







目录
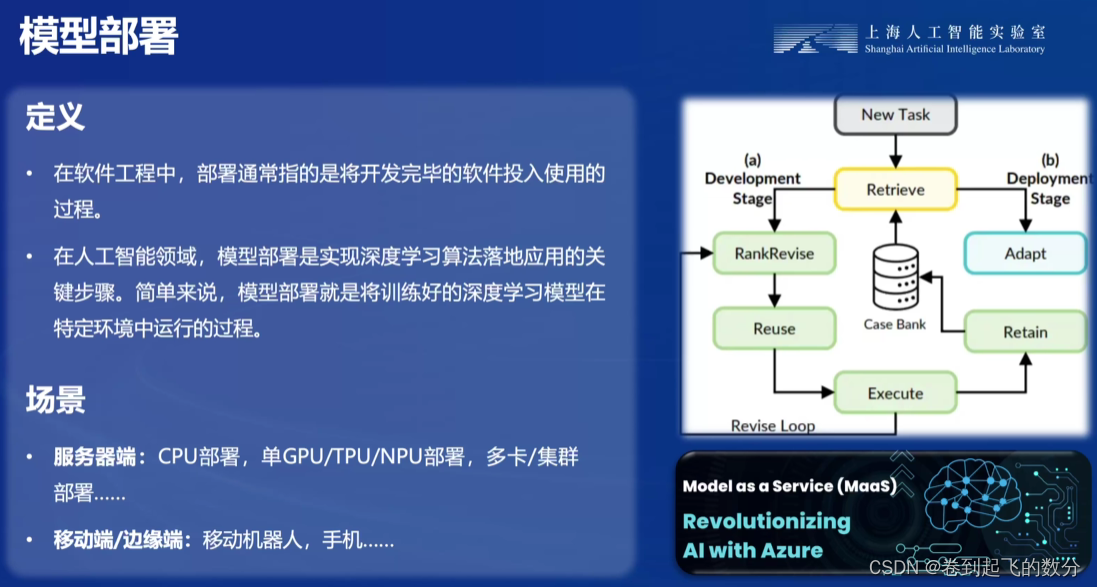
一、模型的部署
二、模型部署面临的问题
显存受限
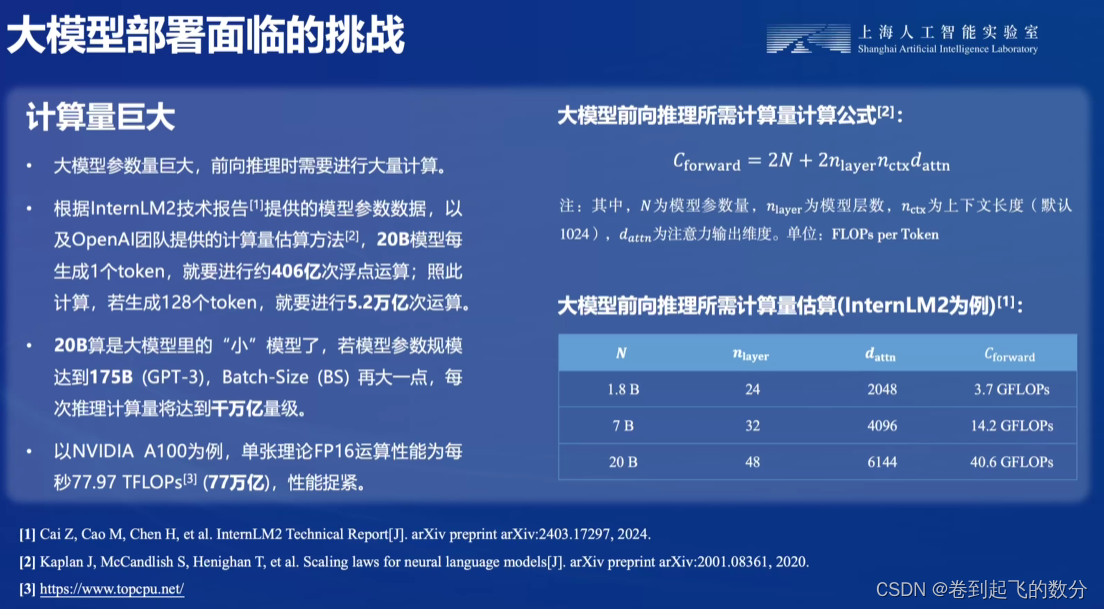
访问密集型

