






介绍
随着ChatGPT的横空出世,国内互联网大厂、创业公司纷纷加了AIGC赛道,不断推出各种大模型,而这些大模型由于规模庞大、结构复杂,往往包含了数十亿至数千亿的参数。这些模型在训练阶段,一般需要使用高效能的GPU集群训练数十天时间,在推理阶段,一般也需要高效能的GPU集群才能支撑一定量级的并发请求且实时返回。目前也有不少公司推出了规模相对较小但效果仍有一定优势的大模型,可以在消费级的单卡GPU上进行推理、甚至训练。本文尝试在普通的Macbook Pro上部署大模型开源方案,实现自然语言问答和对话等功能,虽然性能和效果一般,但可以在不借助深度学习专用GPU服务器的前提下,体验一下目前AIGC的能力。
配置
所使用的Macbook Pro配置如下:
- 机型,Macbook Pro(14英寸,2021年);
- 芯片,Apple M1 Pro;
- 内存,16G;
- 系统,macOS Monterey,12.6.2。
前置条件
首先默认本地已安装macOS的软件包管理工具[Homebrew]
Git
安装[Git]:
brew install git
由于使用git命令下载的模型文件较大,因此还需要安装[Git Large File Storage]:
brew install git-lfs
Conda
[Conda]是一个依赖和环境管理工具,支持的语言包括Python、R、Ruby、Lua、Scala、Java、JavaScript、C/C++、Fortran等,且目前在Python语言生态中得到广泛的应用,通过其可以创建、管理多个相互独立、隔离的Python环境,并在环境中安装、管理Python依赖,而[MiniConda]是Conda的免费、最小可用版本。下载并安装MiniConda:
wget [repo.anaconda.com/miniconda/M…]bash ./Miniconda3-latest-MacOSX-arm64.sh -b -p $HOME/miniconda source ~/miniconda/bin/activate
ChatGLM-6B
介绍
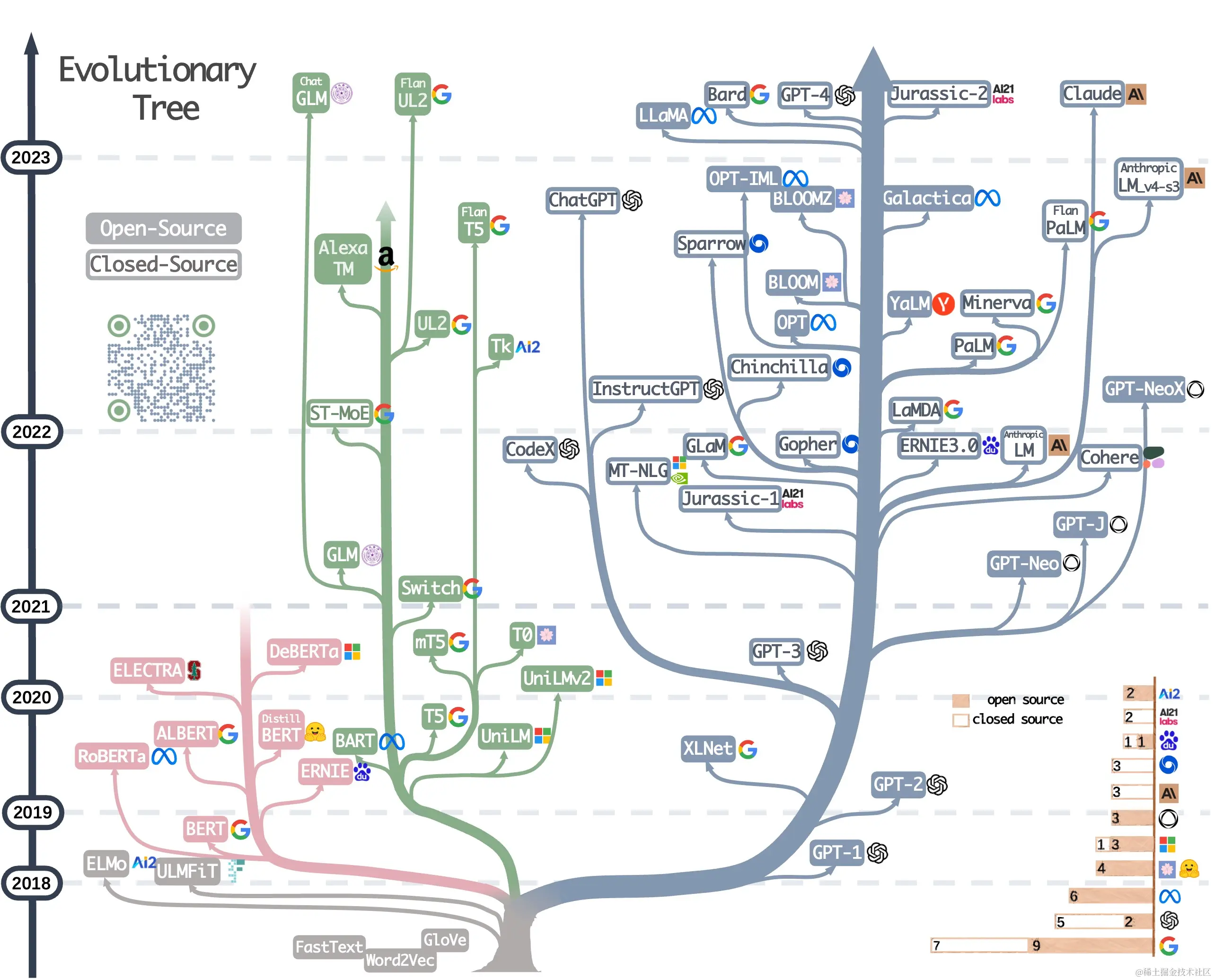
论文[《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》])通过图1所示的树状图详细列举了自2018年以来自然语言大模型(LLM)这一领域的发展路线和相应的各大模型,其中一部分是在Transformer出现之前、不基于Transformer的大模型,例如AI2的ELMo,另一大部分是在Transfomer出现之后、基于Transformer的大模型,其又分为三个发展路线:
- 仅基于Transformer解码器的大模型(图中的蓝色部分),例如,OpenAI的GPT系列、Meta的LLaMa、Google的PaLM等;
- 仅基于Transformer编码器的大模型(图中的粉丝部分),例如,Google的BERT、Meta的RoBERTa等;
- 同时基于Transformer编码器和解码器的大模型(图中的绿色部分),例如,Meta的BART、Google的T5、清华大学的GLM/ChatGLM等。
这里选择ChatGLM-6B进行本地部署,其[官网]上的介绍如下:ChatGLM-6B是一个开源的、支持中英双语问答的对话语言模型,基于[General Language Model(GLM])架构,具有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。ChatGLM-6B使用了和[ChatGLM])相同的技术,针对中文问答和对话进行了优化。经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。而ChatGLM-6B-INT4是ChatGLM-6B量化后的模型权重。具体的,ChatGLM-6B-INT4对ChatGLM-6B中的28个GLM Block进行了INT4量化,没有对Embedding和LM Head进行量化。量化后的模型理论上6G显存(使用CPU即内存)即可推理,具有在嵌入式设备(如树莓派)上运行的可能。
