







研究背景:
通过运用 R 语言对中国 GDP 进行回归分析与预测,可以进一步丰富和完善经济增长理论。这有助于检验和拓展现有的经济学模型,为经济研究提供新的视角和方法。例如,通过分析不同产业、投资、消费等因素对 GDP 的影响,能够深入理解经济增长的驱动机制,为经济理论的发展提供实证依据。
实践意义:
- 对于政府而言,准确的 GDP 预测能够帮助其制定合理的宏观经济政策,优化资源配置,促进经济的稳定增长和可持续发展。例如,根据 GDP 增长的预测结果,政府可以适时调整财政政策和货币政策,以应对可能出现的经济波动。
- 对于企业来说,了解中国 GDP 的发展趋势和影响因素有助于制定更加科学的经营策略。企业可以根据 GDP 的变化情况,调整生产规模、投资方向和市场布局,提高市场竞争力。
- 对于投资者而言,对中国 GDP 的准确分析和预测能够为其投资决策提供重要参考。例如,当 GDP 呈现良好增长态势时,投资者可以增加对相关产业的投资;反之,则可以采取更为谨慎的投资策略,降低投资风险。
实证分析
综上所述,运用 R 语言对中国 GDP 进行回归分析与预测具有重要的理论和实践意义,能够为政府、企业和投资者提供有价值的决策依据,促进中国经济的持续健康发展。
首先读取数据:
将GDP列转换为常规数字格式

# 可视化GDP数据
# 查看数据结构
# 确保数据类型是正确的
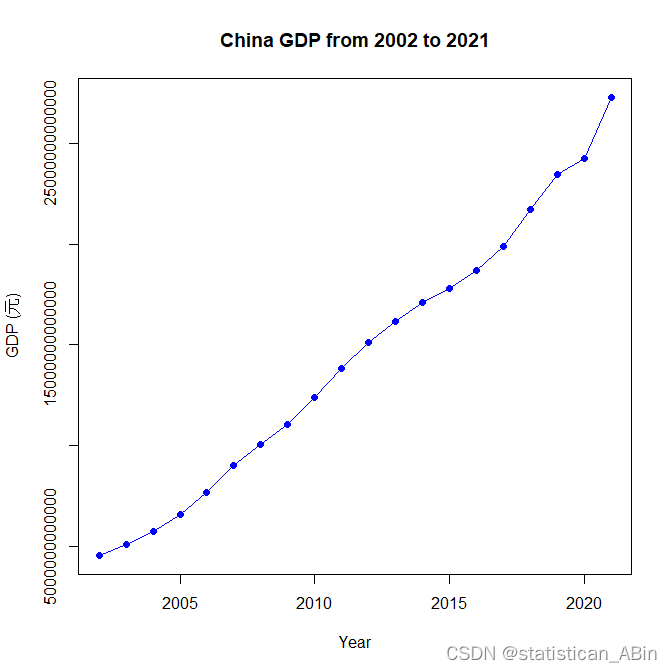
第一张图片展示了中国2002年到2021年间的GDP增长趋势,这是一个时间序列图,其中横轴表示年份,纵轴表示GDP(单位未标明,但通常是本国货币或美元)。从图中可以看出,这20年间,中国的GDP呈现出了显著的上升趋势,且增长速率在整个时间段内似乎是加速的,这可以从曲线的斜率增加看出。具体来看,GDP的增长不是线性的,而是有着一定的曲率,表明每年的增长量不是恒定的,而是随着时间的推移而增加。在2002年,GDP的值接近于图表纵轴的最低点,而到了2021年,它已经增长到接近顶部的位置。这种曲线上升的形态,特别是在后半段,可能表明经济增长的加速,可能是由于各种内外部因素的影响,如工业化进程加快、出口增加、内需扩大等。
进行线性回归分析

