







背景:
传统卷积神经网络,内存需求大,运算量大,导致无法在移动设备以及嵌入式设备上运行。

亮点:
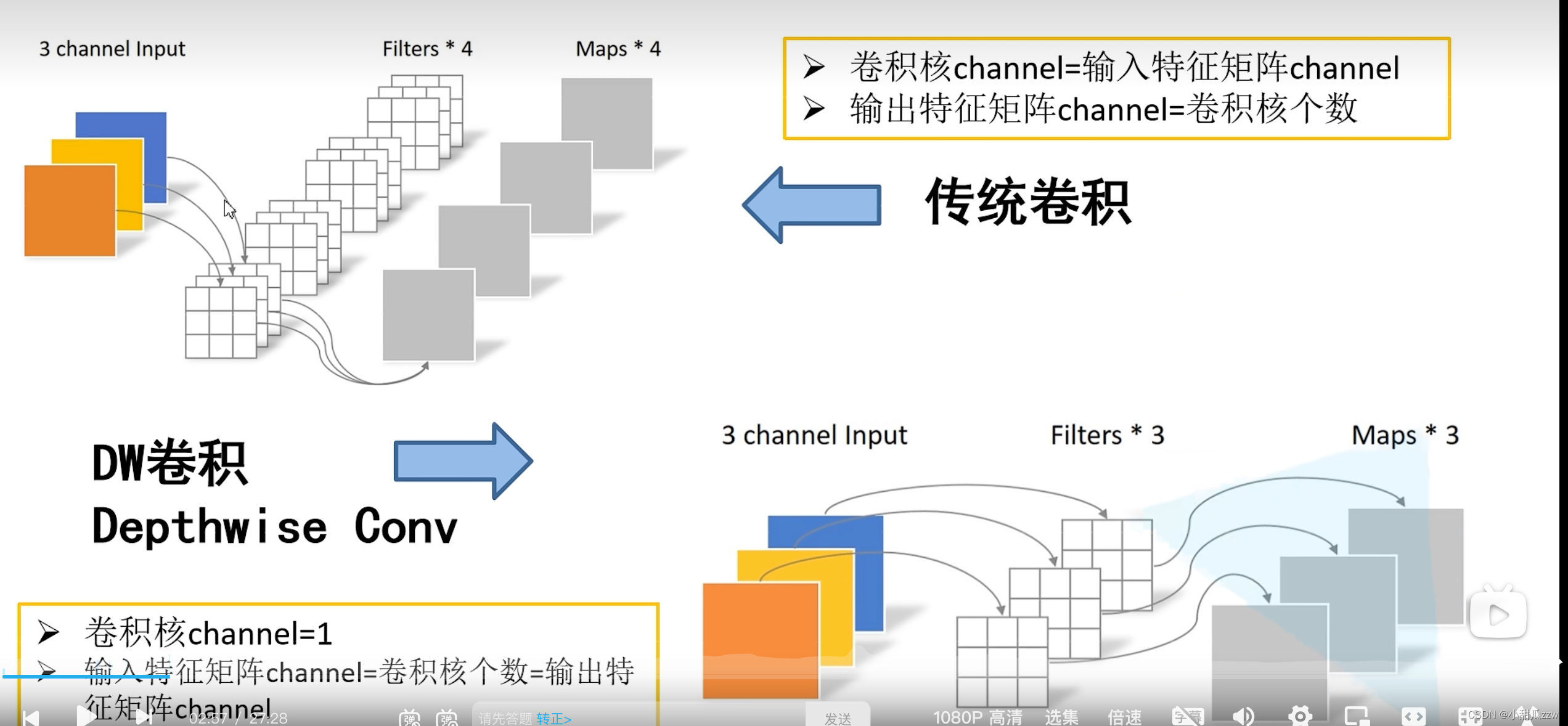
- Depthwise Convolution(DW卷积)(大大减少运算量和参数数量)
- 增加超参数(a,b)人为设定。
PW卷积:卷积核为1*1
