







目录
以命令行方式与 InternLM2-Chat-1.8B 模型对话
课程文档 Link: Tutorial/lmdeploy/README.md at camp2 · InternLM/Tutorial · GitHub
视频链接:LMDeploy 量化部署 LLM-VLM 实践_哔哩哔哩_bilibili
Intro
之前的课程中学习了:1)使用RAG范式开发大模型 2)使用XTuner微调大模型,这些的目的都是为了能够使大模型的回答更加贴合我们的需求。但最终,模型都是要服务于实际业务场景,这个时候就涉及到模型部署。
模型部署Definition:将训练好的模型,部署到服务器端 or 边缘端。
- 需要考虑很多问题:比如在服务器端部署,假设部署到集群,如何进行分布式推理大模型;边缘端的计算能力是否足够
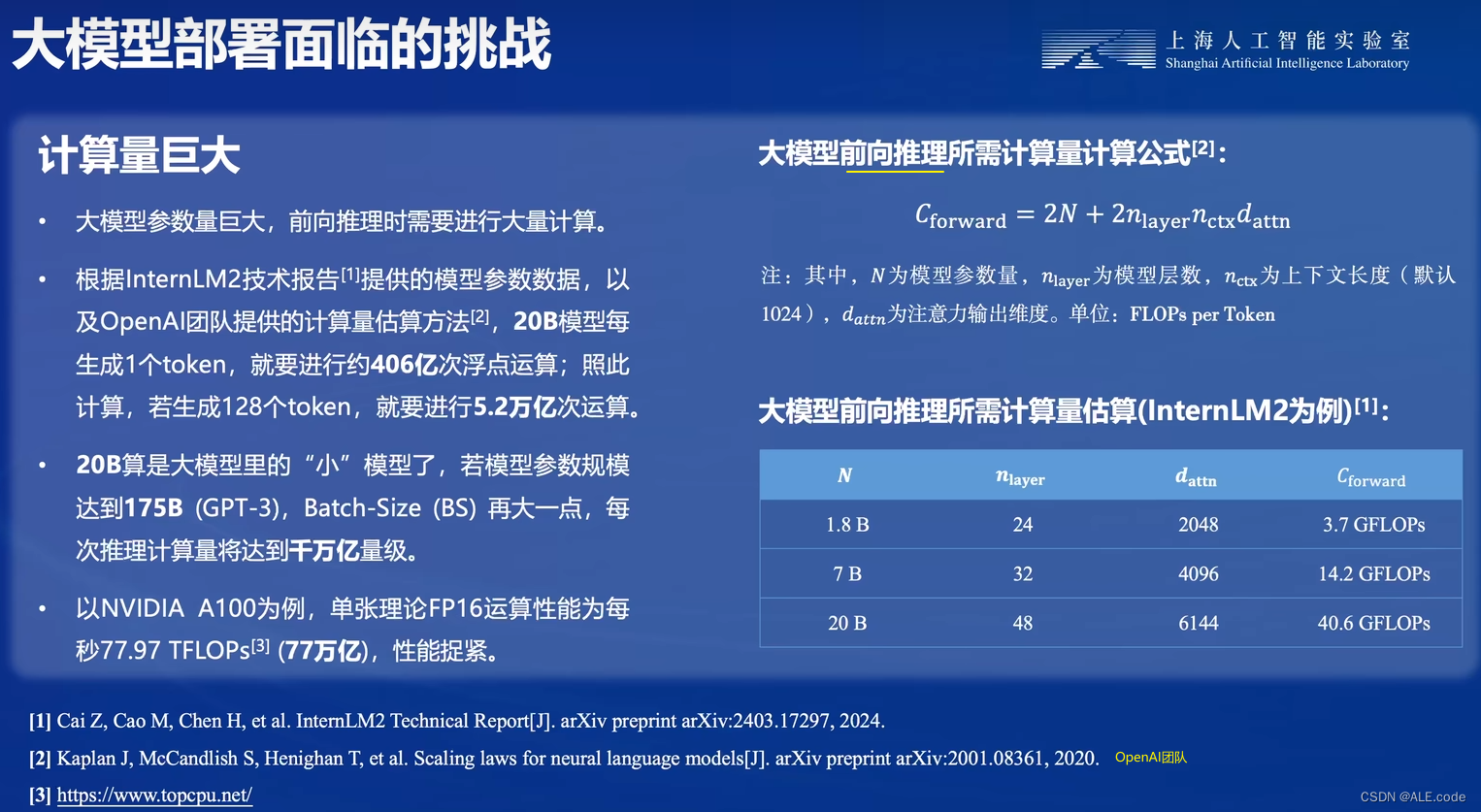
- 在实际部署时会遇到很多难点,比如:大模型的参数量和计算量非常巨大,那么如何在有限的资源中,加载和推理大模型?

