







一、研究背景及意义
保险欺诈不仅会造成暂时性的损失、增加公司的运营管理难度,而且对于合法的消费者来说负担了本不属于自身承担的风险,损害了其合法权益。因此,提高对车险欺诈的识别率并据此形成防范对策对提高保险公司的利润与维护消费者利益具有重大的意义。
保险欺诈是指被保险人、受益人或投保人以非法获取保险金为目的,通过编造保险事故提出虚假索赔、夸大索赔金额等手段,意图获得超过合法权益的利益。现阶段我国车险欺诈主要存在以下趋势:一是隐蔽性加强,欺诈人员的作案手法越来越高超,识别难度加大。。。。
二、研究目的和意义
本文通过分析车险欺诈的经济学理论、形式、特点,判断车险欺诈行为的成因,为本文建立反欺诈模型提供理论支撑。并结合我国车险欺诈案件的特点,选取国内车险业 务数据,建立多种种不同的机器学习模型进行实证分析。将机器学习技术与车险反欺诈相结合,将改变保险人传统的低效反欺诈模式,助力我国达到一流的反欺诈水平,具有一定的理论意义。。。。。
三、模型算法的机理
机器学习是计算机针对某一任务,从经验中学习,并且能越做越好的过 程。一般来说,机器学习中所谓的经验,都是以数据的方式存在,计算机程 序从这些数据中进行学习。学习的关键在于模型算法,它可以通过对已有数 据的学习,用于预测未知数据。
机器学习横跨了多个学科,如计算机科学、统计学等,而从事机器学习 的人不仅要有扎实的计算机知识和数学知识,还要对机器学习应用场景下的 业务知识十分了解。
根据学习方式的不同,可以将机器学习划分为几种类型:监督学习、无 监督学习、半监督学习、强化学习。开发机器学习应用时,可以尝试不同的 模型算法对数据进行处理,过程非常灵活,主要的步骤包括:定义问题、数 据采集、数据清洗、特征选择与处理、训练模型、模型评估与调优、模型使 用等。机器学习的算法有很多,常用的如线性回归、逻辑回归、决策树、神经网络、支持向量机等。。。。。
四、实证分析
本次数据分析的主要任务是根据数据集提供了之前客户索赔的车险数据,随后针对数据开发模型帮助公司预测哪些索赔是欺诈行为,即预测用户的车险是否为欺诈行为,从而针对不同的客户,采取不同的营销策略。