部署
创建并激活环境:
conda create --name chatglm python=3.9 conda activate chatglm
下载ChatGLM-6B源码:
cd ~/workspace/ git clone [github.com/THUDM/ChatG…]
安装依赖:
cd ~/workspace/ChatGLM-6B pip install -r requirements.txt
下载ChatGLM-6B INT4量化的模型权重ChatGLM-6B-INT4:
cd ~/workspace/models/ git lfs install git clone [huggingface.co/THUDM/chatg…
Macbook直接加载量化后的模型可能出现提示——“clang: error: unsupported option ‘-fopenmp’”,还需[单独安装OpenMP依赖],此时会安装下面几个文件:/usr/local/lib/libomp.dylib, /usr/local/include/ompt.h, /usr/local/include/omp.h, /usr/local/include/omp-tools.h:
curl -O [mac.r-project.org/openmp/open…] sudo tar fvxz openmp-14.0.6-darwin20-Release.tar.gz -C /
执行以下Python代码,从本地地址加载模型并进行推理,对“你好”和“如何读一本书”进行回答:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("/Users/xxx/workspace/models/chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("/Users/xxx/workspace/models/chatglm-6b-int4", trust_remote_code=True).float()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "如何读一本书", history=history)
print(response)
执行结果如图2所示,推理耗时约6分钟,比较慢。

修改ChatGLM-6B源码目录下的web_demo.py文件的7、8两行,使用本地已下载的INT4量化的模型权重ChatGLM-6B-INT4,并且不使用半精度(Mac不支持)和CUDA(无GPU):
tokenizer = AutoTokenizer.from_pretrained("/Users/xxx/workspace/models/chatglm-6b-int4", trust_remote_code=True) #tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/Users/xxx/workspace/models/chatglm-6b-int4", trust_remote_code=True).float() #model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
启动web_demo.py:
python web_demo.py
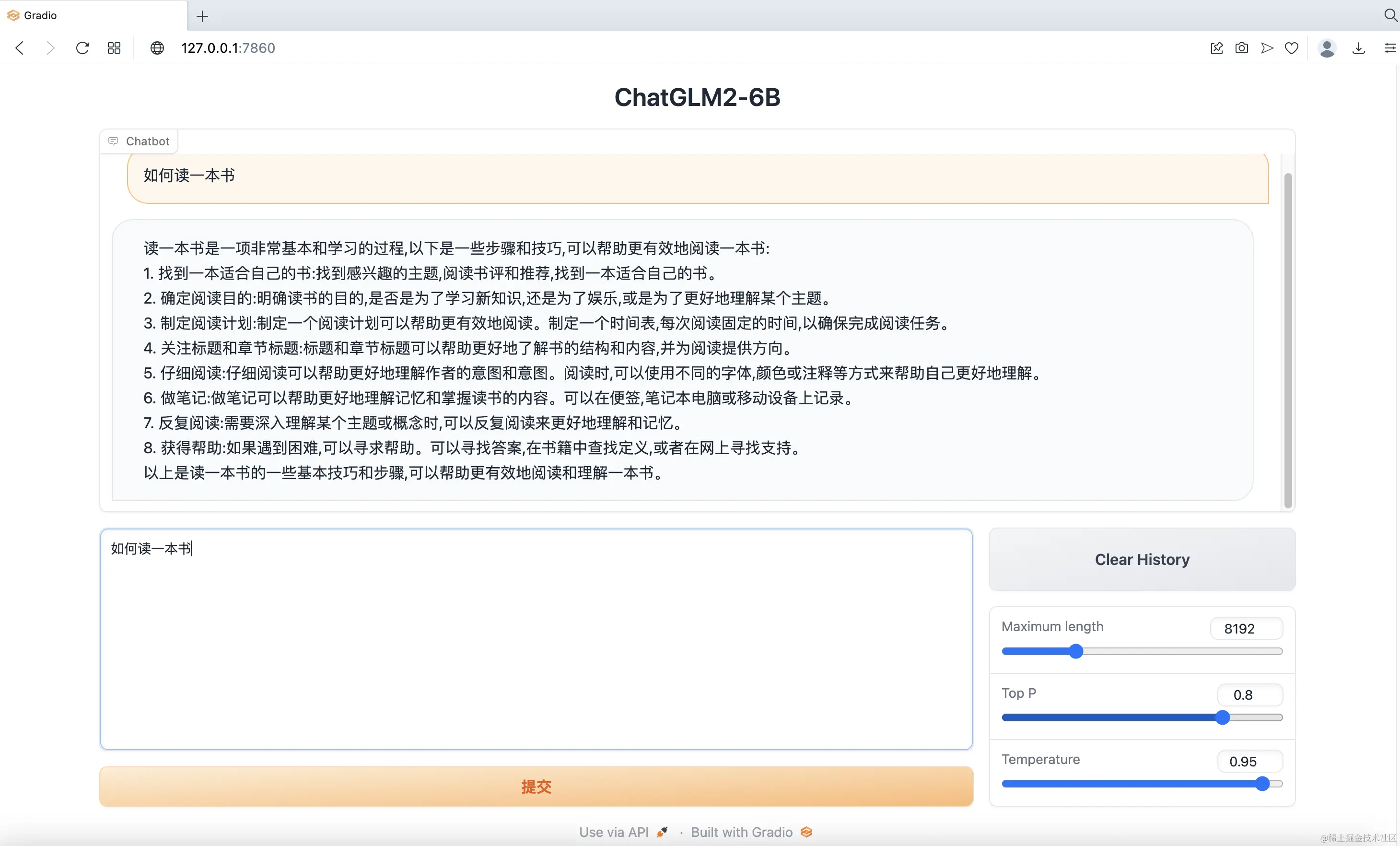