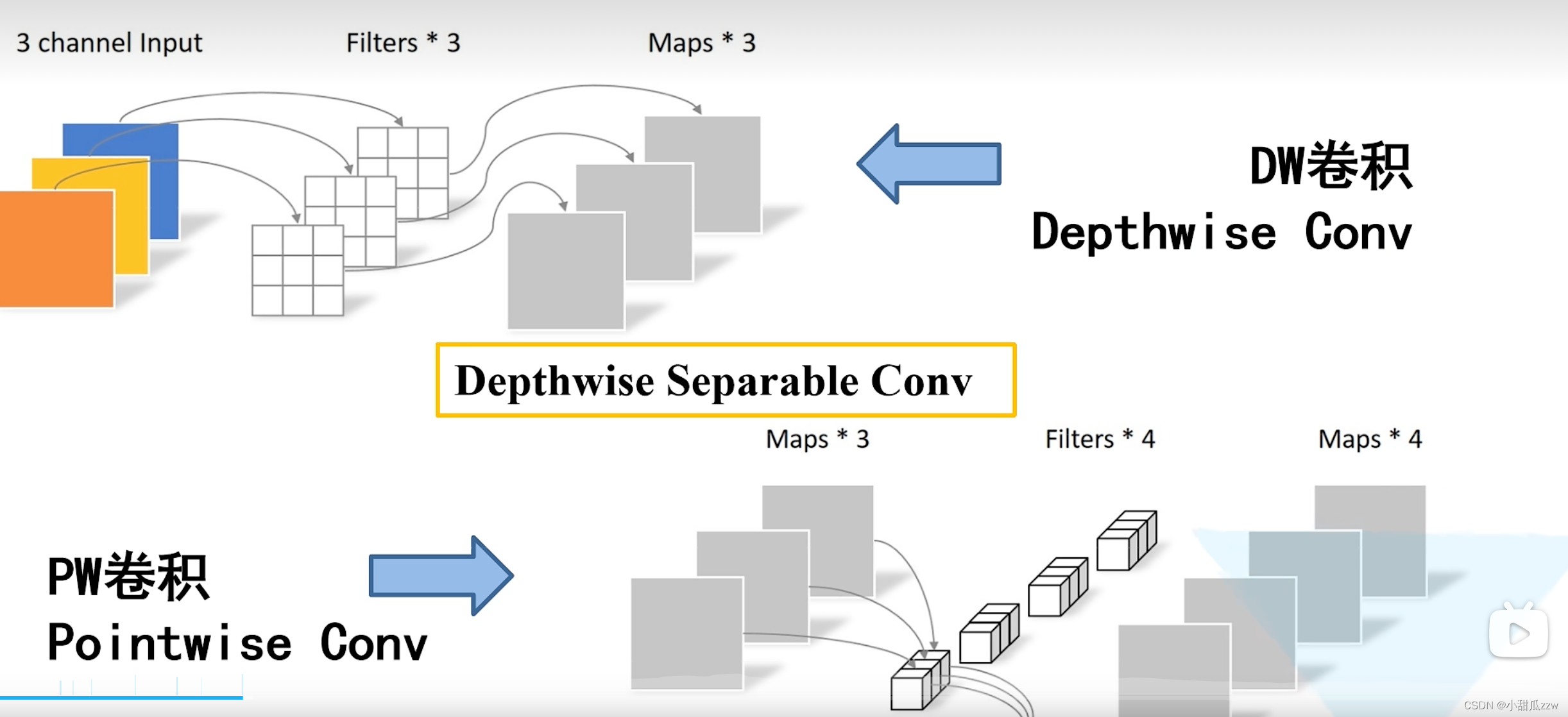
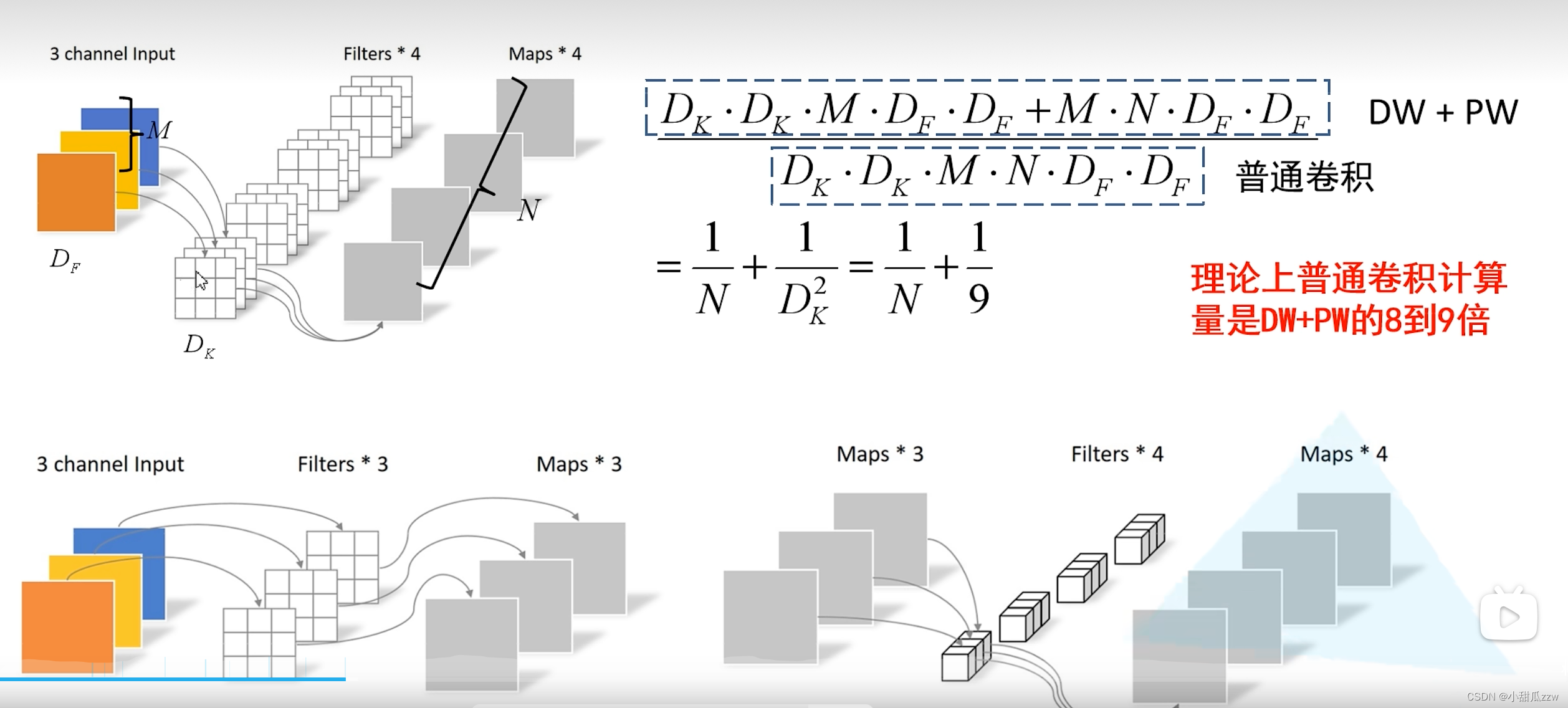
DW+PW卷积 和 普通卷积对比:
MobileNet v1
参数:
Conv/s2 :普通卷积,步距为2
33332:高 宽 * 输入矩阵深度 *卷积核个数
Conv dw:dw卷积
