






 本文介绍了朴素贝叶斯算法的基本概念,包括联合概率和条件概率,以及如何通过贝叶斯公式解决实际问题,如计算垃圾邮件的分类概率。文章还讨论了朴素贝叶斯在文本分类中的优势和局限性,特别提到了拉普拉斯平滑在处理缺失数据时的作用。
本文介绍了朴素贝叶斯算法的基本概念,包括联合概率和条件概率,以及如何通过贝叶斯公式解决实际问题,如计算垃圾邮件的分类概率。文章还讨论了朴素贝叶斯在文本分类中的优势和局限性,特别提到了拉普拉斯平滑在处理缺失数据时的作用。
文章目录
一、朴素贝叶斯算法简介
朴素贝叶斯算法它是一种分类算法,经常被用于文本分类,它的输出结果是某个样本属于某个类别的概率。
1.概念
- 概率定义为一件事情发生的可能性
- 扔出一个硬币,结果头像朝上
- P(X):取值在[0,1]
2. 案例

问题如下:
- 女神喜欢的概率?
- 职业是程序员并且身材匀称的概率?
- 在女神喜欢的条件下,职业是程序员的概率?
- 在女生 喜欢的条件下,职业是程序员、体重超重的概率?
计算结果如下:
P(喜欢) = 4/7
P(程序员, 匀称) = 1/7(联合概率)
P(程序员|喜欢) = 2/4 = 1/2(条件概率)
P(程序员, 超重|喜欢) = 1/4
思考题:在⼩明是产品经理并且体重超重的情况下,如何计算⼩明被⼥神喜欢的概率?
即P(喜欢|产品, 超重) = ?
此时我们需要⽤到朴素⻉叶斯进⾏求解,在讲解⻉叶斯公式之前,⾸先复习⼀下联合概率、条件概率和相互独⽴的概念。
3.联合概率、条件概率与相互独⽴
- 联合概率:包含多个条件,且所有条件同时成⽴的概率
- 记作:P(A,B)
- 条件概率:就是事件A在另外⼀个事件B已经发⽣条件下的发⽣概率
- 记作:P(A|B)
- 相互独⽴:如果P(A, B) = P(A)P(B),则称事件A与事件B相互独⽴。
二、贝叶斯公式
2.1公式介绍
P ( C ∣ W ) = P ( W ∣ C ) P ( C ) P ( W ) P(C|W)=\frac{P(W|C)P(C)}{P(W)} P(C∣W)=P(W)P(W∣C)P(C)
注:W为给定文档的特征值(频数统计,预测文档提供), C为文档类别
2.2 案例计算
上述思考题可以套用贝叶斯公式进行计算:
P(喜欢|产品, 超重) = P(产品, 超重|喜欢)P(喜欢)/P(产品, 超重)
上式中,
- **P(产品, 超重|喜欢)和P(产品, 超重)的结果均为0,导致⽆法计算结果。**这是因为我们的样本量太少了,不具有代表性。
- 本来现实⽣活中,肯定是存在职业是产品经理并且体重超重的⼈的,P(产品,超重)不可能为0;
- ⽽且事件“职业是产品经理”和事件“体重超重”通常被认为是相互独⽴的事件,但是,根据我们有限的7个样本计算“P(产品, 超重) = P(产品)P(超重)”不成⽴。
⽽朴素⻉叶斯可以帮助我们解决这个问题。
- 朴素⻉叶斯,简单理解,就是假定了特征与特征之间相互独⽴的⻉叶斯公式。
- 也就是说,朴素⻉叶斯,之所以朴素,就在于假定了特征与特征相互独⽴。
所以,思考题如果按照朴素⻉叶斯的思路来解决,就可以是
P(产品, 超重) = P(产品) * P(超重) = 2/7 * 3/7 = 6/49
p(产品, 超重|喜欢) = P(产品|喜欢) * P(超重|喜欢) = 1/2 * 1/4 = 1/8
P(喜欢|产品, 超重) = P(产品, 超重|喜欢)P(喜欢)/P(产品, 超重) = 1/8 * 4/7 / 6/49 = 7/12
那么这个公式如果应⽤在⽂章分类的场景当中,我们可以这样看:
公式可以理解为:
P
(
C
∣
F
1
,
F
2
,
.