可在网页中提问,由模型进行推理,如图3所示。 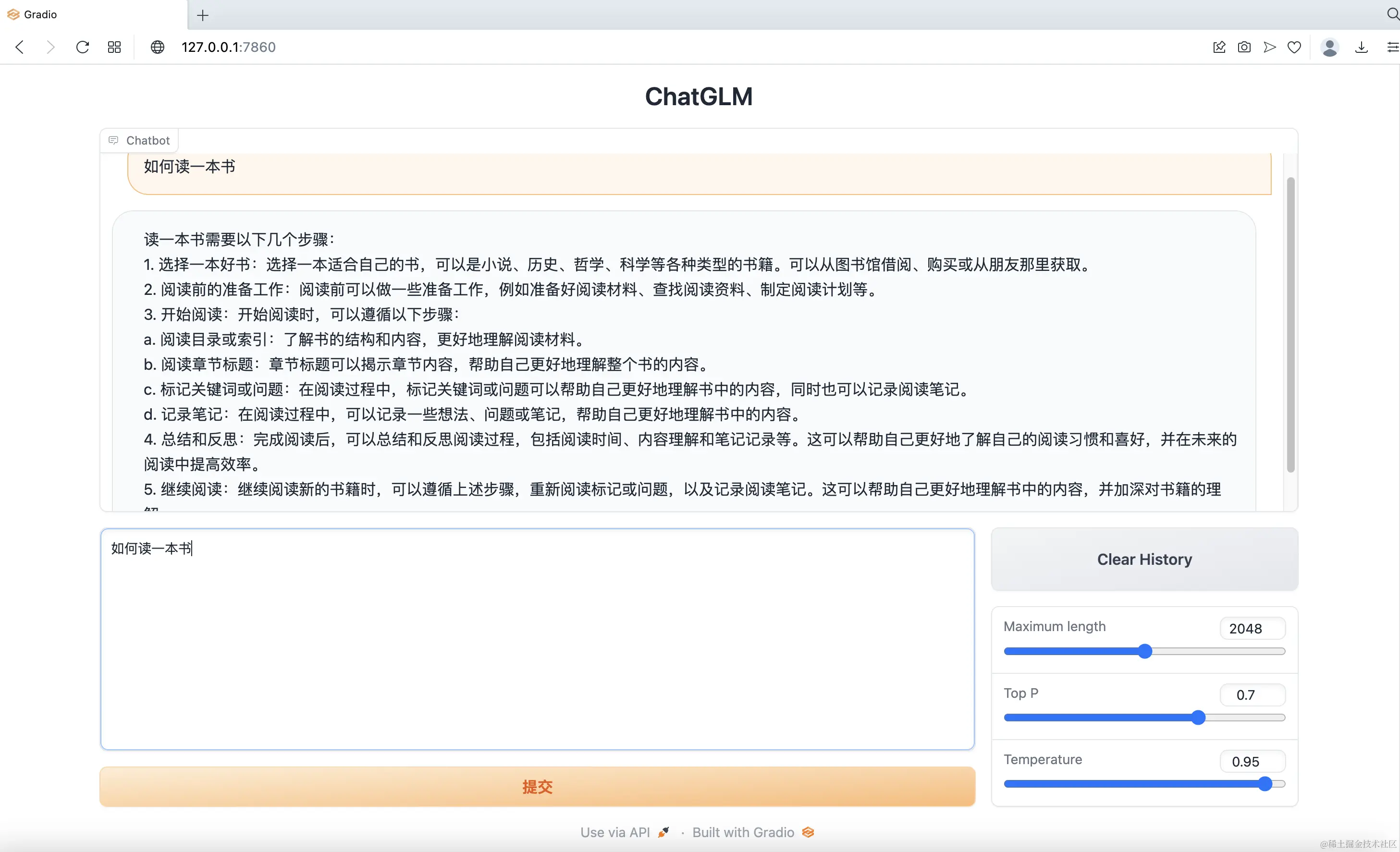
ChatGLM2-6B
介绍
部署
以下步骤和ChatGLM-6基本相同。首先创建并激活环境:
conda create --name chatglm2 python=3.9 conda activate chatglm2
下载ChatGLM2-6B源码:
安装依赖:
cd ~/workspace/ChatGLM2-6B pip install -r requirements.txt
下载ChatGLM2-6B INT4量化的模型权重ChatGLM2-6B-INT4:
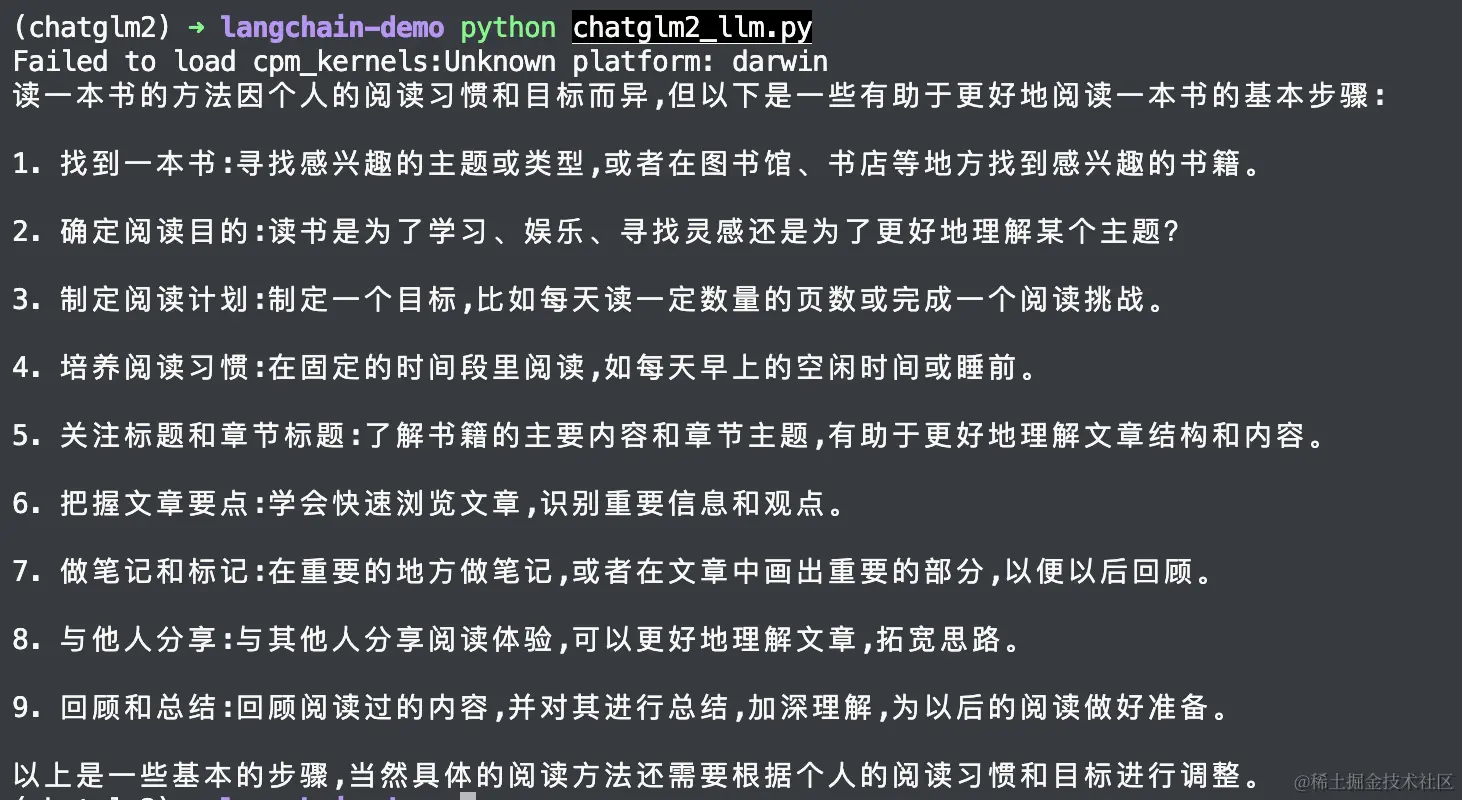
执行以下Python代码,从本地地址加载模型并进行推理,对“你好”和“如何读一本书”进行回答,代码与ChatGLM部分基本相同,仅更改模型地址:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("/Users/xxx/workspace/models/chatglm2-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("/Users/xxx/workspace/models/chatglm2-6b-int4", trust_remote_code=True).float()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "如何读一本书", history=history)
print(response)
执行结果如图4所示。

对于ChatGLM2-6B源码目录下的web_demo.py的修改和启动和ChatGLM-6B部分类似,修改其中的6、7两行:
tokenizer = AutoTokenizer.from_pretrained("/Users/xxx/workspace/models/chatglm2-6b-int4", trust_remote_code=True) #tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/Users/xxx/workspace/models/chatglm2-6b-int4", trust_remote_code=True).float() #model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
启动web_demo.py:
python web_demo.py
启动后如图5所示。
LangChain
介绍
[LangChain]是一个面向大语言模型的应用开发框架,如果将大语言模型比作人的大脑,那么可以将LangChain可以比作人的五官和四肢,它可以将外部数据源、工具和大语言模型连接在一起,既可以补充大语言模型的输入,也可以承接大语言模型的输出。LangChain包含以下核心组件:
- Model,表示大语言模型,
- Prompt,表示提示;
- Tool,表示工具;
- Chain,表示将Model、Tool等组件串联在一起,甚至可以递归地将其他Chain串联在一起;
- Agent,相对于Chain已固定执行链路,Agent能够实现动态的执行链路。
部署
安装依赖
在chatglm2环境下继续安装LangChain依赖:
pip install langchain
注意,以上命令只是安装LangChain依赖的最小集,因为LangChain集成了多种模型、存储等工具,而这些工具的依赖并不会被安装,所以后续进一步使用这些工具时可能会报缺少特定依赖的错误,可以使用pip进行安装,也可以这里直接使用“pip install’langchain[all]'”安装LangChain的所有依赖,但比较耗时。
Model
