







一、研究背景和意义
GDP 是宏观经济中最受关注的经济统计数字,目前我国国内生产总值年均增长率均明显高于同期美、日等发达经济体和巴 西、俄罗斯、南非、印度等其他金砖国家,成为世界经济增长的主力军,GDP 的增长对一个国家有着十分重要的意义,它衡量一国在过去 的一年里所创造的劳动成果,而研究它的影响因素不仅可以很好的了解 GDP 的经济内涵,而且还有利于我们根据这些因素对 GDP 影响大小来宏观经济的有效调控。
因此本文选取1990-2020年的GDP、税收等数据,数据为东方财务网爬取而得,其中包括人口(population),固定资产投资(fixed_investments),消费(consumption_level),净出口(total_export_import_volume),税收(tax),广义M2货币,物价指数(CPI),上述变量作为解释变量X,我国GDP作为被解释变量y,使用多元回归模型对我国GDP增长的因素进行分析。
二、文献综述
戚顺欣(2017年)选取2006年到2013年八年内的沈阳市GDP数据,利用多元回归模型,从多方面入手,选择多个影响因子分析沈阳市GDP增长的主要影响因素[1]。郭崇文(2016年)选取了三个因素,使用eviews软件对GDP与这些因素建立计量模型,并进行相关的统计检验和修正,对我国的经济发展提供借鉴意义[2]。卢金凤(2015年)通过搜集2010年、2013年重庆市能源消费量及地区生产总值,对单位生产总值能耗完成"十二五"规划进行检查和分析,总结完成目标的经验,以便为我国完成降耗目标起到借鉴作用[3]。.....
三、算法原理
....
四、实证分析
数据预处理的四个步骤分别是数据清洗、数据集成、数据变换和数据归约。
进行数据清理是因为现实世界的数据一般是不完整的、有噪声的、是不一致的。数据清理流程试图填充缺失的值、光滑噪声并识别离群点、纠正数据中的不一致。数据集成是指合并来自多个数据存储的数据。数据规约指可以用来得到数据集的规约表示,它小得多,但仍接近于保持原始数据的完整性。数据变换是指将数据格式转变,如将数据变为数值型、分类型数据等等。数据预处理,一方面是为了提高数据的质量,另一方面也是为了适应所做数据分析的软件或者方法。当然了,这四个大步骤在做数据预处理时未必都要执行,在许多情况下完成前两个步骤就可以对数据开始进行分析了。
本文选取1990-2020年的GDP、税收等数据,数据为东方财务网爬取而得,其中包括人口(population),固定资产投资(fixed_investments),消费(consumption_level),净出口(total_export_import_volume),税收(tax),广义M2货币,物价指数(CPI),上述变量作为解释变量X,我国GDP作为被解释变量y。首先进行数据展示,如图1所示。
具体描述性统计如下,其中包括了各个变量的最大值、最小值、中位数、1/4分位数和3/4分位数等,如表2所示。
install.packages("openxlsx")
library(openxlsx)
# 文件名+sheet的序号
dataset<- read.xlsx("D:/例题/影响经济增长的因素(随机森林回归)/data.xlsx", sheet = 1)
#View(dataset)
dataset
summary(dataset)#####描述性统计分析表 1 数据整体性描述
| GDP | population | Fixed_investments | Consumption_level | ||||
| min | 18923 | min | 114333 | min | 4517 | min | 825 |
| 1st Qu | 81310 | 1st Qu | 124194 | 1st Qu | 26674 | 1st Qu | 3033 |
| median | 185999 | median | 130756 | median | 80994 | median | 5671 |