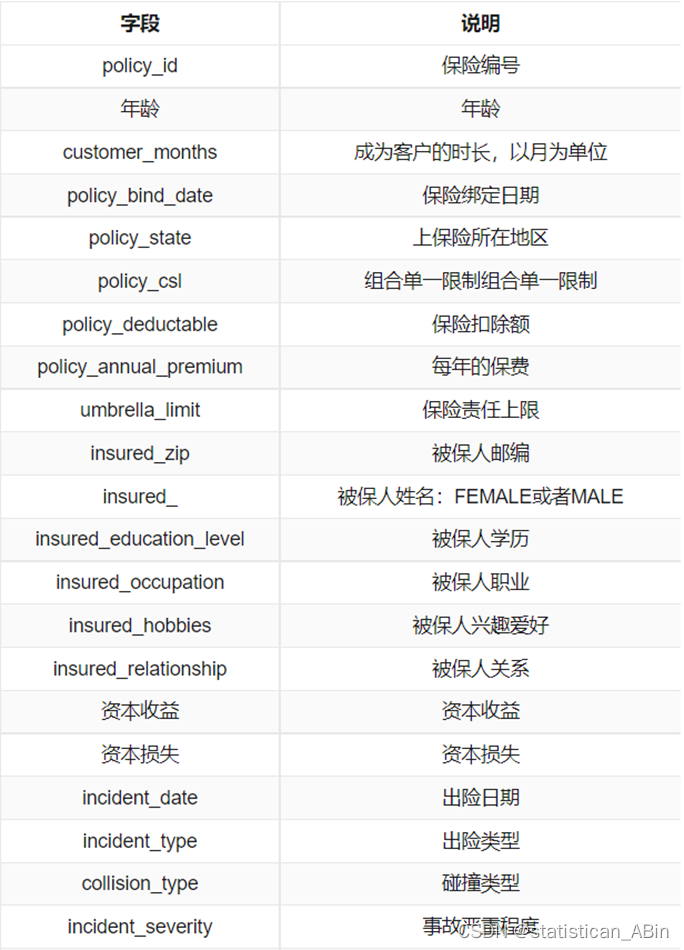
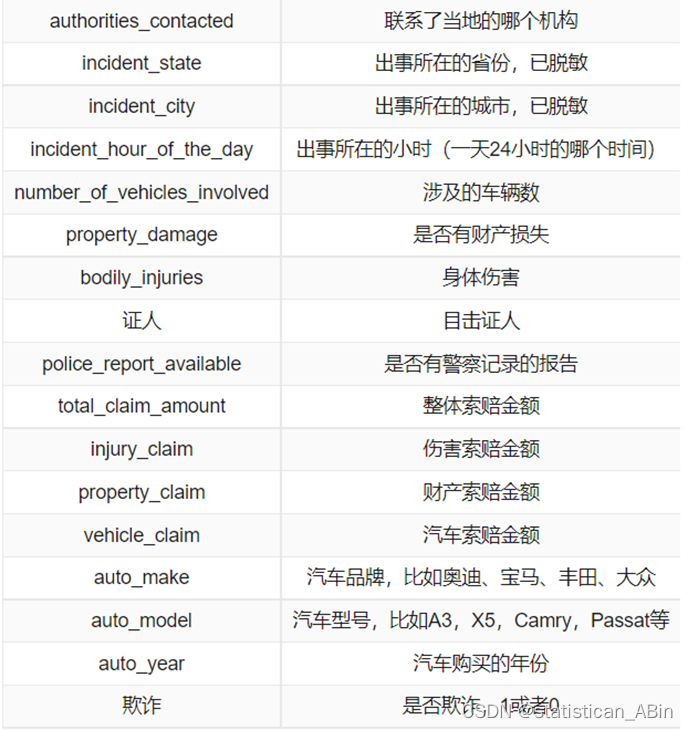
首先查看每个特征数据的具体含义,如下图:
随后是读取训练集和测试集数据文件,然后分别查看数据前5行:
data=pd.read_csv('train.csv')
data2=pd.read_csv('test.csv')
data.head(5)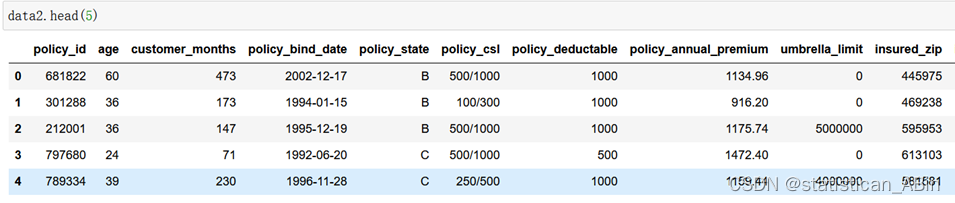
随后推断数据类型,让数据格式更加的规范
###推断数据类型 让数据更规范
data.infer_objects()
data2.infer_objects()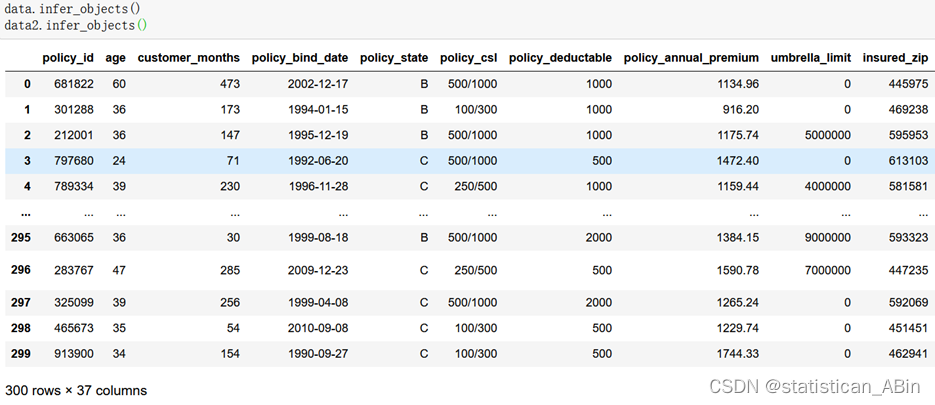
查看数据基础信息
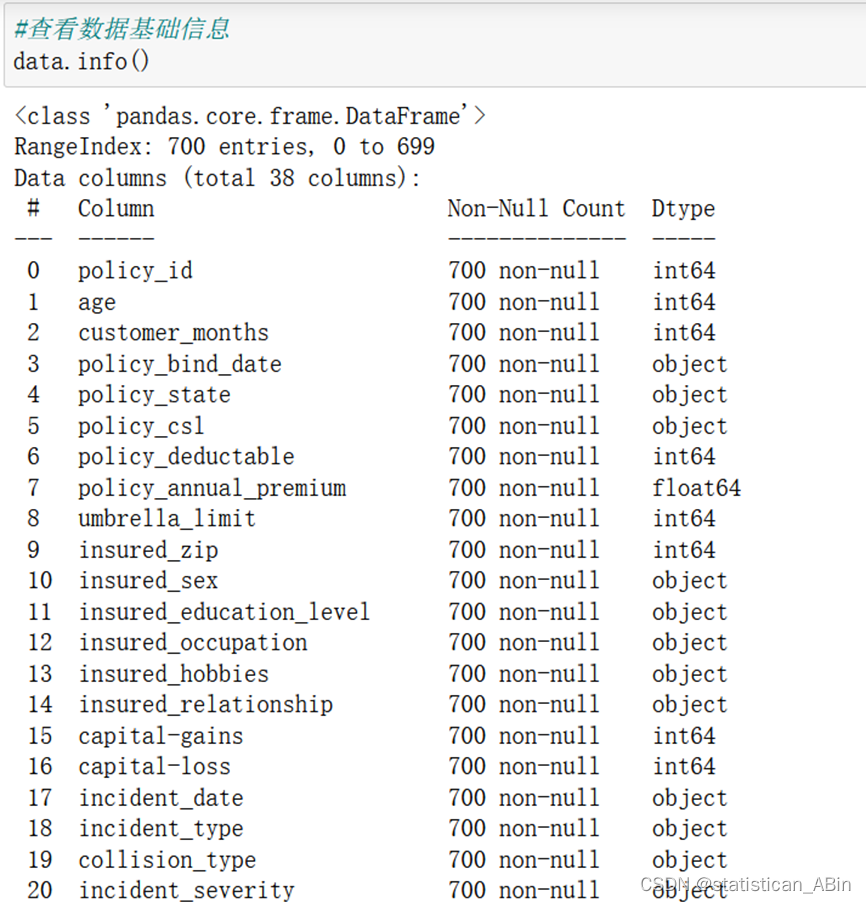
接下来进行数据的预处理,首先观察缺失值,在这里使用missingno函数来可视化缺失值:
import missingno as msno
msno.matrix(data)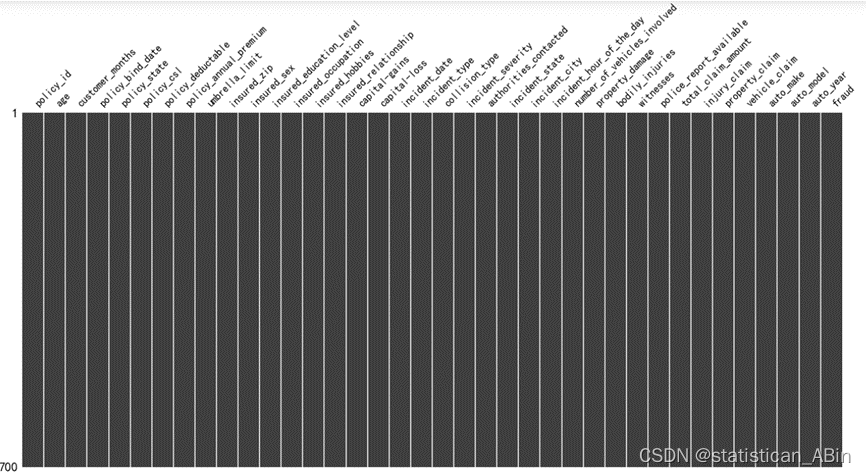 由于所给定的数据集的数据十分规范,故没有缺失值。根据自己对整体数据的判断,删掉一些不需要的特征,但是值得注意的是特征删多了会对模型的泛化能力产生极大的影响。
由于所给定的数据集的数据十分规范,故没有缺失值。根据自己对整体数据的判断,删掉一些不需要的特征,但是值得注意的是特征删多了会对模型的泛化能力产生极大的影响。
首先对训练集取出y,对特征中的非数值型特征可以进行独热编码,随后查看训练集和测试集的形状,注意:有时候训练集和测试集的特征变量独热出来数量可能不一样,要处理一下。
for col in data.columns:
if col not in data2.columns:
data2[col]=0然后需要对数据进一步细化处理,要把数据分为数值型和其他类型来看。