(有点像VGG,简单将网络串行链接)

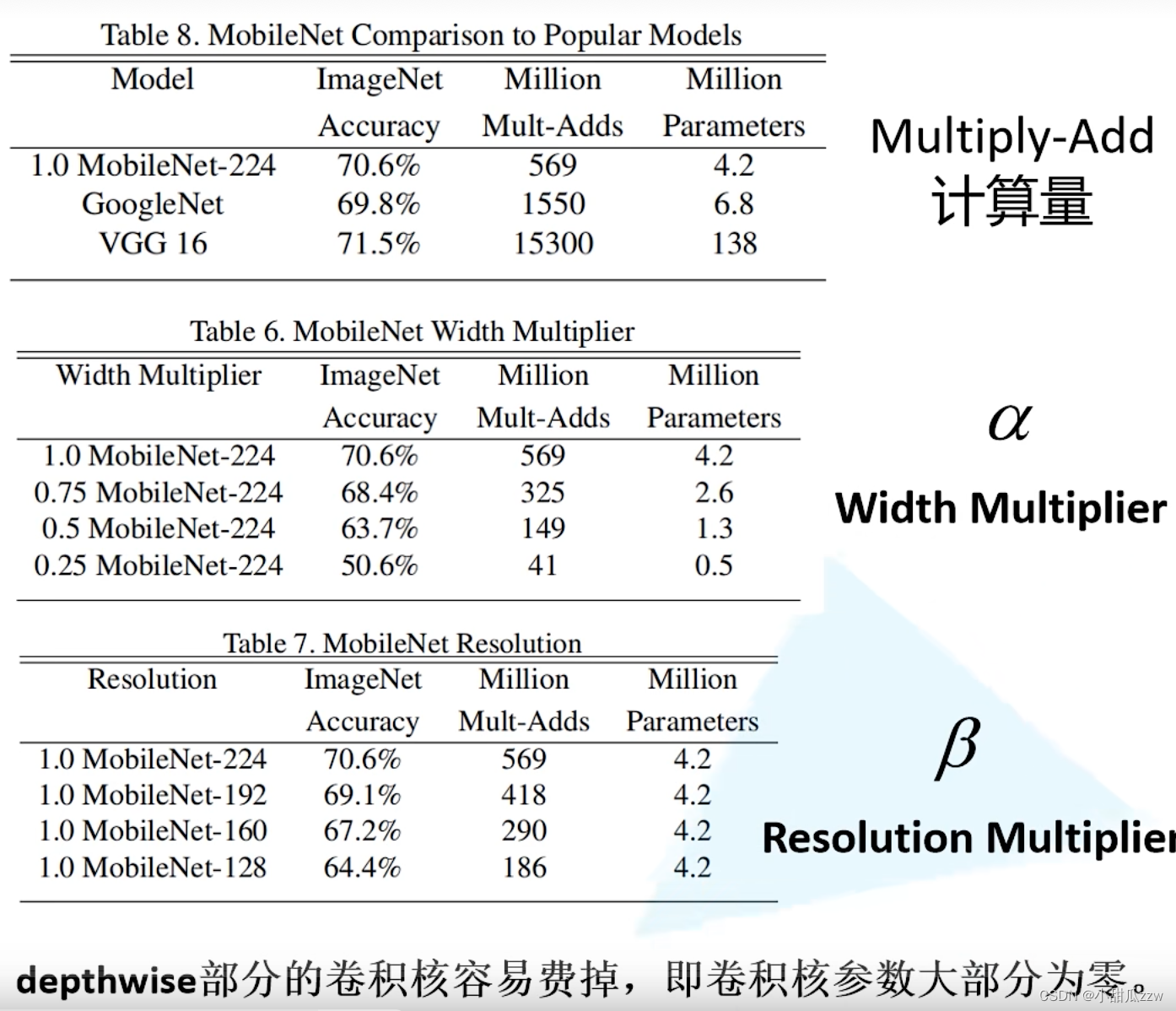
a:卷积核个数倍率 (multiplier 乘数)
b:分辨率参数 resolution(分辨率)
问题:dw卷积核参数大部分为0.
MobileNet v2
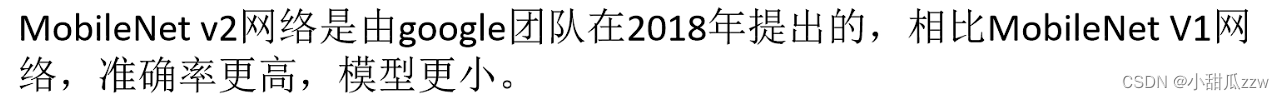