| mean | 333476 | mean | 129859 | mean | 171118 | mean | 9489 |
| 3rd Qu | 562735 | 3rd Qu | 136324 | 3rd Qu | 305501 | 3rd Qu | 14845 |
| max | 1008783 | max | 141212 | max | 527270 | max | 29210 |
| Import_export_volume | tax | M2 | CPI | ||||
| min | 5560 | min | 2822 | min | 15293 | min | 98.6 |
| 1st Qu | 26908 | 1st Qu | 8748 | 1st Qu | 97747 | 1st Qu | 101.5 |
| median | 116922 | median | 28779 | median | 298756 | median | 102.6 |
| mean | 133990 | mean | 55933 | mean | 619342 | mean | 103.4 |
| 3rd Qu | 243773 | 3rd Qu | 105572 | 3rd Qu | 1040337 | 3rd Qu | 104.3 |
| max | 322215 | max | 158000 | max | 2186796 | max | 117.1 |
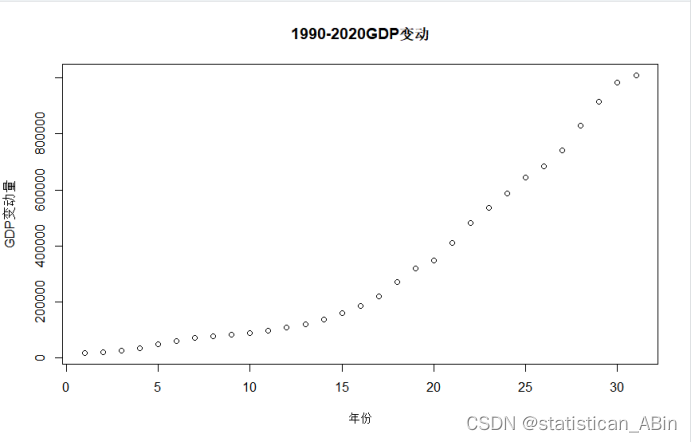
首先画出1990-2020年GDP的走势情况:
画出特征变量的箱线图,看其分布形状
par(mfrow = c(2, 4)) #让图片以2行5列的形式排列在一张图上
boxplot(dataset$population, main = "population")
boxplot(dataset$fixed_investments, main = "fixed_investments")
boxplot(dataset$consumption_level, main = "consumption_level")
boxplot(dataset$total_export_import_volume, main = "total_export_import_volume")
boxplot(dataset$tax, main = "tax")
boxplot(dataset$M2, main = "M2")
boxplot(dataset$CPI, main = "CPI")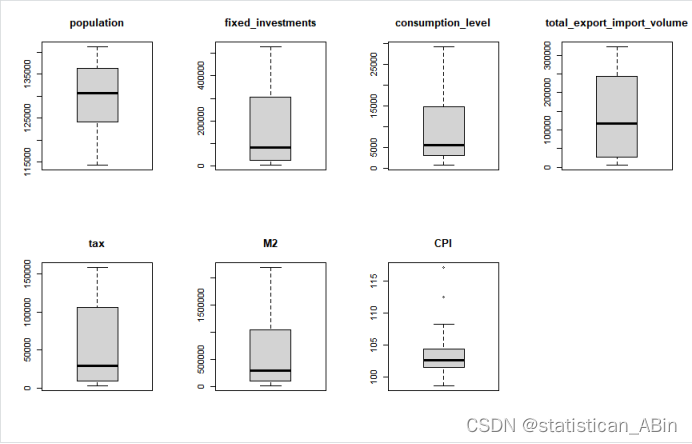 由图可得,7个特征变量均分布较好且异常值很少。再用ggpairs函数展示出变量间的相关性,以及从下图中的相关系数中也可得出其相关性。
由图可得,7个特征变量均分布较好且异常值很少。再用ggpairs函数展示出变量间的相关性,以及从下图中的相关系数中也可得出其相关性。
随后算出各个变量直接的相关系数,如下
| GDP | 人口 | 固定资产 | 消费 | 净出口 | 税收 | M2 | 物价指数 | |
| GDP | 1 | 0.897 | 0.997 | 0.998 | 0.962 | 0.995 | 0.997 | -0.237 |
| 人口 | 0.897 | 1 | 0.886 | 0.891 | 0.941 | 0.902 | 0.873 | -0.382 |
| 固定资产 | 0.997 | 0.886 | 1 | 0.993 | 0.955 | 0.996 | 0.995 | -0.234 |
| 消费 | 0.998 | 0.891 | 0.993 | 1 | 0.947 | 0.987 | 0.999 | -0.243 |
| 净出口 | 0.962 | 0.941 | 0.955 | 0.947 | 1 | 0.972 | 0.941 | -0.267 |
| 税收 | 0.995 | 0.902 | 0.996 | 0.987 | 0.972 | 1 | 0.987 | -0.239 |