继承LangChain的LLM,接入ChatGLM2,实现对话和问答,代码文件chatglm_llm.py如下所示:
from langchain.llms.base import LLM
from langchain.llms.utils import enforce_stop_tokens
from transformers import AutoTokenizer, AutoModel
from typing import List, Optional
class ChatGLM2(LLM):
max_token: int = 4096
temperature: float = 0.8
top_p = 0.9
tokenizer: object = None
model: object = None
history = []
def __init__(self):
super().__init__()
@property
def _llm_type(self) -> str:
return "ChatGLM2"
# 定义load_model方法,进行模型的加载
def load_model(self, model_path = None):
self.tokenizer = AutoTokenizer.from_pretrained(model_path,trust_remote_code=True)
self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True).float()
# 实现_call方法,进行模型的推理
def _call(self,prompt:str, stop: Optional[List[str]] = None) -> str:
response, _ = self.model.chat(
self.tokenizer,
prompt,
history=self.history,
max_length=self.max_token,
temperature=self.temperature,
top_p=self.top_p)
if stop is not None:
response = enforce_stop_tokens(response, stop)
self.history = self.history + [[None, response]]
return response
if __name__ == "__main__":
llm=ChatGLM2()
llm.load_model("/Users/xxx/workspace/models/chatglm2-6b-int4")
print(llm._call("如何读一本书"))
chatglm2_llm.py的执行结果如图6所示。
Chain
LLMChain
LLMChain是最基础的Chain,其引入一个提示模板将问题转化为提示输入模型,并输出模型的回答。

其实现原理如图7所示,包含三步:
- 输入问题;
- 拼接提示,根据提示模板将问题转化为提示;
- 模型推理,输出答案。
代码文件chain_demo.py如下所示:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from chatglm2_llm import ChatGLM2
if __name__ == "__main__":
# 定义模型
llm = ChatGLM2()
# 加载模型
llm.load_model("/Users/xxx/workspace/models/chatglm2-6b-int4")
# 定义提示模板
prompt = PromptTemplate(input_variables=["question"], template="""
简洁和专业的来回答用户的问题。
