





AI 读论文终极进化:从“摘要生成器”到“数字审稿人”
“Paper 如山倒,阅读如抽丝。”
如果你是一名研究生或科研人员,这句话恐怕早已是你的日常。面对每周数十篇的新文献,我们渴望高效地吸收知识,但现实却往往是在 PDF 的海洋中挣扎,耗费数小时才啃完一篇,细节还忘得一干二净。
自然而然地,我们想到了 AI。将论文链接或 PDF 丢给 ChatGPT,附上一句 “总结一下”,几秒钟后,一份看起来不错的摘要就出炉了。这在初期确实令人兴奋,但很快我们就会发现问题:这份“总结”太过表面。它能告诉你作者说了什么,却无法告诉你:
- 作者的统计方法用对了吗?前提满足吗?
- 这个结论是强证据支持,还是仅仅是“相关性”的暗示?
- 研究设计中是否存在潜在的混淆变量被忽略了?
- 如果我想复现这个实验,关键参数是什么?
这些问题,简单的“总结”无法回答。因为 AI 默认扮演的是一个“信息搬运工”,而不是一个“批判性思考者”。
今天,我将与你分享我的解决方案:一个“手术刀”级别的结构化 Prompt。它能引导 AI 像一位经验丰富的审稿人一样,对论文进行一次彻底的、解剖式的深度分析。
读完本文,你将获得一个可直接复制使用的“专家级” Prompt,并理解其背后的设计哲学。最终,你将能够把你的 AI 助手,从一个“泛泛而谈的实习生”,训练成一个“懂统计、重细节的数字审稿人”。
Part 1: 为什么通用 Prompt 会失败?——“总结”的陷阱
我们之所以对通用 Prompt 的输出感到失望,是因为我们对“读论文”的期望与 AI 的默认行为之间存在巨大的鸿沟。我们的目标是审阅 (Review),而 AI 做的是概括 (Summarize)。
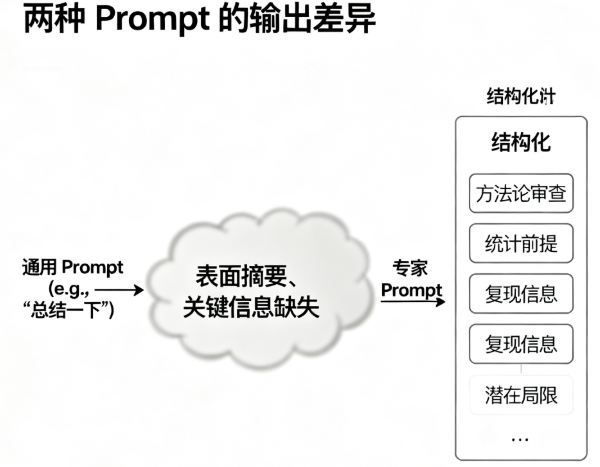
一个好的论文审阅,核心在于对方法论的批判性评估。而通用 Prompt 恰恰会“聪明地”避开这些最硬核、最容易出错的部分。结果就是,我们得到了一份看似完美的“无菌摘要”,却丢失了科学研究中最宝贵的“思辨过程”。
Part 2: “数字审稿人” Prompt 的设计哲学
要让 AI 从“实习生”蜕变为“审稿人”,我们的 Prompt 必须内置一套专家审稿的思维框架。我设计的这个 Prompt 主要遵循以下四个原则:
- 结构化拆解优于整体概括:我们不要求 AI “读懂”论文,而是命令它按照一个严格的框架去“拆解”论文。Prompt 中的 A 到 I 部分,就像一套手术器械,每一件都有其特定用途,确保论文的每个关键部分都被独立且详尽地检查。
- 方法论是审稿的核心:在整个 Prompt 中,对
Methods(C 部分) 的要求最为详尽和苛刻。我们强迫 AI 关注每个统计方法的适用前提、关键参数以及结果解读方式。这正是区分专业审稿与普通阅读的分水岭。 - 追求可复现性:科学的根基在于可复现。因此,Prompt 明确要求 AI 提取所有复现所需的关键信息,如软件版本、代码、关键参数、随机种子等。这等于在阅读时就为未来的复现工作铺平了道路。
- 从“被动接受”到“主动质询”:这份 Prompt 的语言是命令式和质询式的。它要求 AI 主动去检查统计前提是否满足、多重比较校正是否充分、是否存在 p-hacking 的嫌疑。这引导 AI 从一个信息的被动接受者,转变为一个主动的、带有批判性视角的分析者。
Part 3: Prompt 核心模块逐一解析
让我们来看看这套“手术器械”具体是如何工作的。
-
A-B 节: 快速定位
这两部分旨在 1 分钟内抓住论文的“骨架”(摘要结构化分析)和“灵魂”(引言逻辑链)。AI 会帮你快速梳理出研究要解决的核心问题、采用了什么设计、以及它在现有知识体系中的位置。 -
C 节 (核心): 方法学详检
