






目录
文本与图片的对齐流程概述
引言
文本图像对齐(Text-Image Alignment)是指将文本描述与相应的图像内容进行匹配和对齐的过程。这一技术在计算机视觉和自然语言处理领域具有广泛的应用,如图像检索、图像生成、多模态理解等。本文将详细介绍文本图像对齐的基本概念、关键技术、应用场景以及未来发展方向。
基本概念
文本图像对齐的核心问题是建立文本描述与图像内容之间的对应关系。具体来说,给定一段文本描述和一张或多张图像,系统需要识别出哪些图像部分与文本中的特定词语或短语相对应。例如,如果文本描述为“一只黑色的猫坐在沙发上”,系统需要能够识别图像中哪些区域表示“黑色的猫”和“沙发”。
关键技术
1.我们需要先进行特征提取。
文本无所谓,但是一个图片的大小是以M计算,所以我们首先要提取图片的特征;
2.映射到同一个嵌入空间
将文本和图像特征映射到同一个嵌入空间是为了使它们能够在同一个空间中进行比较和对齐。这样可以确保文本和图像特征的相似性可以通过计算它们之间的距离来衡量。
3.对齐学习
虽然我们将图像和文本放入了同一个嵌入空间,但是二者并没有把彼此的对应关系。
对齐学习的目的是通过某种机制,使文本和图像特征在共同嵌入空间中尽可能接近。
图示
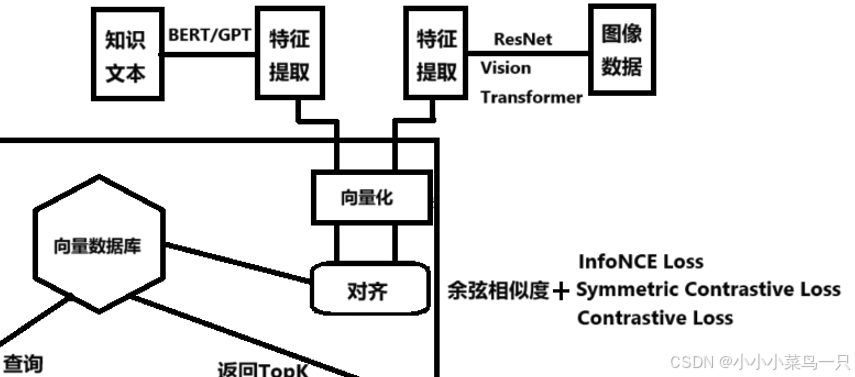
1. 特征提取
首先,分别从文本和图片中提取特征。
文本特征提取示例
文本特征可以通过预训练的语言模型(如BERT、GPT)进行编码
from transformers import BertTokenizer, BertModel import torch # 加载预训练的BERT模型和分词器 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') # 对文本进行编码 inputs = tokenizer("A description of an image", return_tensors="pt") outputs = model(**inputs) text_embedding = outputs.last_hidden_state.mean(dim=1) # 将文本编码为嵌入图片特征提取示例
图片特征可以通过卷积神经网络(如ResNet、Vision Transformer)进行编码。
import torch from torchvision import models, transforms from PIL import Image # 加载预训练的ResNet模型 resnet = models.resnet50(pretrained=True) resnet = torch.nn.Sequential(*list(resnet.children())[:-1]) # 去掉最后一层全连接层 # 定义图像预处理步骤 transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) # 加载和预处理图像 img = Image.open("image.jpg") img_tensor = transform(img).unsqueeze(0) image_embedding = resnet(img_tensor).squeeze() # 得到图片的特征向量
2. 映射到共同嵌入空间
为了实现文本和图片的对齐,需要将它们的特征向量映射到相同的语义空间。在这个空间中,描述相同事物的文本和图片应该具有相似的向量表示。
# 将文本和图片分别映射到共享的嵌入空间 text_projection = torch.nn.Linear(text_embedding.size(1), 512) # 512维度的共同空间 image_projection = torch.nn.Linear(image_embedding.size(0), 512) projected_text_embedding = text_projection(text_embedding) projected_image_embedding = image_projection(image_embedding)
3. 对齐学习
对齐的核心技术是对比学习。对比学习通过最小化相似文本-图片对的距离,最大化不相关对的距离,从而实现对齐。最常用的损失函数是对比损失(Contrastive Loss),其中以CLIP中使用的InfoNCE Loss最为典型。
import torch.nn.functional as F # 计算文本和图片嵌入的余弦相似度 logits_per_text = torch.matmul(projected_text_embedding, projected_image_embedding.T) logits_per_image = torch.matmul(projected_image_embedding, projected_text_embedding.T) # 生成对比损失 labels = torch.arange(len(text_embedding)).to(text_embedding.device) # 假设N对样本,生成标签0, 1, 2, ..., N-1 loss_text = F.cross_entropy(logits_per_text, labels) loss_image = F.cross_entropy(logits_per_image, labels) loss = (loss_text + loss_image) / 2 print(f"Loss: {loss.item()}")常见多模态对齐模型:
CLIP(Contrastive Language-Image Pretraining):OpenAI 提出的 CLIP 是一个典型的通过对比学习实现文本和图片对齐的多模态模型。它使用了海量的图文对数据进行预训练,能够在一个共同的嵌入空间中将图片和文本表示对齐。
BLIP(Bootstrapping Language-Image Pretraining):BLIP 是通过引导图片生成语言描述的方式实现对齐的,并且支持跨模态生成任务。
DALL-E:OpenAI 的 DALL-E 模型能够根据文本生成图像,其背后同样涉及到文本与图片的对齐和生成。

















 6329
6329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