如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}""",)
# 定义chain
chain = LLMChain(llm=llm, prompt=prompt, verbose=True)
# 执行chain
print(chain.run("如何读一本书"))
其中模型采用自定义模型,接入本地部署的ChatGLM2。chain_demo.py运行结果如图8所示。

RetrievalQA
除了基础的链接提示和模型的LLMChain外,LangChain还提供了其他多种Chain,例如实现本地知识库功能的RetrievalQA和自动生成SQL并执行的SQLDatabaseChain。
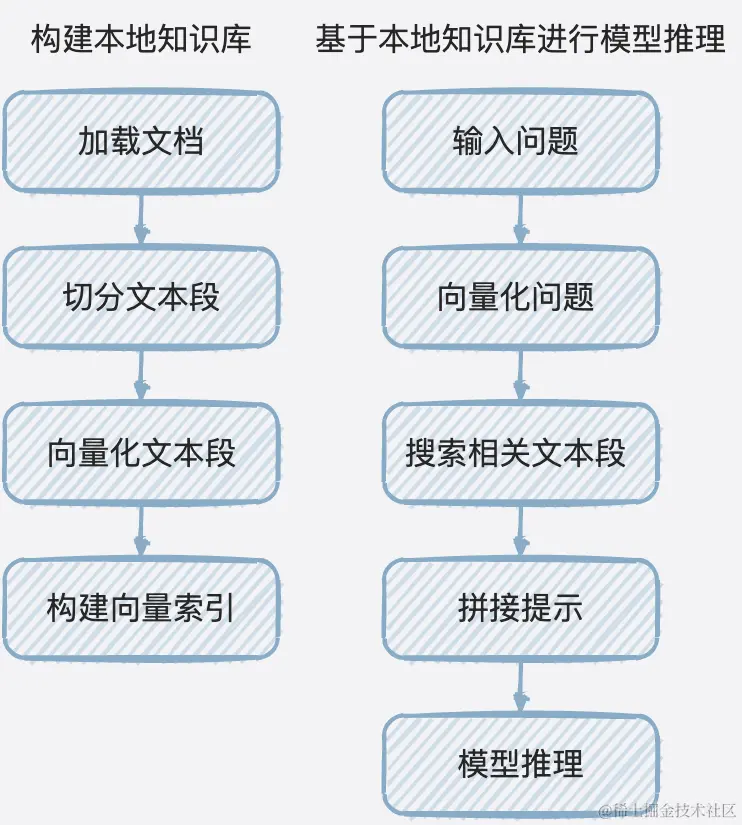
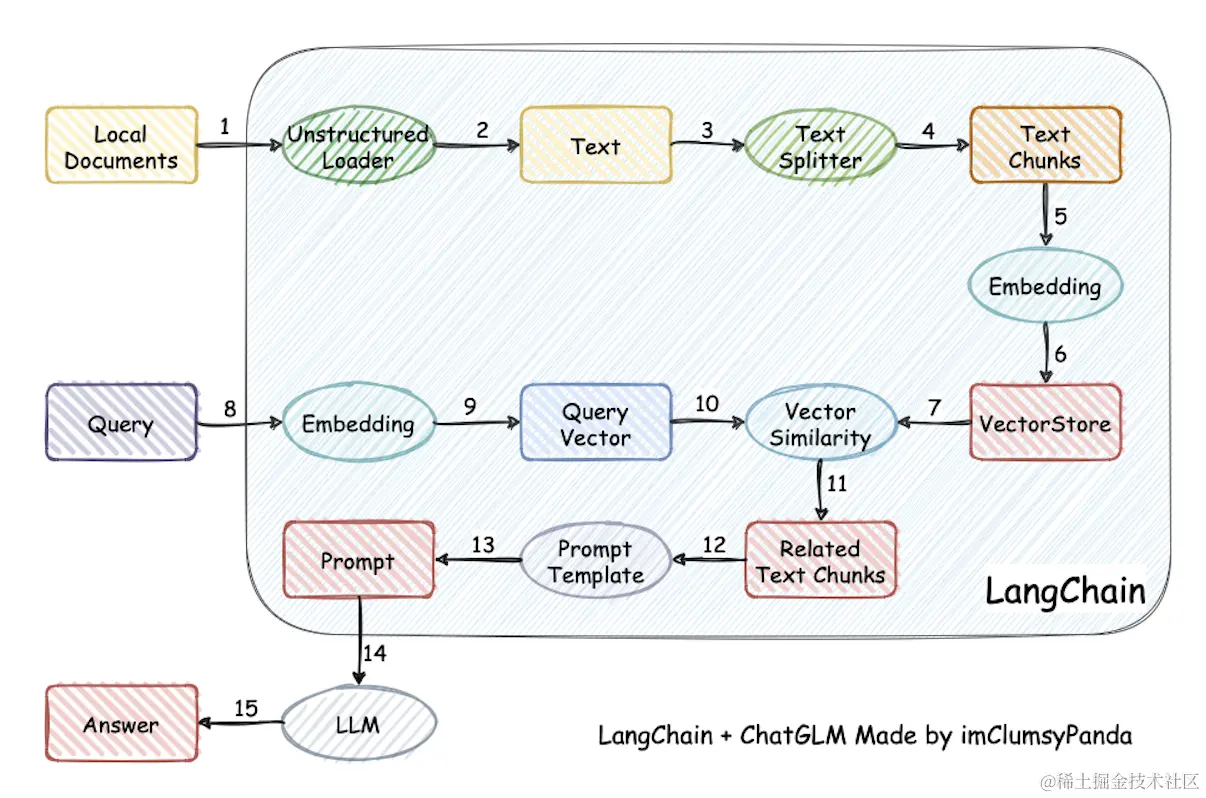
再基于本地知识库进行模型推理,包含五步:
- 输入问题;
- 向量化问题,和文本段向量化一致,将问题转化为向量;
- 搜索相关文本段,从向量索引中搜索和问题相关的文本段;
- 拼接提示,根据提示模板将问题和相关文本段转化为提示;
- 模型推理,输出答案。
代码文件retrieval_qa_demo.py如下所示:
from langchain.chains import RetrievalQA
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import MarkdownTextSplitter
from langchain.vectorstores import Chroma
from chatglm2_llm import ChatGLM2
if __name__ == "__main__":
# 加载文档
loader = UnstructuredMarkdownLoader("/Users/xxx/workspace/docs/creative.md")
documents = loader.load()
# 切分文本
text_splitter = MarkdownTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 初始化向量化模型
embeddings = HuggingFaceEmbeddings(model_name="/Users/xxx/workspace/models/text2vec-large-chinese",)
# 构建向量索引
db = Chroma.from_documents(texts, embeddings)
# 定义模型
llm = ChatGLM2()
# 加载模型
llm.load_model("/Users/xxx/workspace/models/chatglm2-6b-int4")
# 执行链路
qa = RetrievalQA.from_chain_type(llm, chain_type="stuff", retriever=db.as_retriever(), verbose=True)
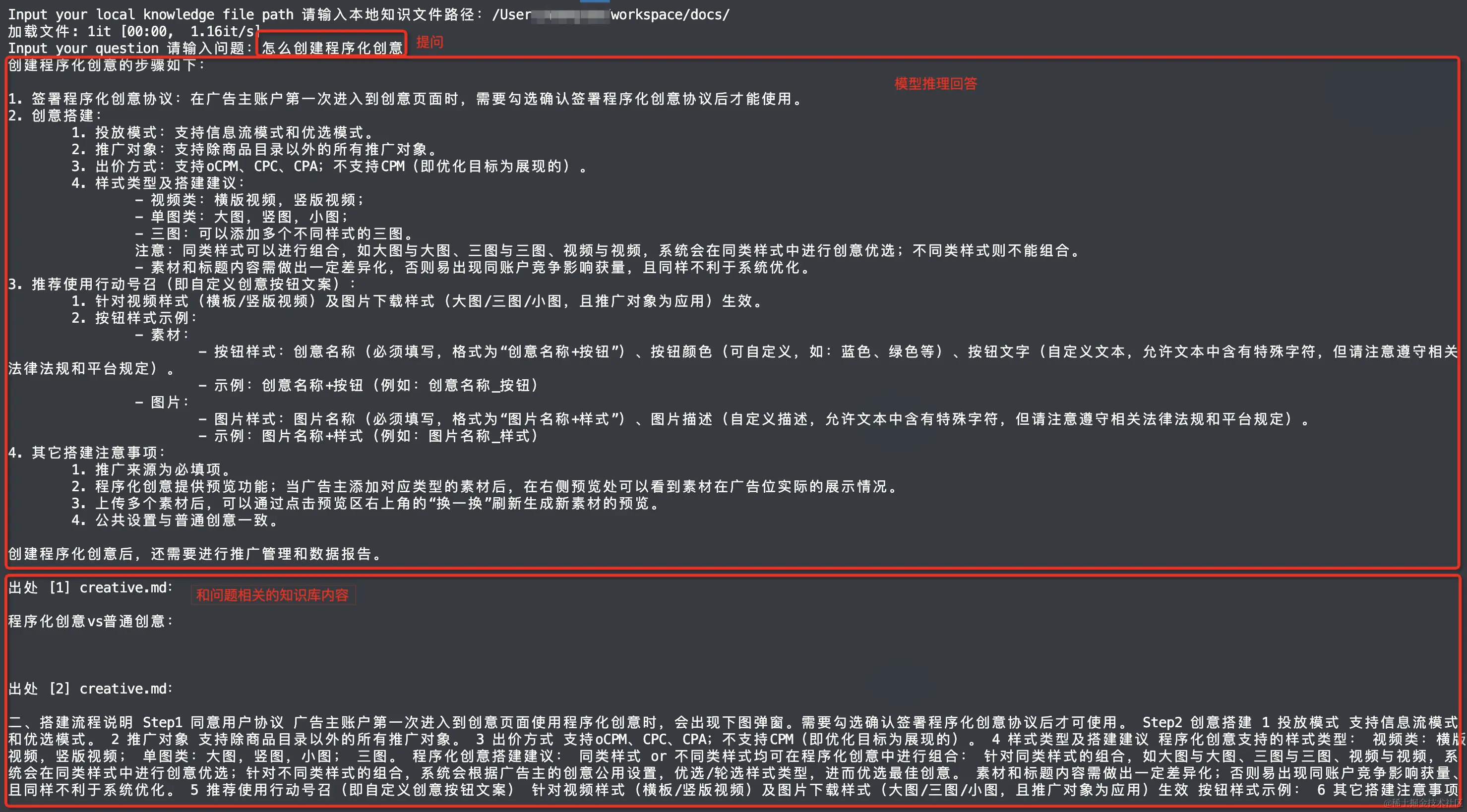
print(qa.run("怎么创建程序化创意"))
对于向量索引引擎,笔者使用Chroma;对于大语言模型,笔者使用之前已定义的ChatGLM2。对于问题和从向量索引返回的相关文本段,RetrievalQA按下述提示模板拼接提示:
Use the following pieces of context to answer the question at the end. If you don’t know the answer, just say that you don’t know, don’t try to make up an answer.