网络亮点:
- Inverted Residuals(倒残差结构)
- Linear Bottlenecks
残差和倒残差的区别:
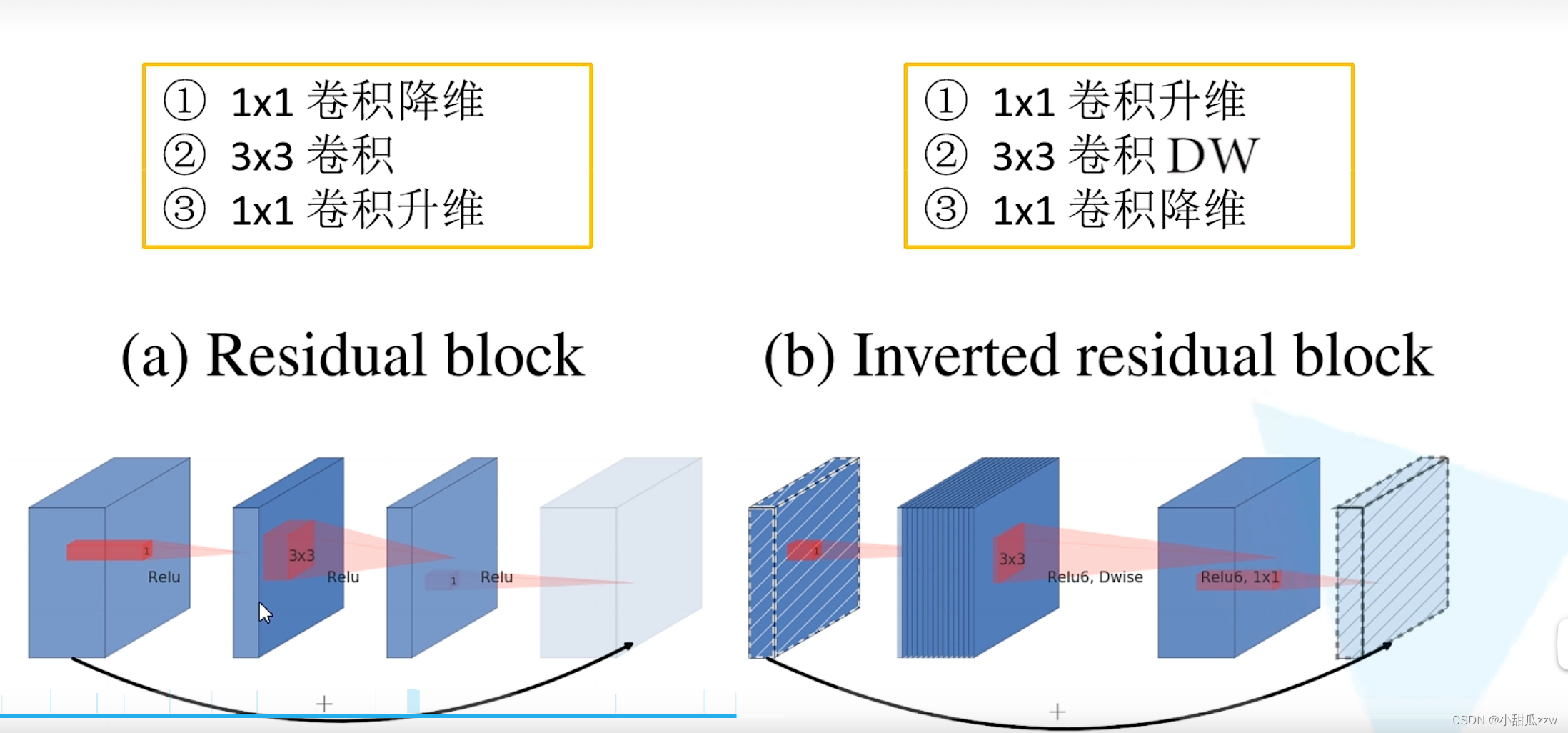
倒残差中relu6:
relu:对低维度特征信息造成大量损失,