| M2 | 0.997 | 0.873 | 0.995 | 0.999 | 0.941 | 0.987 | 1 | -0.235 |
| 物价指数 | -0.237 | -0.382 | -0.234 | -0.243 | -0.237 | -0.239 | -0.235 | 1 |
接下来用GDP对最初的特征变量进行回归,结果如下:
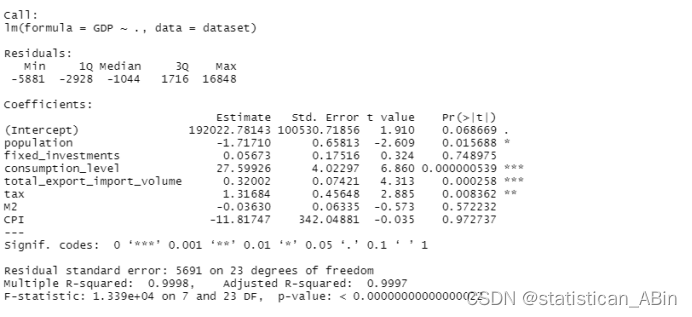
通过观察发现,回归方程的系数的个别因子的p值过大了,导致有些系数没有通过显著性检验。所以接下来需要优化模型即通过t检验来进行逐步回归。
运用向后逐步回归,每次计算AIC值不断剔除一个变量,利用其余变量进行回归;接着剔除再剔除变量直到不能剔除为止,最后能达到更好的回归效果。最终对剔除结果再次进行回归可得,如下:
##逐步回归
fit1 <- step(fit,direction = "backward")
summary(fit1)
fit2 <- lm(GDP~population+consumption_level+total_export_import_volume +tax ,data=dataset)
summary(fit2)
fit2_step <- step(fit2)
summary(fit2_step)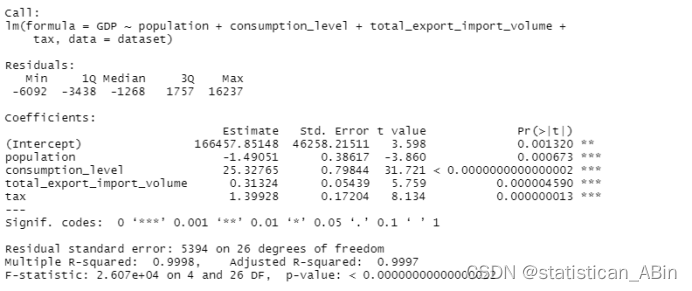
依次剔除了变量fixed_investments,M2,CPI。回归系数的显著性水平有所提高。此时。并且p值均较小,说明回归系数显著。向后删除的逐步回归过程结束后,最终只剩下4个自变量。这6个自变量已经足以用来解释该方程了。....
最终模型为:
![]()
接下来进行模型检验
#异方差检验
library(foreign)
library(zoo)
lmtest::bptest(fit2_step)表 3 异方差检验结果
| Stufentsized Breusch-Pagan test |
| Data: fit2_step |
| BP= 2.8563, df=4 , p_value=0.5822 |
由于p值>0.1可认为该模型不存在异方差性。
###自相关检验 DW
library(lmtest)
dwtest(fit2_step)
#因为dw>0.05所以不拒绝原假设,即认为是不相关的表 4 自相关检验
| Durbin-watson test |
| Data: fit2_step |
| DW= 0.98122, p_value=0.00002874 |
| Alternative hyphothesis: true autocorrelation is greater than 0 |
DW检验的原假设为:误差不相关!
因为dw>0.05所以不拒绝原假设,即认为误差是不相关的。
五、结论与建议
本文对1990—2020年间GDP和各个行业增加值的数据 进行描述性分析和多元线性分析,根据数据可以给出以下建议:在回归模型下,基于逐步回归合理删除变量之后,本文得到对GDP均有影响的4个变量的t检验都非常的显著,它们是对GDP均有影响的4个变量。分别是人口、消费、净出口额、税收。故若希望GDP能稳定持续增长,则需要注重在这几个变量上.....
参考文献
- 戚顺欣,傅格格,张馨予.基于多元回归模型沈阳市GDP影响因素分析[J].商场现代化,2017(09):170-171.DOI:10.14013/j.cnki.scxdh.2017.09.096.
- 郭崇文.我国GDP的影响因素分析[J].商,2016(16):204.
- 卢金凤,彭莉莎.重庆市单位GDP能耗影响因素分析[J].合作经济与科技,2015(23):13-14.DOI:10.13665/j.cnki.hzjjykj.2015.23.005.
创作不易,希望大家多点赞关注!

















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