{context}
Question: {question} Helpful Answer:
retrieval_qa_demo.py运行结果如图10所示。

SQLDatabaseChain
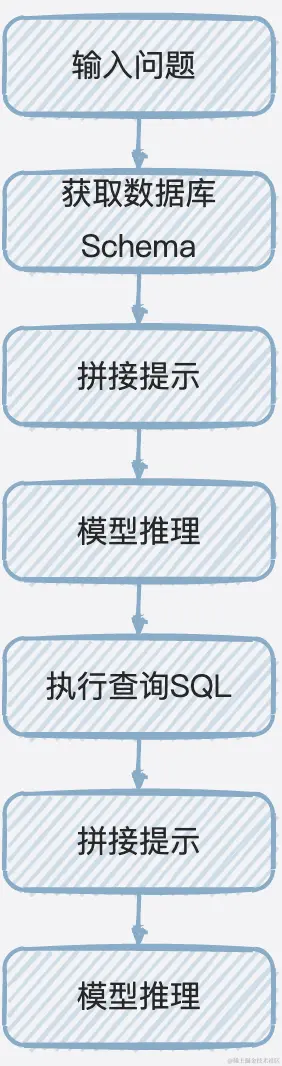
SQLDatabaseChain能够通过模型自动生成SQL并执行,其实现原理如图11所示,包含五步:
- 输入问题;
- 获取数据库Schema,Schema包含数据库所有表的建表语句和数据示例,LangChain支持多种关系型数据库,包括MariaDB、Oracle SQL、SQLite、ClickHouse、PrestoDB等;
- 拼接提示,根据提示模板将问题、数据库Schema转化为提示,并且提示中包含指示,要求模型在理解问题和数据库Schema的基础上,能够按一定的格式输出查询SQL、查询结果和问题答案等;
- 模型推理,这一步预期模型根据问题、数据库Schema推理、输出的答案中包含查询SQL,并从中提取出查询SQL;
- 执行查询SQL,从数据库中获取查询结果;
- 拼接提示,和上一次拼接的提示基本一致,只是其中的指示中包含了前两步已获取的查询SQL、查询结果;
- 模型推理,这一步预期模型根据问题、数据库Schema、查询SQL和查询结果推理出最终的问题答案。
代码文件sql_database_chain_demo.py如下所示:
from langchain import SQLDatabase, SQLDatabaseChain
from langchain.llms.fake import FakeListLLM
from chatglm2_llm import ChatGLM2
if __name__ == "__main__":
# 定义模型
# 模型先尝试用ChatGLM2
llm = ChatGLM2()
llm.load_model("/Users/xxx/workspace/models/chatglm2-6b-int4")
# 模型再直接使用固定的答案,这些答案是事先根据提示由OpenAI ChatGPT3.5给出
#responses = ["SELECT COUNT() FROM Employee", "There are 8 employees."]
#llm = FakeListLLM(responses=responses, verbose=True)
# 定义数据库
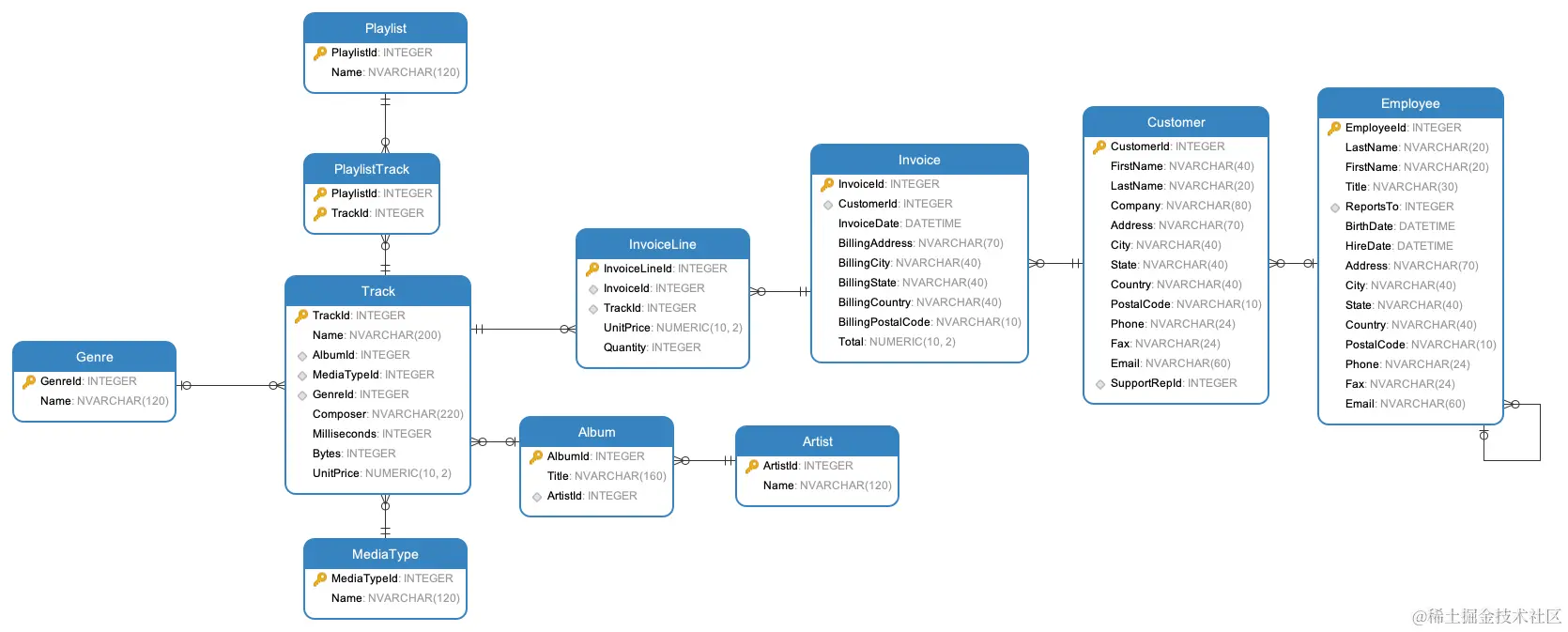
# 可以参考https://database.guide/2-sample-databases-sqlite/,创建数据库、并将数据库文件Chinook.db存储至目录
# 数据库Chinook表示一个数字多媒体商店,包含了顾客(Customer)、雇员(Employee)、歌曲(Track)、订单(Invoice)及其相关的表和数据
db = SQLDatabase.from_uri("sqlite:Users/xxx/workspace/langchain-demo/Chinook.db")
# 定义chain
chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
# 执行chain
print(chain.run("How many employees are there?"))
其中,对于大语言模型,先尝试使用之前已定义的ChatGLM2,后面会分析,从执行结果看,ChatGLM2-6B-INT4和ChatGLM2-6B并不能输出符合格式的答案,从而无法进一步从中提取出查询SQL,所以通过FakeListLLM直接使用固定的答案,而这些答案事先根据提示由OpenAI ChatGPT3.5给出。 对于数据库引擎,使用SQLite3(Macbook原生支持),对于数据库实例,使用[Chinook],可按照上述链接中的说明下载“Chinook_Sqlite.sql”并在本地创建数据库实例。Chinook表示一个数字多媒体商店,包含了顾客(Customer)、雇员(Employee)、歌曲(Track)、订单(Invoice)及其相关的表和数据,如图12所示。问题是“How many employees are there?”,即有多少雇员,期望模型先给出查询Employee表记录数的SQL,再根据查询结果给出最终的答案。
实际执行时,SQLDatabaseChain首先根据问题和数据库Schema生成如下的提示:
You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question. Unless the user specifies in the question a specific number of examples to obtain, query for at most 5 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database. Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers. Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table. Pay attention to use date(‘now’) function to get the current date, if the question involves “today”. Use the following format: Question: Question here SQLQuery: SQL Query to run SQLResult: Result of the SQLQuery Answer: Final answer here Only use the following tables: {数据库Schema,包含所有表的建表语句和数据示例,受限于篇幅,这里略去} Question: How many employees are there? SQLQuery:
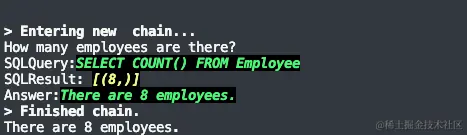
其中,提示的第一部分是指示,期望模型作为SQLite的专家,按照一定的要求进行推理,并按照一定的格式输出,第二部分是数据库Schema,第三部分是问题以及期望输出的开头“SQLQuery:”,预期模型按照提示续写,给出查询SQL。 若将提示输入ChatGPT3.5,可以返回预期的答案,SQLDatabaseChain进一步提取答案中“\nSQLResult”之前的部分,从而得到查询SQL:
SELECT COUNT() FROM Employee SQLResult: COUNT() 8 Answer: There are 8 employees.