做机器学习当然需要特征越分散越好,因为这样就可以在X上更加有区分度,从而更好的分类。所以那些数据分布很集中的变量可以扔掉。
基于此,基本上完成了数据预处理的工作,现在可视化查看。
columns = data.columns.tolist() # 列表头
dis_cols = 7 #一行几个
dis_rows = len(columns)
plt.figure(figsize=(4 * dis_cols, 4 * dis_rows))
for i in range(len(columns)):
plt.subplot(dis_rows,dis_cols,i+1)
sns.boxplot(data=data[columns[i]], orient="v",width=0.5)
plt.xlabel(columns[i],fontsize = 20)
plt.tight_layout()
#plt.savefig('特征变量箱线图',formate='png',dpi=500)
plt.show()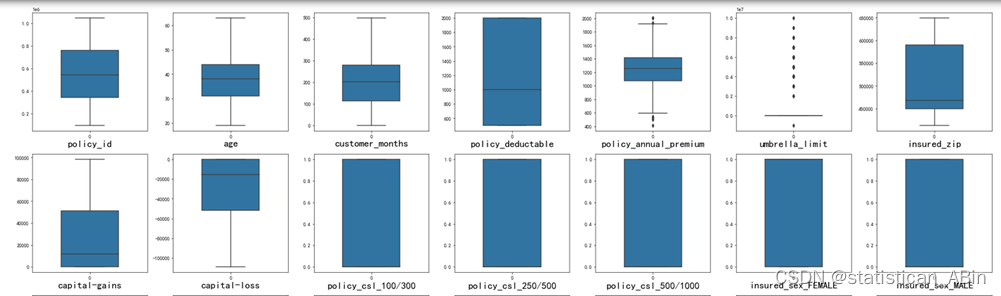
查看训练集和测试集变量的分布,此处为核密度图。
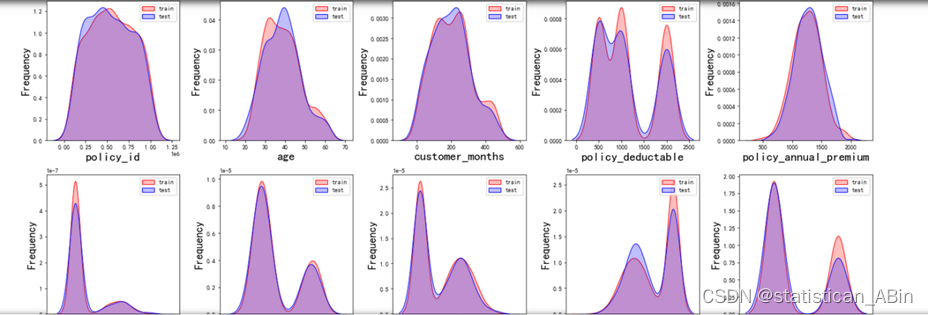
随后查看响应变量的分布。
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号
plt.figure(figsize=(6,2),dpi=128)
plt.subplot(1,3,1)
y.plot.box(title='响应变量箱线图')
plt.subplot(1,3,2)
y.plot.hist(title='响应变量直方图')
plt.subplot(1,3,3)
y.plot.kde(title='响应变量核密度图')
#sns.kdeplot(y, color='Red', shade=True)
#plt.savefig('响应变量.png')
plt.tight_layout()
plt.show()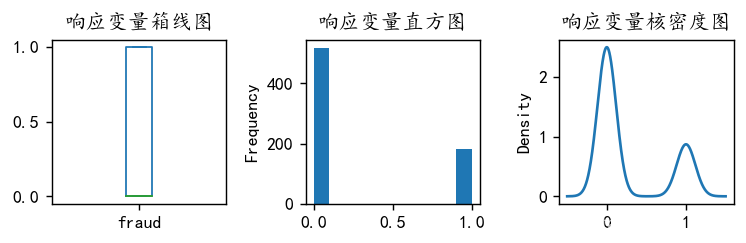