(因为倒残差结构输出的时候维度比较低,所以需要线性激活函数替代非线性激活函数,来避免信息损失)

下图:
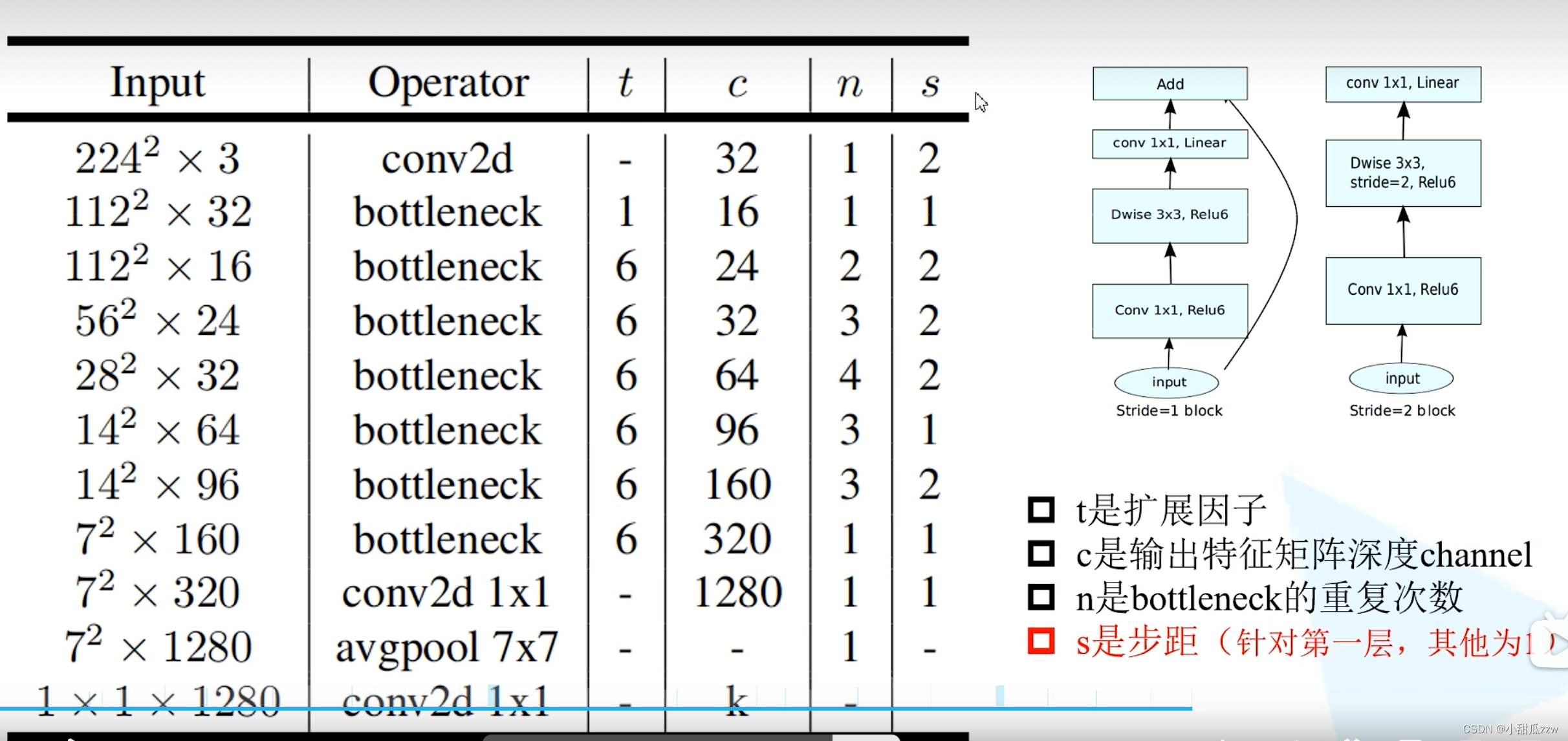
- t应该为11卷积核的个数,所以11卷积核可以升降维,但h和w不变
- 看第二行,stride为s,则输出的h和w变为原来的s分之一。
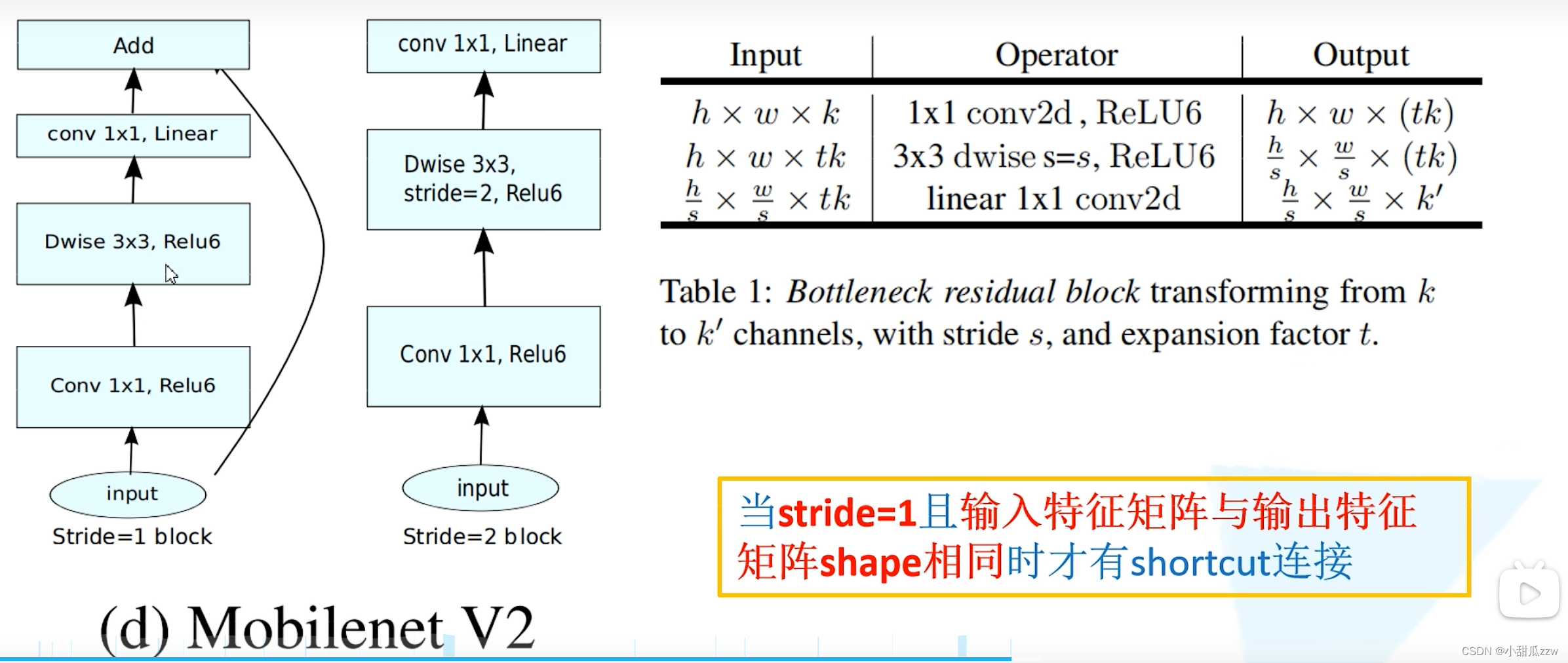