若将提示输入自定义的ChatGLM2(使用ChatGLM2-6B-INT4),则无法返回预期的答案(答案合理、但不符合格式要求):
SQLite is a language for creating and managing databases. It does not have an SQL-specific version for getting the number of employees. However, I can provide you with an SQL query that you can run using a SQLite database to get the number of employees in the “Employee” table.
SQLite:SELECT COUNT(*) as num_employees FROM Employee;This query will return the count of employees in the “Employee” table. The result will be returned in a single row with a single column, labeled “num_employees”.
SQLDatabaseChain的提示是针对ChatGPT逐步优化、确定的,因此适用于ChatGPT,LangChain官方示例中使用的大语言模型是OpenAI,即底层调用ChatGPT,而ChatGLM2-6B-INT4、ChatGLM2-6B相对于ChatGPT,模型规模较小,仅有60亿参数,对于上述的长文本提示无法给出预期的答案。由于没有OpenAI的Token,因此示例代码通过FakeListLLM直接使用由ChatGPT3.5给出的答案。 在获取查询SQL后,SQLDatabaseChain会执行该SQL获取查询结果,并继续根据问题、数据库Schema、查询SQL和查询结果生成如下的提示:
You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question. Unless the user specifies in the question a specific number of examples to obtain, query for at most 5 results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database. Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers. Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table. Pay attention to use date(‘now’) function to get the current date, if the question involves “today”. Use the following format: Question: Question here SQLQuery: SQL Query to run SQLResult: Result of the SQLQuery Answer: Final answer here Only use the following tables: {数据库Schema,包含所有表的建表语句和数据示例,受限于篇幅,这里略去} Question: How many employees are there? SQLQuery:SELECT COUNT(EmployeeId) FROM Employee SQLResult: [(8,)] Answer:
相比上次提示,本次提示只是在末尾追加了查询SQL和查询结果,若将提示输入ChatGPT3.5,则可以续写“Answer”,给出正确的答案:
There are 8 employees.
这里也通过FakeListLLM直接使用由ChatGPT3.5给出的答案,从而在本地跑通SQLDatabaseChain的流程,运行结果如图13所示。
Agent
Agent组合模型和各种工具,相对于Chain已固定执行链路,Agent能够实现动态的执行链路,实现如图14中的ReAct架构。ReAct架构是一个循环过程,对于问题,通过多次迭代,直至获取最终答案,而每次迭代包括如下几步:
- 将问题,各工具描述,之前每次迭代模型推理出的思考(Thought)、工具(Action)、工具输入(Action Input)、工具执行后的输出(Observation),以及期望模型输出格式,按照提示模板拼接出提示;
- 将提示输入模型,由模型推理,输出进一步的思考(Thought)、工具(Action)、工具输入(Action Input);
- 使用模型给出的工具输入执行相应工具,获取工具输出(Observation);
- 继续第一步过程,直至获取最终答案跳出循环。
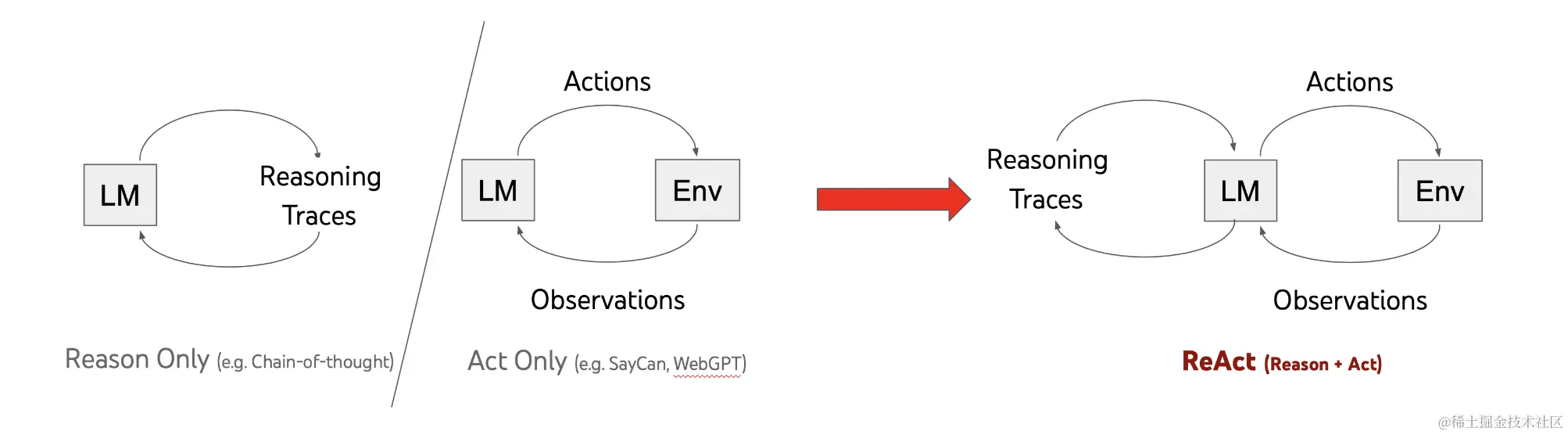
LangChain官方有个比较经典的实现ReAct架构的[示例],其需要OpenAI和[SerpApi]的Token,针对问题,使用ChatGPT进行多次推理,根据推理结果先使用搜索工具查询相关人的年龄,再使用计算器工具计算年龄的乘方,从而得到最终的答案。感兴趣且有OpenAI和SerpApi Token的同学可以在本地执行示例代码体验,此处不再赘述。 上述示例若使用本地部署的ChatGLM2-6B-INT作为大语言模型,则和在SQLDatabaseChain中遇到的问题相同,无法根据提示给出符合预期格式的答案。可见,虽然LangChain在设计上考虑了可扩展性,将Model以接口形式对外提供服务,屏蔽底层实现细节,但各种Chain、Tool和Agent中的提示模板还是针对ChatGPT进行了专门优化。
langchain-ChatGLM