这是整个 Prompt 的心脏。在这里,我们不再满足于“作者用了 t 检验”,而是追问:- 为什么用 t 检验? (为了比较两组均值)
- 它的前提是什么? (正态性、方差齐性、独立性)
- 数据满足前提吗? (Prompt 要求 AI 寻找证据)
- 如果不满足,替代方案是什么? (例如 Mann-Whitney U 检验)
通过这种方式,AI 会像一个统计学助教一样,帮你审视作者的方法选择是否合理。
-
D-E 节: 结果复盘
这两部分的核心是验证:作者报告的数值和图表,是否真的能支撑他们得出的结论?我们要求 AI 逐一核对图表,并提供原始检验统计量 (如t值、p值、置信区间),确保我们看到的是原始证据,而非作者的“一家之言”。 -
F-G 节: 压力测试
一篇优秀的论文必须能经受住各种“灵魂拷问”。F 节让 AI 扮演“魔鬼代言人”,主动寻找研究中可能被忽略的混淆因素。G 节则更进一步,要求 AI 主动提出稳健性检验的建议,比如“如果剔除这些异常值,结果是否依然显著?”这能极大地锻炼我们的批判性思维。 -
H-I 节: 价值升华
在完成所有技术细节的拆解后,H 节让 AI 对论文的结论强度给出一个综合评分(强/中/弱),并提出未来的研究方向。最后的 I 节则负责将所有分析结果整理成一份清晰、可交付的报告。
Part 4: 实战演练:如何使用这个 Prompt
理论讲完了,让我们进入实战。
第一步:准备材料
你需要一篇论文的全文,可以是 PDF 文件,也可以是公开的 URL。对于需要登录才能访问的论文,建议先下载到本地。
第二步:复制 Prompt 模板
下面是完整的 Prompt,我已经为你格式化好了,可以直接复制使用。
我需要对这篇医学/统计类论文做详尽的阅读与分析,输出中文笔记,格式严格按下面要求:
A. 摘要的结构化分析(要点化)
研究问题(1句)
假设(若有,逐条列出)
研究设计(队列/病例对照/随机/交叉/试验)
样本(样本量、纳入/排除标准、分组)
主要结局/测量指标(primary/secondary)
主要方法与统计策略(1–2 行)
主要结果(包含效应量、置信区间、p 值)
作者结论与主张(1句)
论文声明的局限(若摘要提及)
B. Introduction — 每段详细总结(不要遗漏单句)
对每一段写 2–4 句归纳,标明该段在逻辑链中的作用(背景/缺口/目标/假设)。
C. Methods — 逐节逐段详解(必须详尽)
对每一小节(参与者、采样、测量、预处理、统计分析、软件/版本、阈值等)按项目列出:
描述原始数据采集与关键预处理(采样率/滤波/重参考/缺失值处理/异常值规则/随机化方法/盲法)
对每个统计方法给出:
方法名称(例如:独立样本 t 检验 / Mann-Whitney / 聚类置换检验 / mixed-effects model / Cox 回归 / logistic 回归 / FDR 校正 / LASSO)
该方法做什么(原理一句话)
适用前提(正态性、方差齐性、独立性、样本量要求)
关键参数/如何运行(例如:混合效应模型固定效应与随机效应、协变量、连接函数、迭代次数、penalty type、alpha 值等)
统计结果如何解读(效应方向、效应量、置信区间、p 值、校正后的阈值)
多重比较如何校正(Bonferroni、FDR、cluster-based permutation 等),以及校正是否充分。
若使用机器学习方法,需列出数据划分策略、交叉验证细节、超参搜索、性能度量(AUC、敏感性、特异性、F1、校准曲线)与过拟合检测。
列出复现所需的全部信息:数据变量名/格式、关键代码片段或伪代码、软件/包及版本(例如 Python: numpy 1.x, MNE 1.x;R: lme4 1.x),以及随机种子。
D. Results — 结构化呈现
