各式话题,话题包罗万象。从1400万个原始问答中,筛选出至少获得3个点赞以上的的答案,代表了回复的内容比较不错或有趣,从而获得高质量的数据集。除了对每个问题对应一个话题、问题的描述、一个或多个回复外,每个回复还带有点赞数、回复ID、回复者的标签。
用途:
1)构建百科类问答:输入一个问题,构建检索系统得到一个回复或生产一个回复;或根据相关关键词从,社区问答库中筛选出你相关的领域数据
2)训练话题预测模型:输入一个问题(和或描述),预测属于话题。
3)训练社区问答(cQA)系统:针对一问多答的场景,输入一个问题,找到最相关的问题,在这个基础上基于不同答案回复的质量、
问题与答案的相关性,找到最好的答案。
4)做为通用中文语料,做大模型预训练的语料或训练词向量。其中类别信息也比较有用,可以用于做监督训练,从而构建更好句子表示的模型、句子相似性任务等。
5)结合点赞数量这一额外信息,预测回复的受欢迎程度或训练答案评分系统。

中英文翻译数据集
**简介:**中英文平行语料520万对。每一个对,包含一个英文和对应的中文。中文或英文,多数情况是一句带标点符号的完整的话。
订阅地址:https://computenest.console.aliyun.com/dataset/service/service-d3ed7dc9e15e4e3f9d72/detail/cn-hangzhou
示例数据:
新闻语料 - 中文
**简介:**包含了250万篇新闻。新闻来源涵盖了6.3万个媒体,含标题、关键词、描述、正文。新闻内容跨度:2014-2016年
可以做为【通用中文语料】,训练【词向量】或做为【预训练】的语料;也可以用于训练【标题生成】模型,或训练【关键词生成】模型(选关键词内容不同于标题的数据); 亦可以通过新闻渠道区分出新闻的类型。
订阅地址:https://computenest.console.aliyun.com/dataset/service/service-7f394b9c9b874dd4b3fc/detail/cn-hangzhou
示例数据:
没找到想要的数据集?
相比于其他平台,计算巢数据集对我们个人使用者来说还有一个好处,那就是可以非常方便的反馈自己想要的数据集。计算巢官方提供了一个钉钉群,我们可以加入到群中直接跟阿里云官方人员进行交流,他们会非常迅速的帮我们更新数据集,之前我一直想要的wiki数据跟他们反馈后几个小时就给我上架了,速度感人~泪目~
我把官方钉钉群放在后面了,有需要的小伙伴快和我一起进去白嫖吧~(谁能拒绝白嫖呢~)
钉钉群链接:链接~戳我戳我
群二维码:
















 1473
1473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