介绍
langchain-ChatGLM中使用的提示模板如下,其中“{question}”是提问的问题,“{context}”是将知识库中和问题相关的文本段用换行符拼接在一起:
已知信息: {context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。 问题是:{question}
部署
创建并激活环境:
conda create --name langchain-chatglm python=3.9 conda activate langchain-chatglm
下载langchain-ChatGLM源码:
cd ~/workspace/ git clone [github.com/imClumsyPan…]
安装依赖:
cd ~/workspace/langchain-ChatGLM pip install -r requirements.txt
安装依赖的过程中,可能会因为缺少Cmake、protobuf和swig导致依赖PyMuPDF和oonx安装失败,因此对Cmake、protobuf和swig进行安装:
brew install Cmake brew install protobuf@3 #需指定版本,否则会报版本不一致错误 brew install swig
langchain-ChatGLM会使用模型进行自然语言文本的向量化,可以将这些模型下载到本地(若在RetrievalQA部分已下载,则无需再下载):
cd ~/workspace/models/ git lfs install #若ChatGLM-6B部分已执行,则无需再执行 git clone [huggingface.co/GanymedeNil…]
修改configs/model_config.py,修改第19行,设置文本向量化模型text2vec的本地地址:
"text2vec": "/Users/xxx/workspace/models/text2vec-large-chinese", #"text2vec": "GanymedeNil/text2vec-large-chinese",
修改第46行,设置ChatGLM2-6B-INT4的本地地址:
"local_model_path": "/Users/xxx/workspace/models/chatglm2-6b-int4", #"local_model_path": None,
修改第114行,将大语言模型由ChatGLM-6B改为ChatGLM-6B-INT4(实际使用的是ChatGLM2-6B-INT4):
LLM_MODEL = "chatglm-6b-int4" #LLM_MODEL = "chatglm-6b"
修改model/loader/loader.py第147行关于加载大语言模型的代码,删除或注释“to(self.llm_device)”:
model = (
LoaderClass.from_pretrained(
checkpoint,
config=self.model_config,
trust_remote_code=True)
.float()
#.to(self.llm_device)
)
实践中,“self.llm_device”的取值为“mps”(即使用并行处理),但若使用该设置,则会报以下错误:
File “/Users/xxx/.cache/huggingface/modules/transformers_modules/chatglm2-6b-int4/quantization.py”, line 54, in forward weight = extract_weight_to_half(quant_w, scale_w, weight_bit_width) File “/Users/xxx/.cache/huggingface/modules/transformers_modules/chatglm2-6b-int4/quantization.py”, line 261, in extract_weight_to_half assert scale_list.dtype in [torch.half, torch.bfloat16] AssertionError
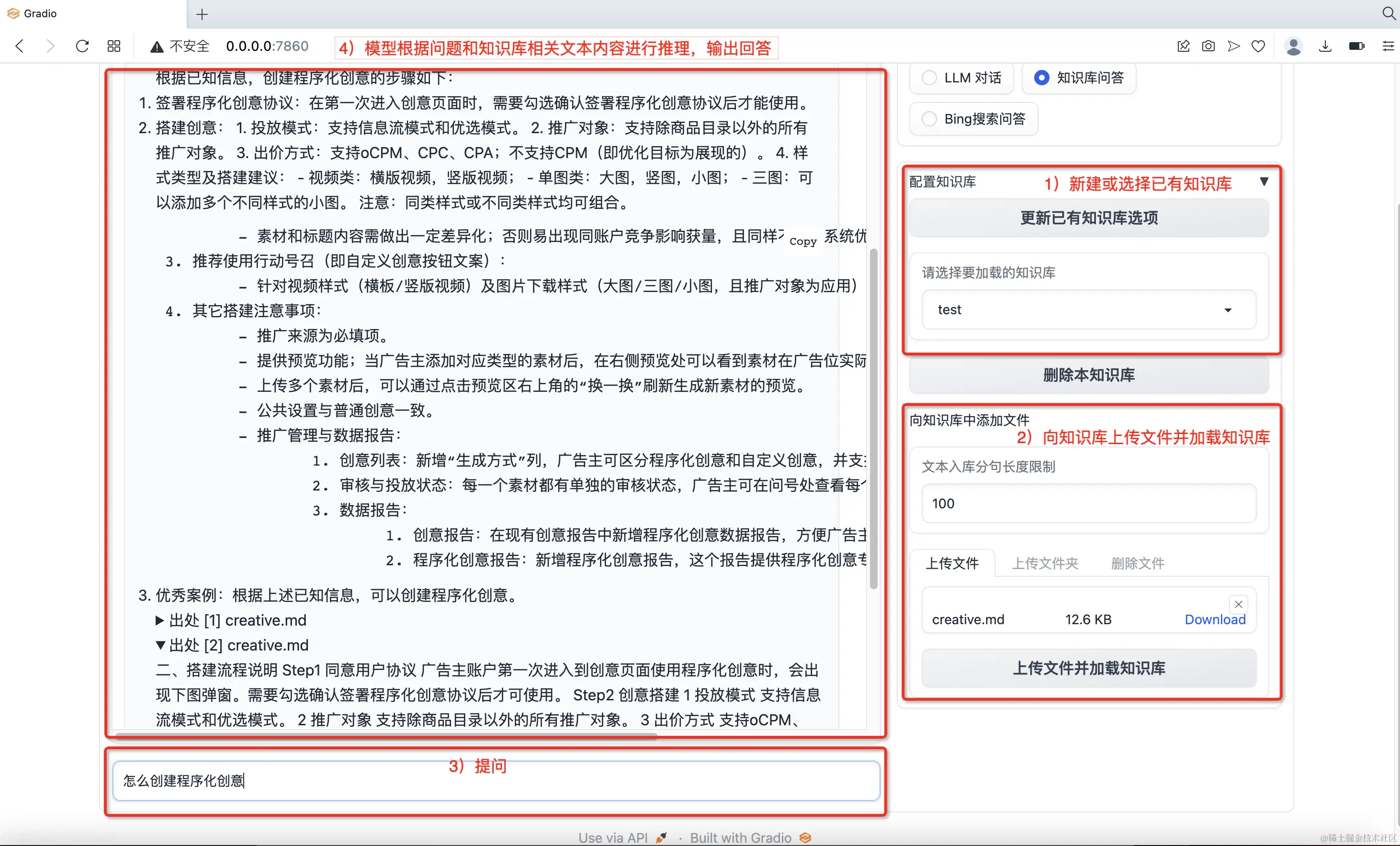
准备本地知识库,笔者使用[《超级汇川程序化创意产品手册》]这一文档,将其以Markdown格式下载至本地,读者也可以使用该文档或其他文档。 执行cli_demo.py:
python cli_demo.py
按提示先指定本地知识库,本地知识库同时支持目录和文件,对于目录,会扫描其中的文件。langchain-ChatGLM会对文件内容进行切分、向量化并构建向量索引。随后可以提问和本地知识库相关的问题。langchain-ChatGLM对问题进行向量化并从向量索引中寻找语义相关的知识库内容,将问题和知识库内容按提示模板拼接在一起后作为大语言模型的输入由其进行推理,给出最终的回答,同时也列出与问题相关的知识库内容。执行结果如图16所示。
执行webui.py:
python webui.py
启动后的WEB UI如图17所示。
结语
以上记录了在本地部署ChatGLM-6B、ChatGLM2-6B、LangChain、langChain-ChatGLM并进行推理的过程,不包含模型的微调。通过过程中的不断学习,对大语言模型及其周边生态、以及在多种场景下的应用,有了一定的了解。但将大语言模型应用在真实场景、发挥真正作用,还需要在语料搜集、模型微调、提示设计等方面针对业务特点进行不断的打磨。文章内容如有错误之处,欢迎指正和交流。另外,本地部署仅为了快速体验,目前也有很多免费的GPU云资源可以申请,例如[阿里云],通过其可以在GPU云资源上进行模型的微调和推理。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