三、如何解决(两种方法)

最开始应用在CV领域
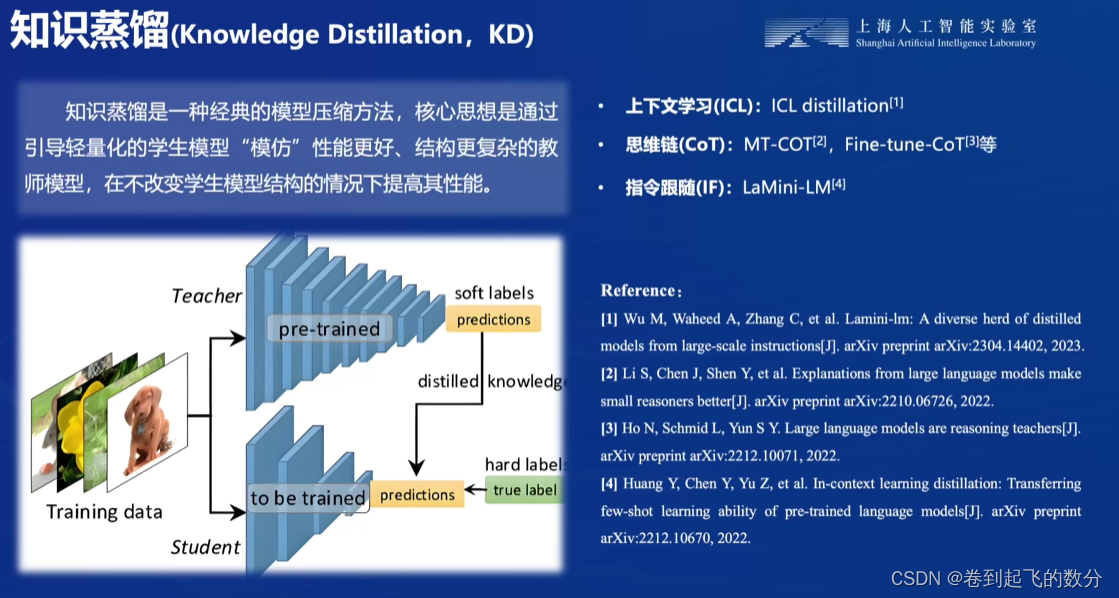
多了量化和非量化工作,可能降低性能

四、LMDeploy相关知识

优化KV缓存管理与存储

性能表现

还支持视觉推理

五、部署实践(安装、部署、量化)
创建conda环境(漫长的等待)
studio-conda -t lmdeploy -o pytorch-2.1.2