.
.
)
=
P
(
F
1
,
F
2
,
.
.
.
∣
C
)
P
(
C
)
P
(
F
1
,
F
2
,
.
.
.
)
P(C|F1,F2,...)=\frac{P(F1,F2,...|C)P(C)}{P(F1,F2,...)}
P(C∣F1,F2,...)=P(F1,F2,...)P(F1,F2,...∣C)P(C)
其中C可以是不同类别
公式分为三个部分:
- P©:每个⽂档类别的概率(某⽂档类别数/总⽂档数量)
- P(W│C):给定类别下特征(被预测⽂档中出现的词)的概率
- 计算⽅法:P(F1│C)=Ni/N (训练⽂档中去计算)
- Ni为该F1词在C类别所有⽂档中出现的次数
- N为所属类别C下的⽂档所有词出现的次数和
- 计算⽅法:P(F1│C)=Ni/N (训练⽂档中去计算)
- P(F1,F2,…) 预测⽂档中每个词的概率
如果计算两个类别概率⽐较:
所以我们只要⽐较前⾯的⼤⼩就可以,得出谁的概率⼤
2.3 机器学习两个角度
生成式 vs 判别式建模
判别式(Discriminative): modeling X -> Y directly
生成式(Generative): Modeling assumptions about where data came from

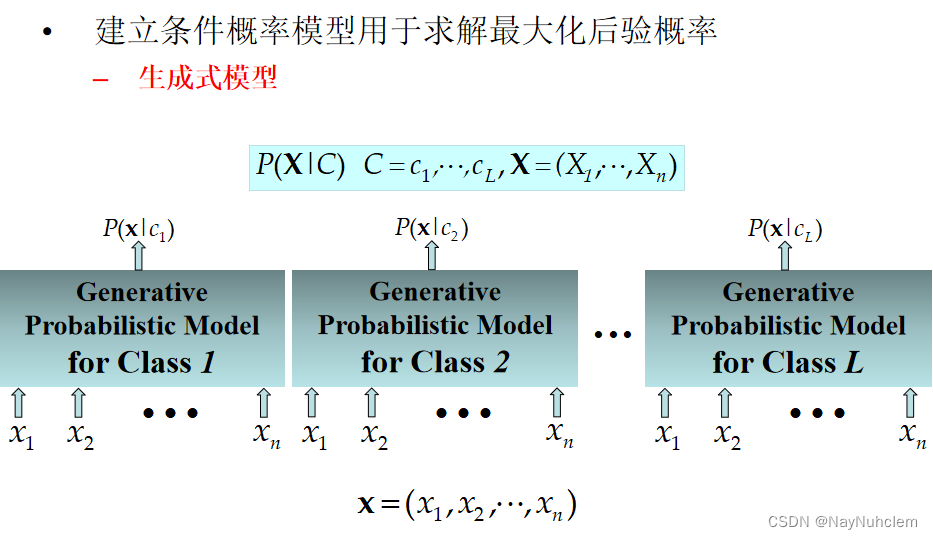
2.4 朴素贝叶斯分类器





2.5 拉普拉斯平滑系数
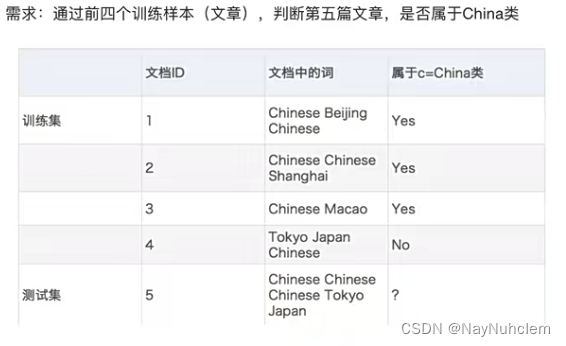
- 计算结果
P(C|Chinese, Chinese, Chinese, Tokyo, Japan) -->
P(Chinese, Chinese, Chinese, Tokyo, Japan|C) * P© / P(Chinese, Chinese, Chinese, Tokyo, Japan)
=
P(Chinese|C)^3 * P(Tokyo|C) * P(Japan|C) * P© / [P(Chinese)^3 * P(Tokyo) * P(Japan)
这个⽂章是需要计算是不是China类,是或者不是最后的分⺟值都相同:
⾸先计算是China类的概率:
P(Chinese|C) = 5/8
P(Tokyo|C) = 0/8
P(Japan|C) = 0/8
接着计算不是China类的概率:
P(Chinese|C`) = 1/3
P(Tokyo|C`) = 1/3
P(Japan|C`) = 1/3
- 问题:**从上⾯的例⼦我们得到P(Tokyo|C)和P(Japan|C)都为0,这是不合理的,**如果词频列表⾥⾯有很多出现次数都为0,很可能计算结果都为0.