到这里,数据的预处理基本上也就结束了,接下来进行模型的选择和预测。
首先划分训练集和验证集,如下:
from sklearn.model_selection import train_test_split
X_train,X_val,y_train,y_val=train_test_split(data,y,test_size=0.2,random_state=0)然后将数据都标准化,再查看形状。接下来进行模型选择和优化
from sklearn.linear_model import LogisticRegression
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost.sklearn import XGBClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
from sklearn.naive_bayes import BernoulliNB
from sklearn.ensemble import AdaBoostClassifier ##自适应提升Adaboost
from sklearn.neighbors import KNeighborsClassifier#K近邻
model1 = KNeighborsClassifier(n_neighbors=10)
##二项朴素贝叶斯(伯努利)
model2 = BernoulliNB(alpha=1)
#K近邻
model3 = KNeighborsClassifier(n_neighbors=50)
#随机森林
model4= RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=10)
model_list=[model1,model2,model3,model4]
model_name=['K近邻','二项朴素贝叶斯(伯努利)','K近邻','随机森林']# 计算AUC指标,并画图
from sklearn.metrics import plot_roc_curve
plot_roc_curve(model, X_val_s, y_val)
x = np.linspace(0, 1, 100)
plt.plot(x, x, 'k--', linewidth=1)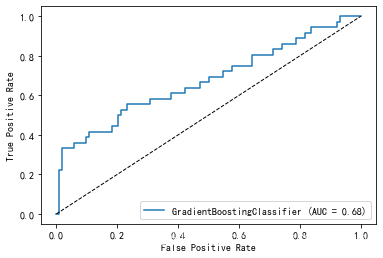
至此,完成了数据分析和预测的全过程。
最终结果显示为:
K近邻方法在验证集的准确率为:0.75
二项朴素贝叶斯(伯努利)方法在验证集的准确率为:0.7428571428571429
K近邻方法在验证集的准确率为:0.7428571428571429
随机森林方法在验证集的准确率为:0.7785714285714286
从上结果我们可以看出,随机森林模型在对保险反欺诈行为预测中的预测结果最好。
五、结论
通过分析机器学习介入的必要性,得出了机器学习的高效率可以扩大案件调查范围,适应不断更迭的车险欺诈形式,也可以减少理赔人员的重复工作。得益于车险行业的大数据,新时代的机器学习技术的发展和十四五规划、车险综合改革等政策,验证了机器学习助力车险反欺诈是可行之路。更重要的是,通过机器学习的预测,我们知道了哪些是重要客户,哪些的不良客户,从而也为我们的营销策略指明了方向,更加有利于企业开展营销和交易。。。。。
参考文献
- 夏淑洁,杨朝阳,周常恩,辛基梁,张佳,杜国栋,李灿东.常见机器学习方法在中医诊断领域的应用述评[J].广州中医药大学,2021,38(04):826-831.DOI:10.13359/j.cnki.gzxbtcm.2021.04.032.
- 尚永杰,茅宇豪,廖宏,胡建林,邹泽庸.基于随机森林的南京市PM_(2.5 )和O_(3) 对减排的响应[J/OL].环境科学:1-18[2022-12-20].DOI:10.13227/j.hjkx.202209163.
创作不易,希望大家多点赞关注评论!!!(类似代码或报告定制可以私信)

















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