激活刚刚创建的虚拟环境:
conda activate lmdeploy
安装0.3.0版本的lmdeploy:
pip install lmdeploy[all]==0.3.0
查看本地的预训练模型
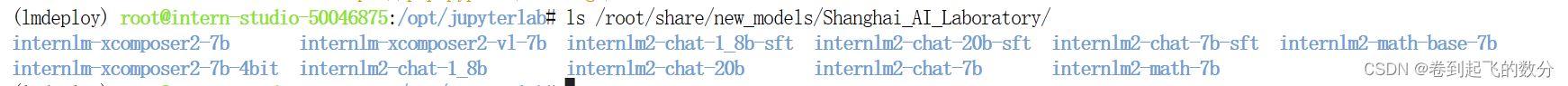
使用 Transformer库运行模型,先创建指令
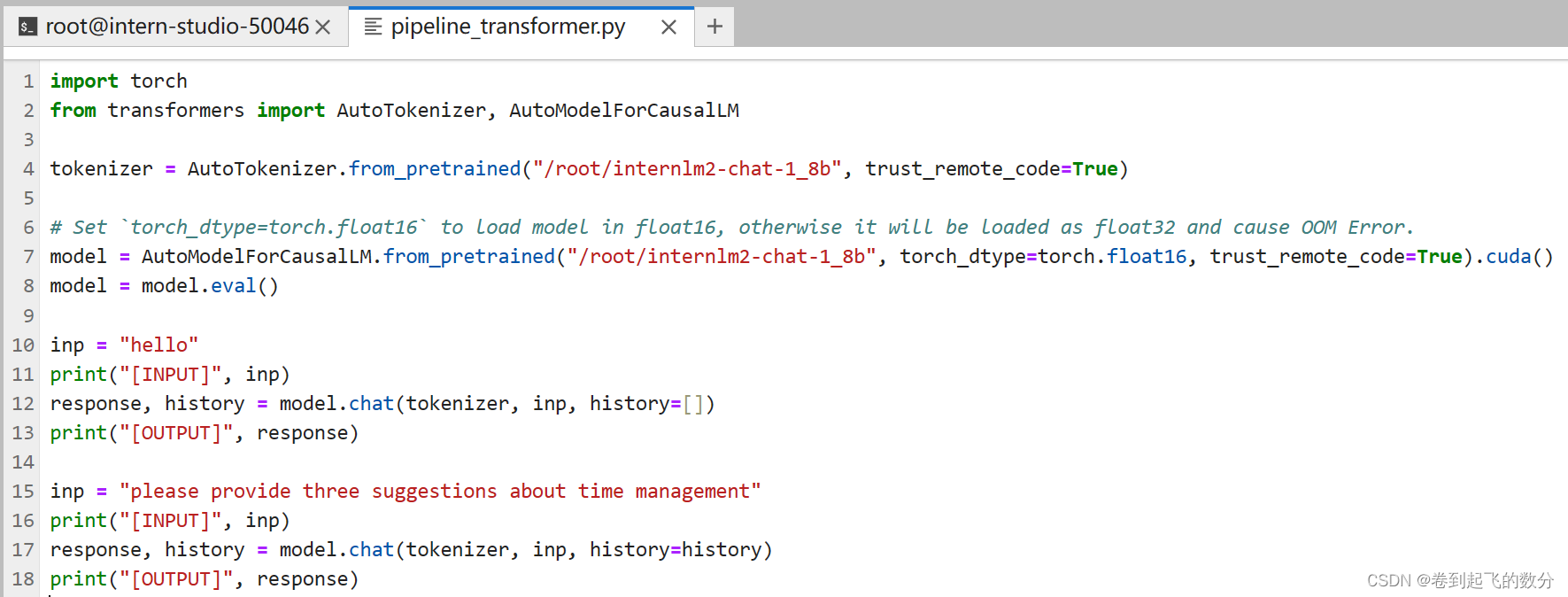
运行效果