- 解决⽅法:P(F1∣C) =
(
N
i
+
α
N
+
α
∗
m
)
(\frac{Ni+\alpha }{N+\alpha*m } )
(N+α∗mNi+α) (拉普拉斯平滑系数)
- α为指定的系数,⼀般为1;
- m为训练⽂档中统计出的特征词个数
这个⽂章是需要计算是不是China类:
⾸先计算是China类的概率: 0.0003
P(Chinese|C) = 5/8 --> 6/14
P(Tokyo|C) = 0/8 --> 1/14
P(Japan|C) = 0/8 --> 1/14
接着计算不是China类的概率: 0.0001
P(Chinese|C) = 1/3 -->(经过拉普拉斯平滑系数处理) 2/9
P(Tokyo|C) = 1/3 --> 2/9
P(Japan|C`) = 1/3 --> 2/9
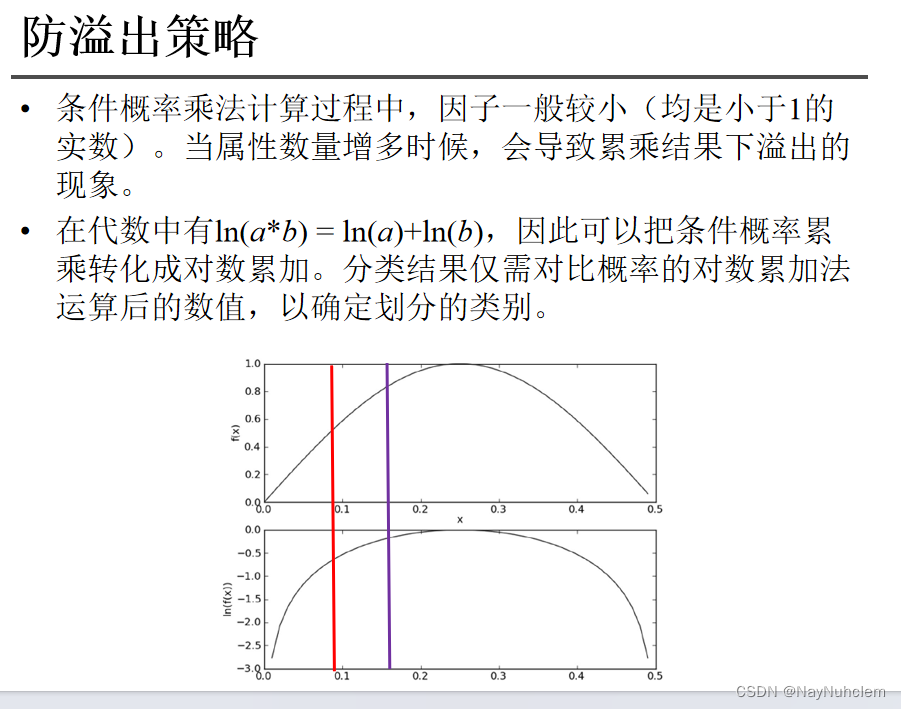
2.6 防溢出策略
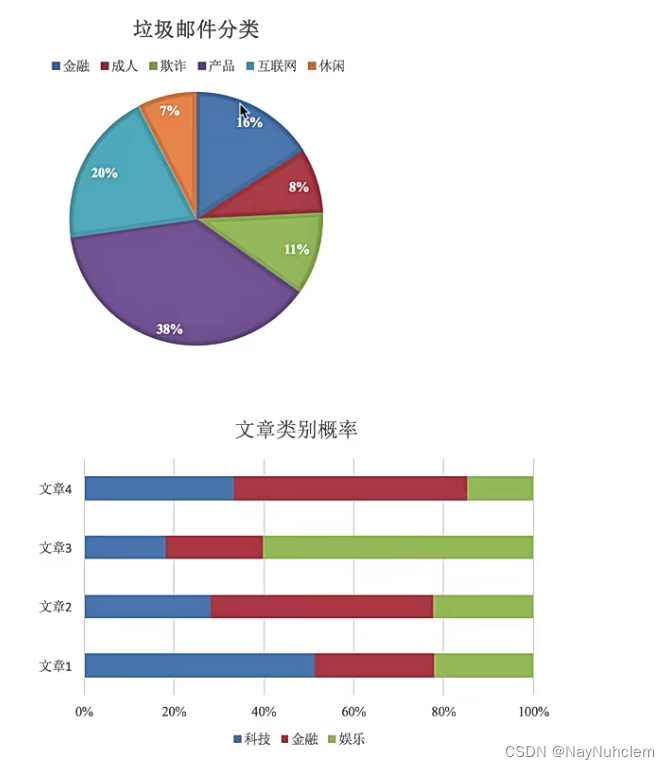
三、朴素贝叶斯实例——垃圾邮件的分类
数据集说明:非垃圾邮件ham和垃圾邮件spam各25封,测试邮件5封,其中把spam中的1、2和ham中的22、23、24拿出来当测试集。
测试集:
导包:
import os
import re
import string
import math
import numpy as np
数据预处理:
def get_filtered_str(category):
email_list = []
translator = re.compile('[%s]' % re.escape(string.punctuation))
for curDir, dirs, files in os.walk(f'./email/{category}'):
for file in files:
file_name = os.path.join(curDir, file)
with open(file_name, 'r', encoding='utf-8') as f:
txt_str = f.read()
# 全部小写
txt_str = txt_str.lower()
# 过滤掉所有符号
txt_str = translator.sub(' ', txt_str)
# 过滤掉全部数字
txt_str = replace_num(txt_str)
# 把全体的邮件文本 根据换行符把string划分成列表
txt_str_list = txt_str.splitlines()
# 把获取的全体单词句子列表转成字符串
txt_str = ''.join(txt_str_list)
# print(txt_str)
email_list.append(txt_str)
return email_list
数据处理阶段:
def get_dict_spam_dict_w(spam_email_list):
'''
:param email_list: 每个邮件过滤后形成字符串,存入email_list
:param all_email_words: 列表。把所有的邮件内容,分词。一个邮件的词 是它的一个列表元素
:return:
'''
all_email_words = []
# 用set集合去重
word_set = set()
for email_str in spam_email_list:
# 把每个邮件的文本 变成单词
email_words = email_str.split(' ')
# 把每个邮件去重后的列表 存入列表
all_email_words.append(email_words)
for word in email_words:
if(word!=''):
word_set.add(word)
# 计算每个垃圾词出现的次数
word_dict = {}
for word in word_set:
# 创建字典元素 并让它的值为1
word_dict[word] = 0