网络结构
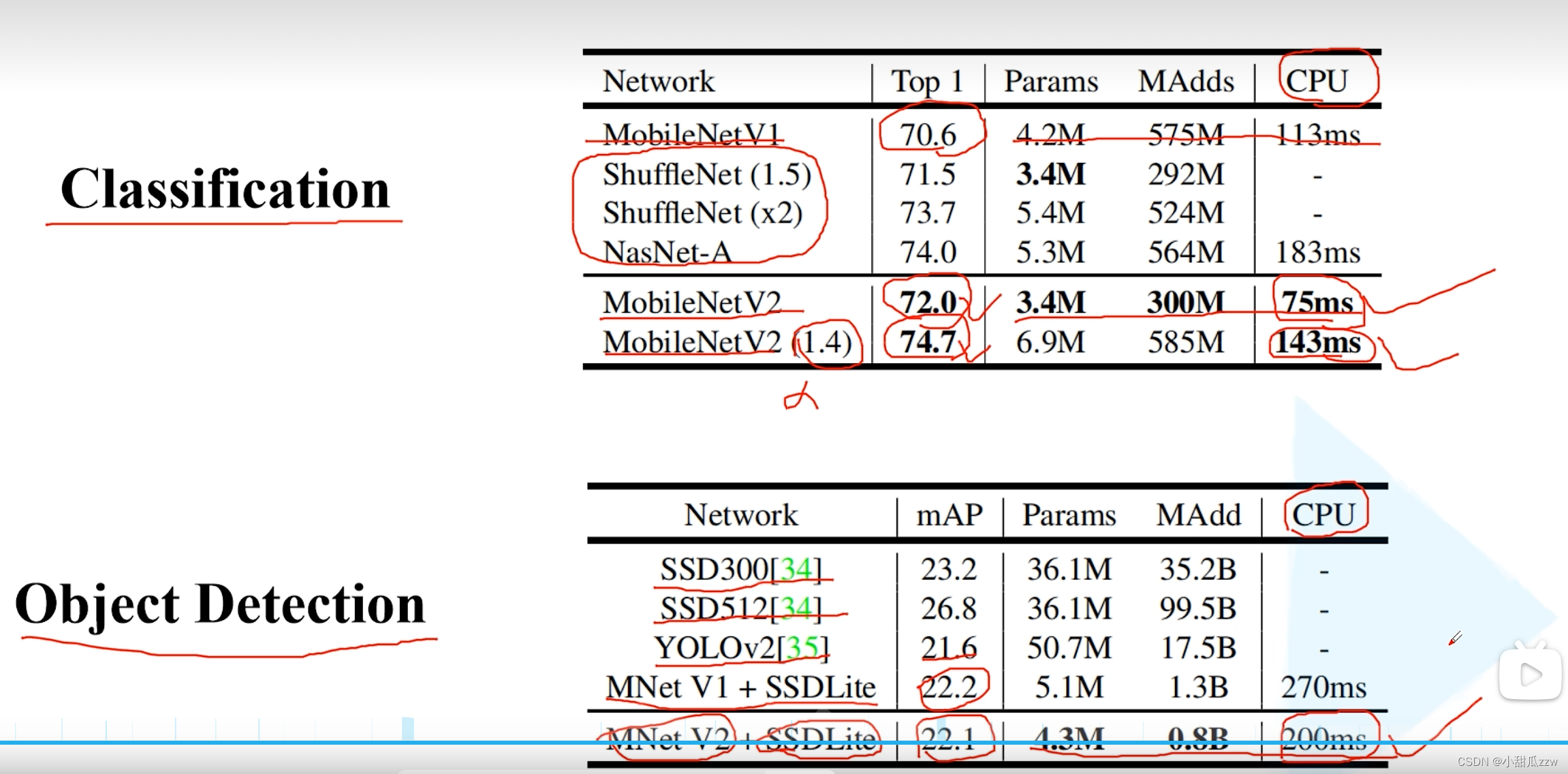
网络表现:
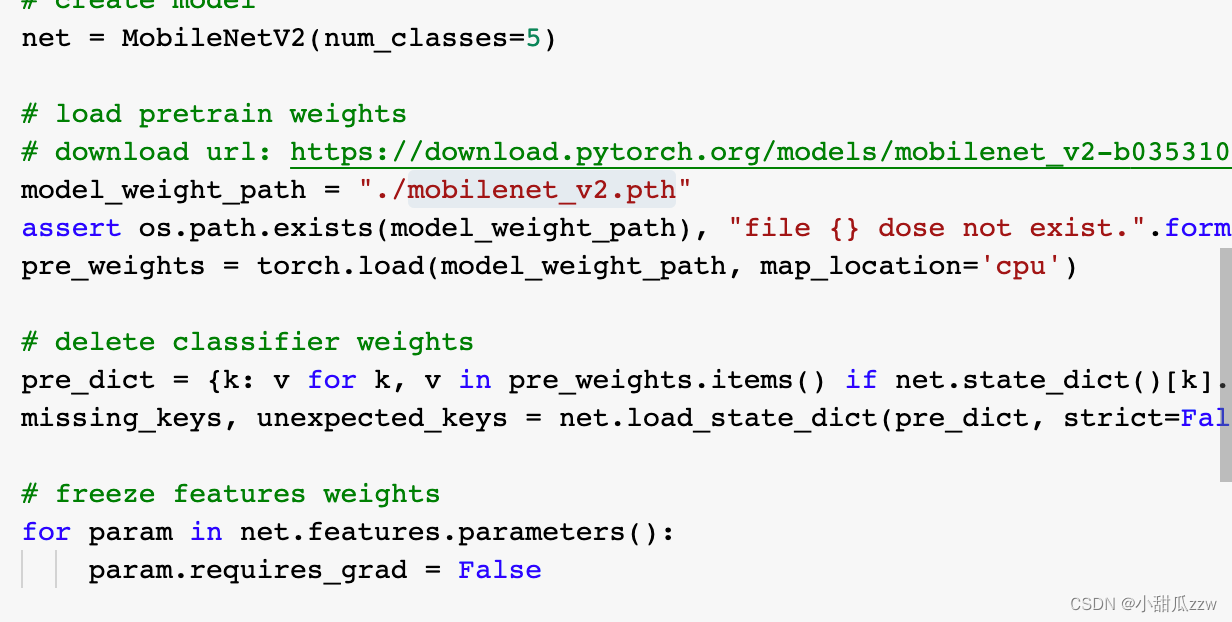
train.py
这里把最后一层改成5分类
把前边参数冻结
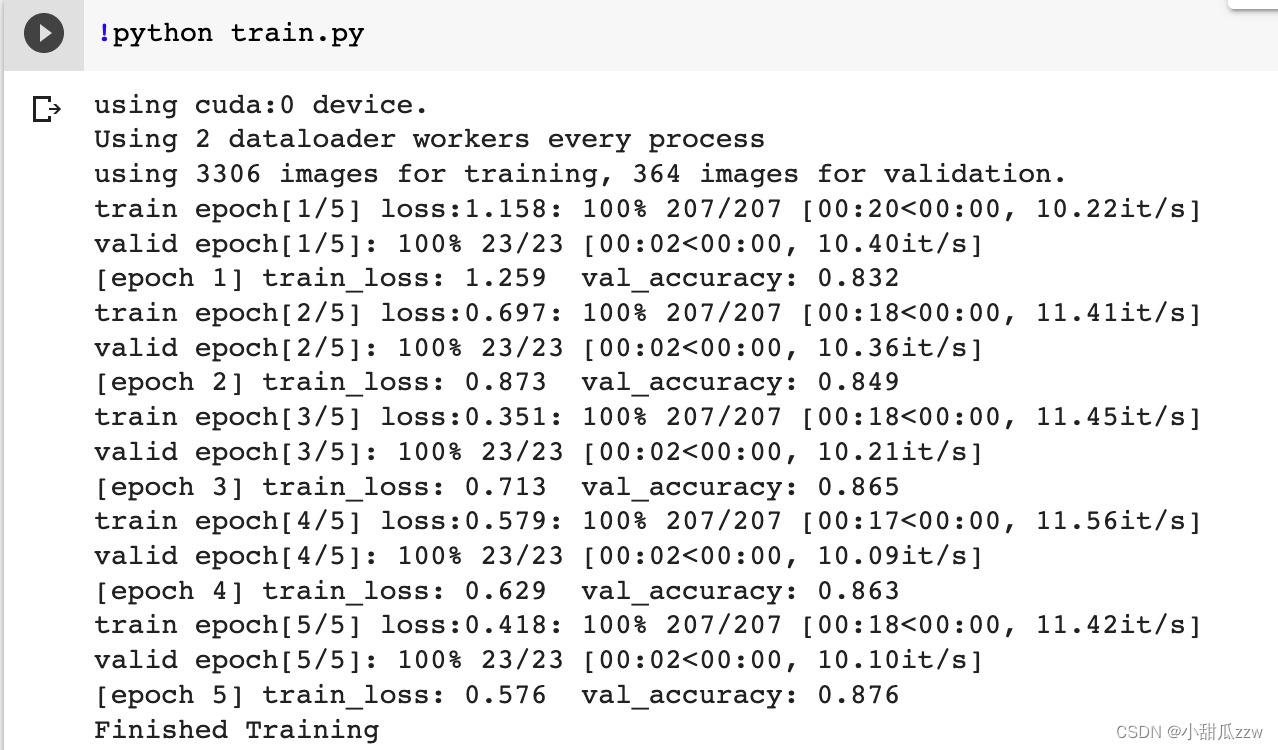