五、使用LMDeploy与模型对话
连接到模型
lmdeploy chat /root/internlm2-chat-1_8b
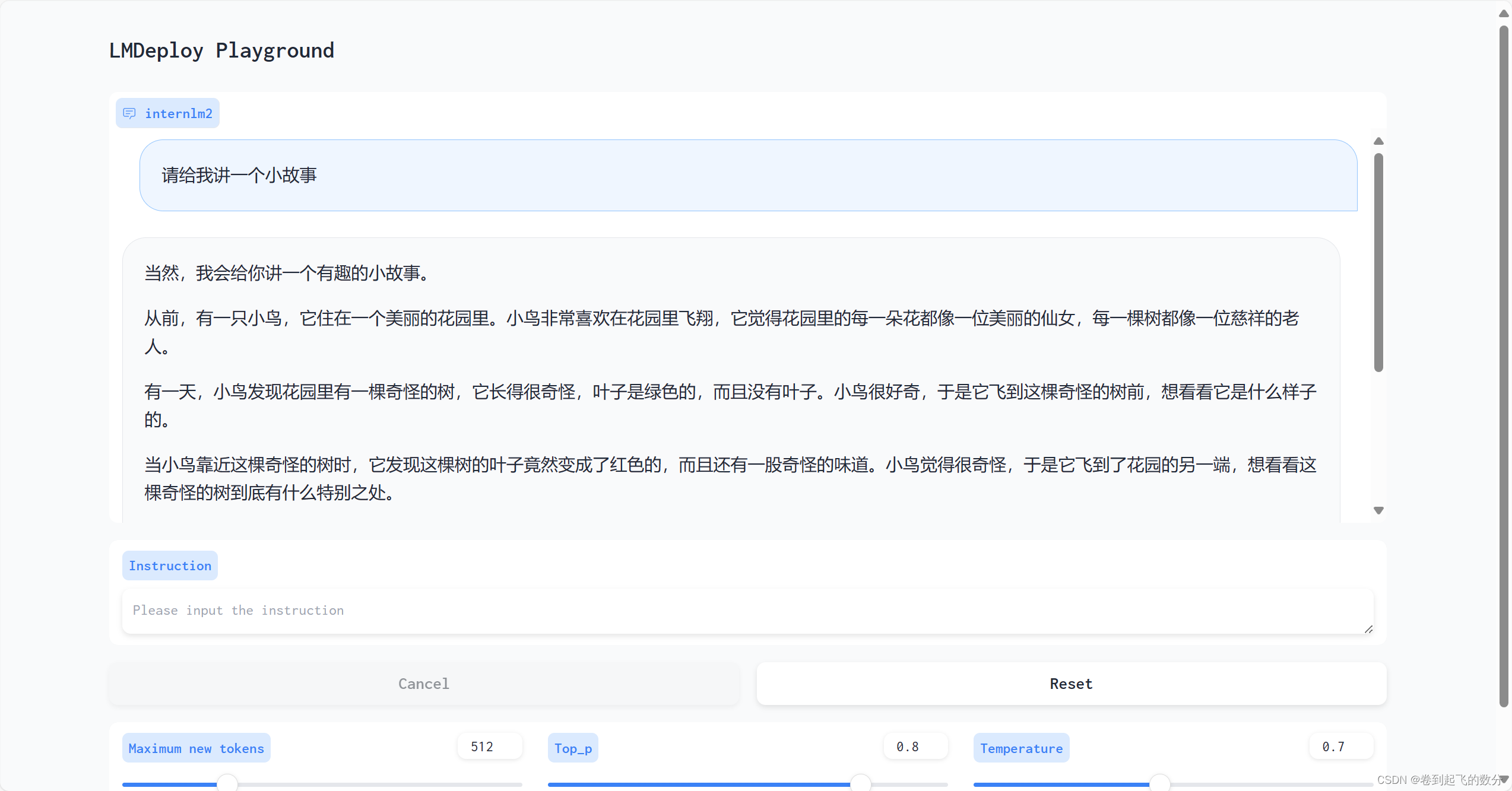
结果输出:(提问 -> 请你给我讲一个小故事)

六、设置最大KV Cache缓存大小
资源监视器中的显存占用情况(未改变参数)

改变--cache-max-entry-count参数,设为0.5

改变--cache-max-entry-count参数设置为0.01

七、W4A16量化
LMDeploy使用AWQ算法,实现模型4bit权重量化

八、客户端连接API服务器
启动API服务器后进行连接:

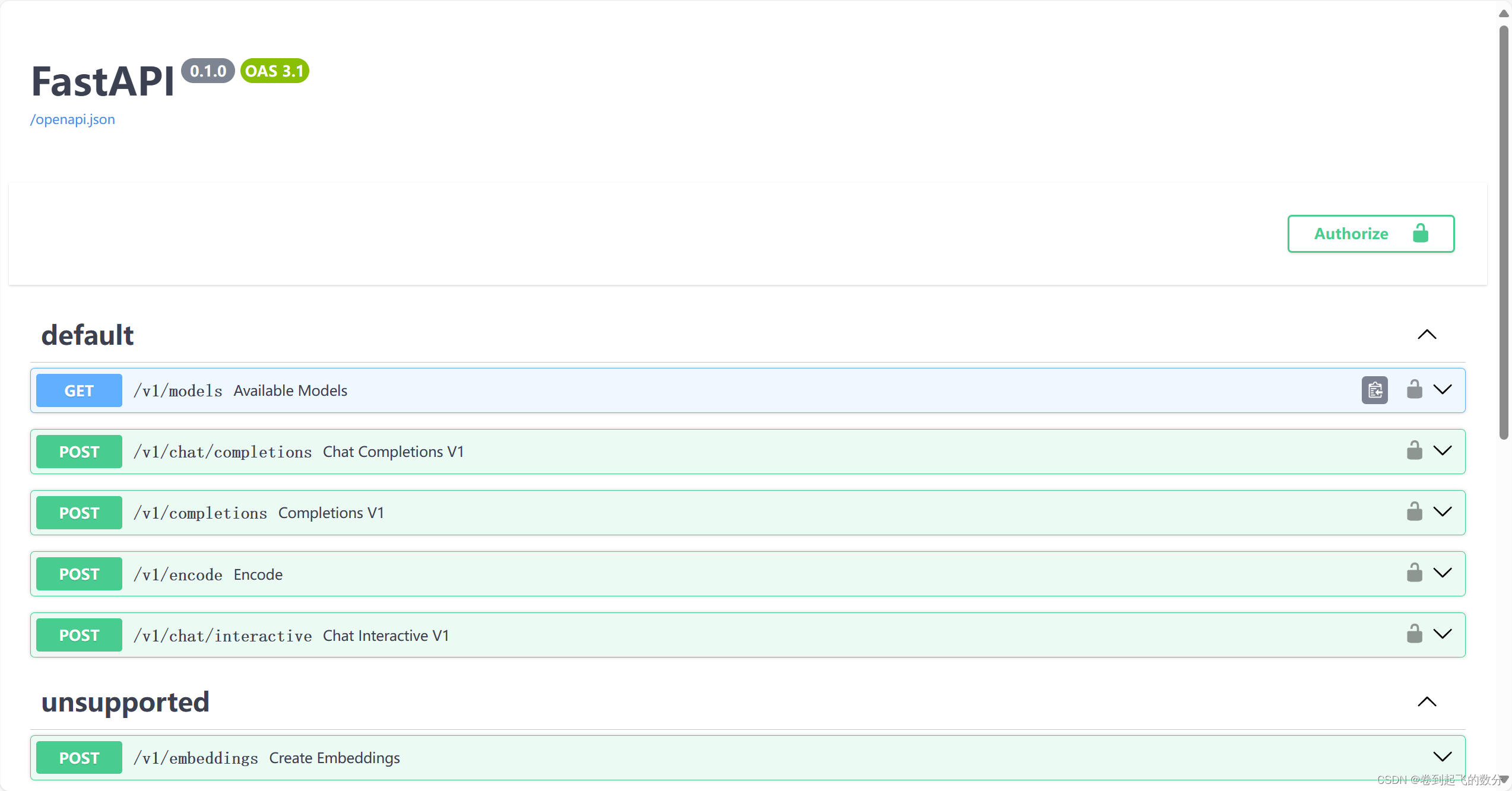
web页面连接















 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