# print(f'word={word}')
# 遍历每个邮件,看文本里面是否有该单词,匹配方法不能用正则.邮件里面也必须是分词去重后的!!! 否则 比如出现re是特征, 那么remind 也会被匹配成re
for email_words in all_email_words:
for email_word in email_words:
# print(f'spam_email={email_word}')
# 把从set中取出的word 和 每个email分词后的word对比看是否相等
if(word==email_word):
word_dict[word] += 1
# 找到一个就行了
break
# 计算垃圾词的概率
# spam_len = len(os.listdir(f'./email/spam'))
# print(f'spam_len={spam_len}')
# for word in word_dict:
# word_dict[word] = word_dict[word] / spam_len
return word_dict
def get_dict_ham_dict_w(spam_email_list,ham_email_list):
'''
:param email_list: 每个邮件过滤后形成字符串,存入email_list
:param all_email_words: 列表。把所有的邮件内容,分词。一个邮件的词 是它的一个列表元素
:return:
'''
all_ham_email_words = []
# 用set集合去重 得到垃圾邮件的特征w
word_set = set()
#获取垃圾邮件特征
for email_str in spam_email_list:
# 把每个邮件的文本 变成单词
email_words = email_str.split(' ')
for word in email_words:
if (word != ''):
word_set.add(word)
for ham_email_str in ham_email_list:
# 把每个邮件的文本 变成单词
ham_email_words = ham_email_str.split(' ')
# print(f'ham_email_words={ham_email_words}')
# 把每个邮件分割成单词的 的列表 存入列表
all_ham_email_words.append(ham_email_words)
# print(f'all_ham_email_words={all_ham_email_words}')
# 计算每个垃圾词出现的次数
word_dict = {}
for word in word_set:
# 创建字典元素 并让它的值为1
word_dict[word] = 0
# print(f'word={word}')
# 遍历每个邮件,看文本里面是否有该单词,匹配方法不能用正则.邮件里面也必须是分词去重后的!!! 否则 比如出现re是特征, 那么remind 也会被匹配成re
for email_words in all_ham_email_words:
# print(f'ham_email_words={email_words}')
for email_word in email_words:
# 把从set中取出的word 和 每个email分词后的word对比看是否相等
# print(f'email_word={email_word}')
if(word==email_word):
word_dict[word] += 1
# 找到一个就行了
break
return word_dict
# 获取测试邮件中出现的 垃圾邮件特征
def get_X_c1(spam_w_dict,file_name):
# 获取测试邮件
# file_name = './email/spam/25.txt'
# 过滤文本
translator = re.compile('[%s]' % re.escape(string.punctuation))