模型的公式是 GDP对年份(year)的线性回归,即 GDP ~ year。系数中,截距(Intercept)是负的,而年份(year)的系数是正的。年份的系数大约是11585326939,这意味着模型预测每过去一年,GDP平均增加约11585亿。标准误差(Std. Error)告诉我们每个系数估计值的精确度。在这里,年份的标准误差相对较小,表明估计值相当精确。t 值(t value)是系数除以标准误差得到的,用于测试每个系数的统计显著性。年份的t值非常高,表明年份对GDP的影响是统计上显著的。p 值(p-value)用于测试假设(在这个模型中是年份对GDP有影响)。年份的p值非常小,远小于0.05的常用显著性水平,这意味着年份的效果是非常显著的。残差标准误差(Residual standard error)表明实际数据点与拟合线的平均偏差大约是66820000000,这个数值的大小需要结合GDP的实际数值来看,但看起来误差相对于GDP的量级是较小的。拟合优度(R-squared)和调整后的拟合优度(Adjusted R-squared)分别是0.9911和0.9906,都非常接近1,这表明模型对数据的拟合度非常高,几乎所有的变异都可以由年份来解释。
总结来说,线性回归模型表明从2002年到2021年,中国GDP的增长与年份有着非常强的线性关系,模型的拟合度非常高。
随后预测2022年的GDP
"Predicted GDP for 2022: 26538180032062"
将预测值与实际2022年的GDP进行比较,2022年的为30250000000000
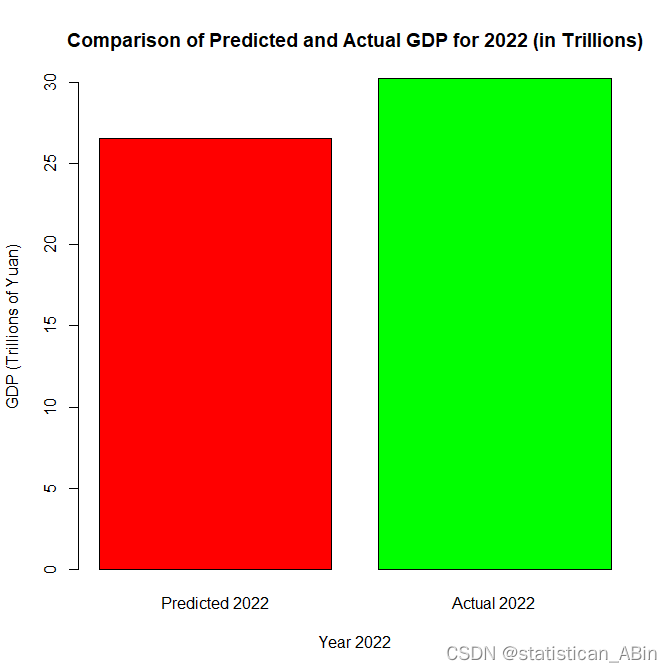
这张图展示了2022年中国GDP的预测值与实际值的对比。图中有两个柱状图,分别代表预测的GDP(红色)和实际的GDP(绿色),单位是万亿元人民币。
从图中可以看出,预测的GDP还是比较接近实际的GDP。但是有些些许的差距:
这种差异可能由多种因素造成,包括:
预测模型可能没有考虑某些重要的经济增长驱动因素。
模型可能未能捕捉到的非线性趋势或结构性变化。
2022年可能出现了特殊事件或变动(疫情等等),这些是在先前的数据中无法预见的。
本文代码:
# 加载所需的库
library(ggplot2)
library(readr)
library(dplyr)
library(broom)
# 避免科学计数法
options(scipen = 999)
# 读取数据
gdp_data <- read_csv("C:/Users/Administrator/Desktop/GDP.csv")
# 将GDP列转换为常规数字格式
gdp_data$GDP <- format(gdp_data$GDP, scientific = FALSE)
# 再次查看数据
head(gdp_data, 10)
# 可视化GDP数据
# 查看数据结构
# 确保数据类型是正确的
gdp_data$year <- as.numeric(gdp_data$year)
gdp_data$GDP <- as.numeric(gdp_data$GDP)
# 使用plot函数绘制折线图
plot(gdp_data$year, gdp_data$GDP, type = "o", col = "blue",
main = "China GDP from 2002 to 2021",
xlab = "Year", ylab = "GDP (元)",
pch = 16, lty = 1)
# 线性回归分析
gdp_model <- lm(GDP ~ year, data = gdp_data)
# 查看模型摘要
summary(gdp_model)
# 预测2022年的GDP
predicted_2022 <- predict(gdp_model, newdata = data.frame(year = 2022))
# 打印预测值
print(paste("Predicted GDP for 2022: ", predicted_2022))
# 将预测值与实际2022年的GDP进行比较
actual_2022 <- 121020700000000 # 您提供的2022年GDP数据
# 将预测值与实际2022年的GDP进行比较
# 2022年GDP的实际值和预测值
actual_2022 <- 30250000000000
predicted_2022 <- 26538180032062
# 将数值转换为万亿单位
actual_2022_trillion <- actual_2022 / 1e12
predicted_2022_trillion <- predicted_2022 / 1e12
# 创建一个包含这些值的向量
values <- c(predicted_2022_trillion, actual_2022_trillion)
names <- c("Predicted 2022", "Actual 2022")
# 绘制柱状图
barplot(values, names.arg = names, col = c("red", "green"),
main = "Comparison of Predicted and Actual GDP for 2022 (in Trillions)",
ylab = "GDP (Trillions of Yuan)",
xlab = "Year 2022")
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