按表/图逐一说明:表/图的目标、样本数(N)、统计检验、主要数值(均值±SD、效应量、p、CI),作者结论是否由数据直接支持。
强调报告中重要数值:样本量、失访/剔除个数、试次数量(如果是生理信号)、每组有效试次。
对关键比较,要求提供原始检验统计量(t、df;Z;χ²;cluster p;τ 等)并解释。
E. 对每个实验与对照/干扰实验做“3 步分析模板”
对每个实验(或对照实验、敏感性分析)分别按下列格式写:
实验目的(为什么做这个实验)
实验/对照设计(被试、分组、测量时间窗、盲法)
详细方法(数据预处理、信号提取、统计检验、校正策略、显著性阈值、软件/包/参数)
结果(数值 + 统计量 + p/CI)
作者结论(是否合理)
额外建议/替代分析(例如:如果非正态可改用哪些检验;若样本量小是否需要 bootstrap;是否需要协变量校正)
F. 干扰与混淆因素(排查)
列出作者已检查的潜在混淆(并给证据)。
列出未充分检查的混淆与建议的补充检验(例如:交互项、分层分析、倾向评分匹配、灵敏度分析、对极端值的稳健回归)。
G. 统计稳健性与复现检测
要求实现至少两项额外稳健性检验(例如:替代模型、bootstrap、leave-one-out、剔除异常值后结果)并给出预期影响。
检查多重比较、p-hacking、选择性报告、样本量与检验功效(power)是否充分。
H. 讨论与结论评价
对作者主要结论的合理性打分(强/中/弱)并说明理由。
指出结论过度延伸或未被数据支持之处。
给出 3 条可行的后续研究建议(包含统计设计)。
I. 输出格式与交付物
最终输出请用中文,分章节(A–I)呈现;在方法/统计说明处用代码块列出关键步骤或伪代码;在结果处给出一个“关键数值表”(列出 N / 主要效应量 / CI / p / 检验类型)。
若论文附带公开数据或代码,列出可下载链接并简要说明如何运行以复现关键结果。
注意:在所有提到的统计方法处务必给出解释性说明,不要只写“用了 X 检验”,要说“为什么用 X 检验且其前提满足/不满足(并给证据)”。若数据不满足前提,则给出替代方案并说明潜在差异。
第三步:与 AI 互动
打开你喜欢的 AI 对话工具(如 ChatGPT-4, Claude 3 Opus 等,建议使用能力较强的模型),将复制的 Prompt 和论文信息一起发送给它。
你可以这样说:
请根据我提供的“数字审稿人” Prompt,分析这篇论文:[此处粘贴论文 URL 或上传 PDF]
第四步:批判性阅读 AI 的输出
最重要的一步来了。AI 生成的报告非常详细,但它仍然是助手,不是最终的决策者。你需要带着你的专业知识,去审阅 AI 的这份“审阅报告”:
- 它对统计方法的理解是否准确?
- 它发现的“潜在混淆”是否真的构成威胁?
- 它提出的“后续研究”是否有价值?

这个过程,不仅是对论文的分析,更是对你自己批判性思维能力的绝佳锻炼。
总结:这不仅是一个 Prompt
今天,我们分享的不仅仅是一个强大的 Prompt,更是一种全新的、与 AI 协作进行深度科研的思维模式。
通过结构化、批判性的指令,我们将 AI 从一个只会做表面文章的“摘要生成器”,升级为了一个能深入方法论细节、评估结论稳健性的“数字审稿人”。
代码的终极受众是人,而科研成果的终极检验标准,是其内在逻辑和外部证据的严谨性。希望这个工具能帮助你更高效、更深刻地理解每一篇你所阅读的文献。
现在就行动起来吧!
立即复制上方的 Prompt,去试试分析你正在读的下一篇论文。我相信,你会被结果所震撼。
欢迎在评论区分享你的使用体验,或者提出你对这个 Prompt 的改进建议!

















 3735
3735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