with open(file_name, 'r', encoding='utf-8') as f:
txt_str = f.read()
# 全部小写
txt_str = txt_str.lower()
# 过滤掉所有符号
txt_str = translator.sub(' ', txt_str)
# 过滤掉全部数字
txt_str = replace_num(txt_str)
# 把全体的邮件文本 根据换行符把string划分成列表
txt_str_list = txt_str.splitlines()
# 把获取的全体单词句子列表转成字符串
txt_str = ''.join(txt_str_list)
# 把句子分成词
email_words = txt_str.split(' ')
# 去重
x_set = set()
for word in email_words:
if word!='':
x_set.add(word)
# print(f'\ntest_x_set={x_set}')
spam_len = len(os.listdir(f'./email/spam'))
# 判断测试邮件的词有哪些是垃圾邮件的特征
spam_X_num = []
for xi in x_set:
for wi in spam_w_dict:
if xi == wi:
spam_X_num.append(spam_w_dict[wi])
# print(f'\nspam_X_num={spam_X_num}')
w_appear_sum_num = 1
for num in spam_X_num:
w_appear_sum_num += num
# print(f'\nham_w_appear_sum_num={w_appear_sum_num}')
# 求概率
w_c1_p = w_appear_sum_num / (spam_len + 2)
return w_c1_p
# 获取测试邮件中出现的非垃圾邮件特征
def get_X_c2(ham_w_dict,file_name):
# 过滤文本
translator = re.compile('[%s]' % re.escape(string.punctuation))
with open(file_name, 'r', encoding='utf-8') as f:
txt_str = f.read()
# 全部小写
txt_str = txt_str.lower()
# 过滤掉所有符号
txt_str = translator.sub(' ', txt_str)
# 过滤掉全部数字
txt_str = replace_num(txt_str)
# 把全体的邮件文本 根据换行符把string划分成列表
txt_str_list = txt_str.splitlines()
# 把获取的全体单词句子列表转成字符串
txt_str = ''.join(txt_str_list)
# 把句子分成词
email_words = txt_str.split(' ')
# 去重
x_set = set()
for word in email_words:
if word!='':
x_set.add(word)
# print(f'\ntest_x_set={x_set}')
# 判断测试邮件的词有哪些是垃圾邮件的特征
ham_X_num = []
for xi in x_set:
for wi in ham_w_dict:
if xi == wi:
ham_X_num.append(ham_w_dict[wi])
# print(f'\nham_X_num={ham_X_num}')
# 先求分子 所有词出现的总和
ham_len = len(os.listdir(f'./email/ham'))
w_appear_sum_num = 1
for num in ham_X_num:
w_appear_sum_num += num
# print(f'\nspam_w_appear_sum_num={w_appear_sum_num}')
# 求概率
w_c2_p = w_appear_sum_num / (ham_len+2)
return w_c2_p
测试阶段:
def email_test(spam_w_dict,ham_w_dict):
for curDir, dirs, files in os.walk(f'./email/test'):
for file in files:
file_name = os.path.join(curDir, file)
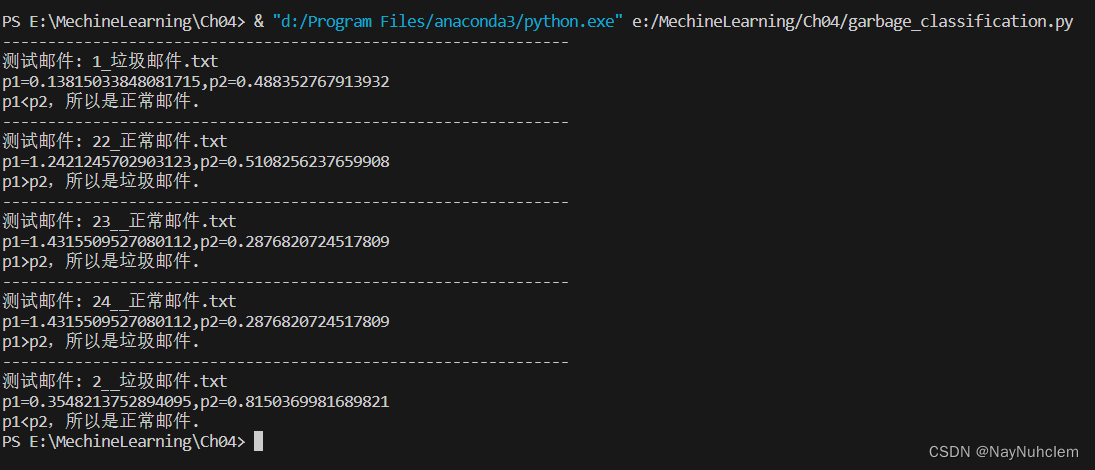
print('---------------------------------------------------------------')
print(f'测试邮件: {file}')
# 获取条件概率 p(X|c1)
p_X_c1 = get_X_c1(spam_w_dict,file_name)
# 获取条件概率 p(X|c2)
p_X_c2 = get_X_c2(ham_w_dict,file_name)
# print(f'\nX_c1={p_X_c1}')
# print(f'\nX_c2={p_X_c2}')
# #注意:Log之后全部变为负数
A = np.log(p_X_c1) + np.log(1 / 2)
B = np.log(p_X_c2) + np.log(1 / 2)
# 除法会出现问题,-1 / 负分母 结果 < -2/同一个分母
print(f'p1={A},p2={B}')
# 因为分母一致,所以只比较 分子即可
if A > B:
print('p1>p2,所以是垃圾邮件.')
if A <= B:
print('p1<p2,所以是正常邮件.')
if __name__=='__main__':
spam_email_list = get_filtered_str('spam')
ham_email_list = get_filtered_str('ham')
spam_w_dict = get_dict_spam_dict_w(spam_email_list)
ham_w_dict = get_dict_ham_dict_w(spam_email_list,ham_email_list)
# print(f'\n从垃圾邮件中提取的特征及每个特征出现的邮件数:')
# print(f'spam_w_dict={spam_w_dict}')
# print(f'\n普通邮件中垃圾邮件特征出现的邮件数为:')
# print(f'ham_w_dict={ham_w_dict}')
email_test(spam_w_dict, ham_w_dict)
上述代码在运行时可能会报错:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x92 in position 66: invalid start byte

解决方法:
出现这种问题绝大部分情况是因为文件不是 UTF8 编码的(例如,可能是 GBK 编码的),而系统默认采用 UTF8 解码。解决方法是改为对应的解码方式。在代码中我们把utf-8改为gbk就可以了。

代码运行测试结果:
朴素⻉叶斯优缺点
- 优点:
- 朴素⻉叶斯模型发源于古典数学理论,有稳定的分类效率
- 对缺失数据不太敏感,算法也⽐较简单,常⽤于⽂本分类
- 分类准确度⾼,速度快
- 缺点:
- 由于使⽤了样本属性独⽴性的假设,所以如果特征属性有关联时其效果不好
- 需要计算先验概率,⽽先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳;















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