作者说 dw卷积在cpu上训练很慢
MobileNet v3
- 更新Block(bneck)
- 使用NAS搜索参数
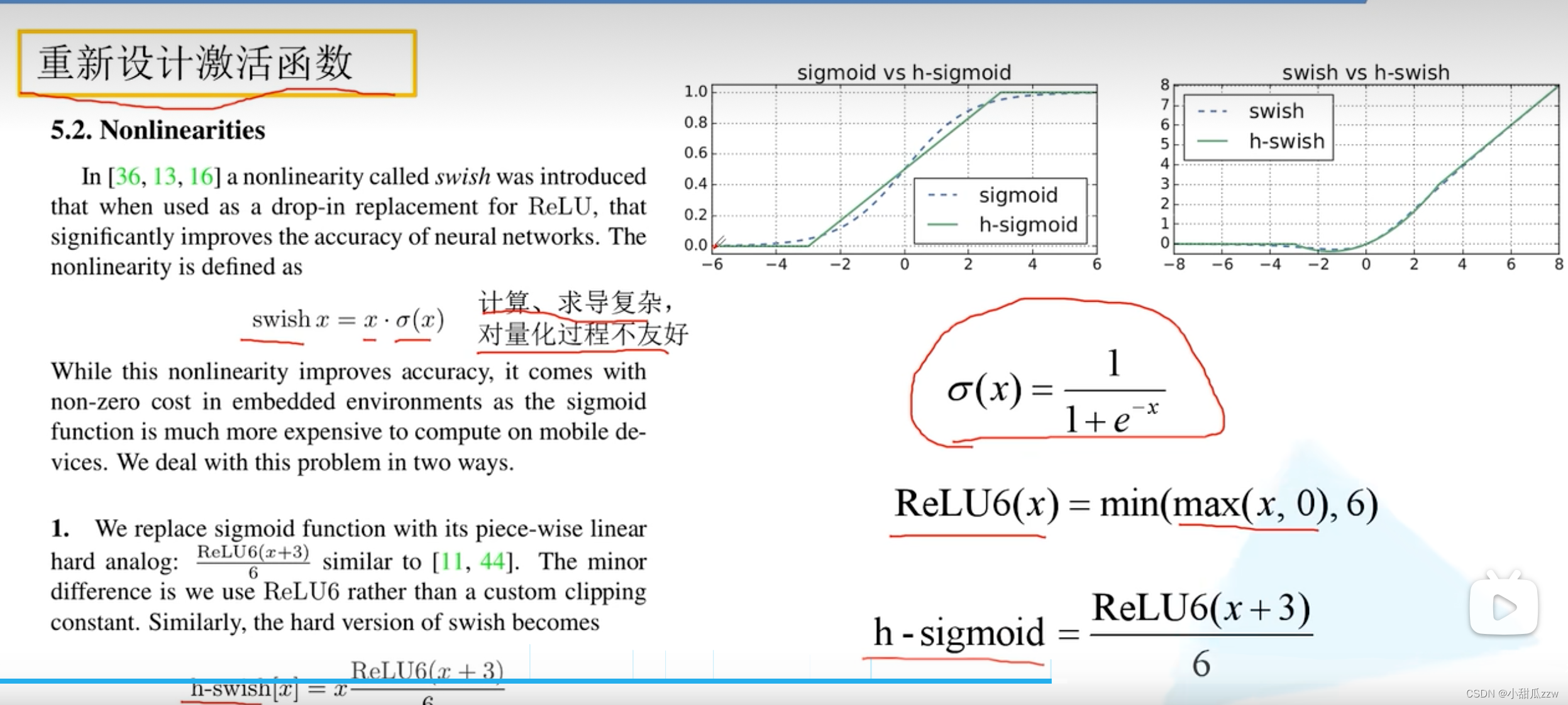
- 重新设计耗时层结构
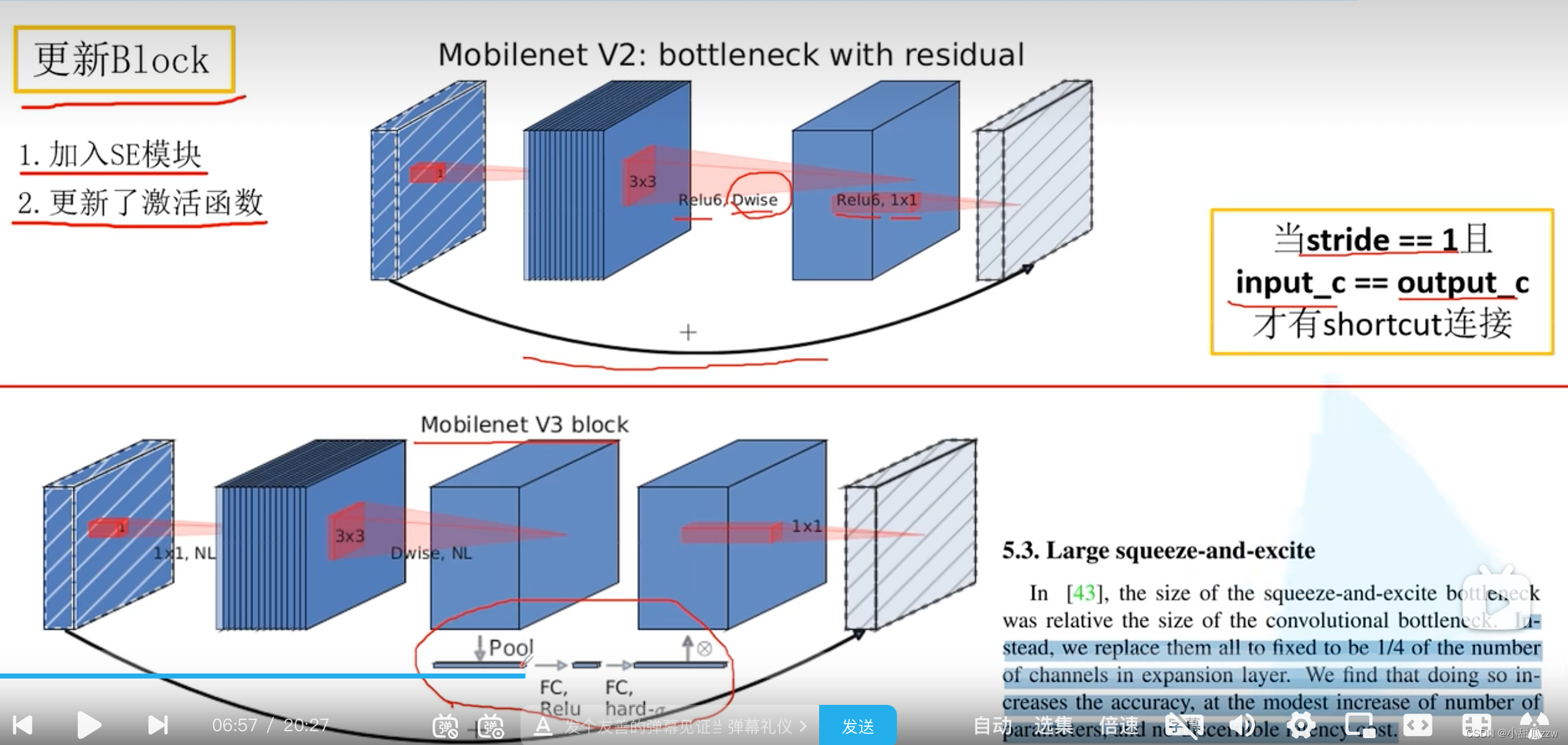
NL:非线性激活
se模块:

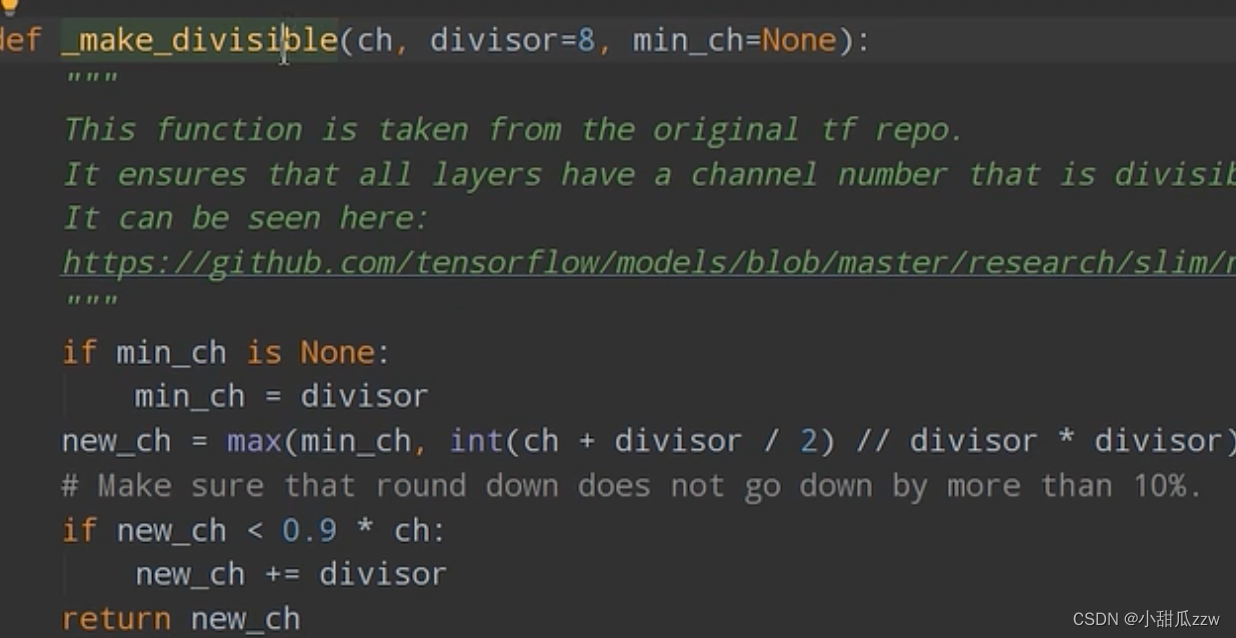
将传入的channel调整到离他最近的8的整数倍,这样对计算友好。
学到了什么:
- 如何在github看官方实现的代码















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