大模型部署的痛点
1. 计算量巨大
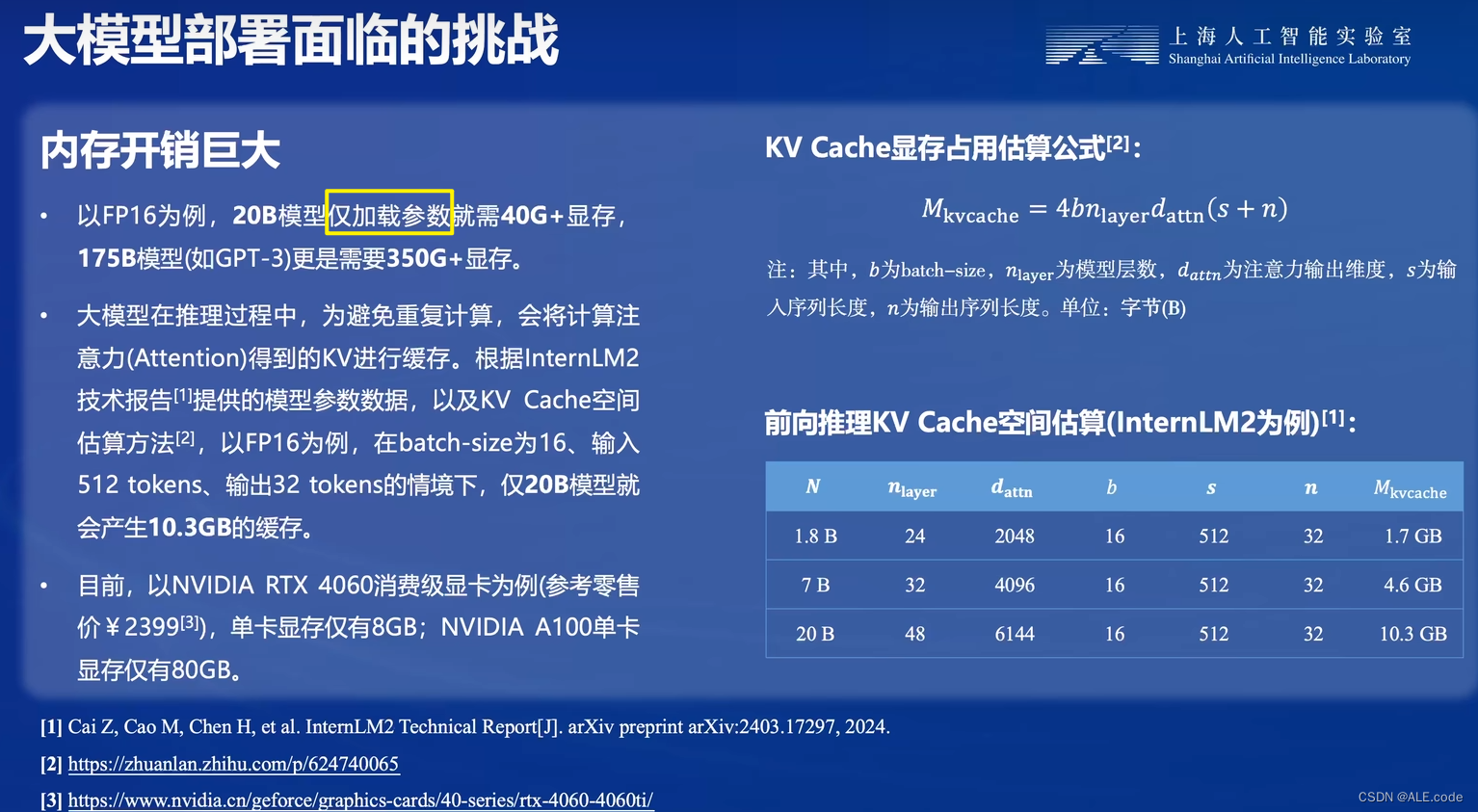
2. 内存开销巨大
以16浮点数为例,每个参数占用2个字节。那么20B模型,加载参数40G+ 显存,10.3G缓存,加起来就要至少50.3G 显存。
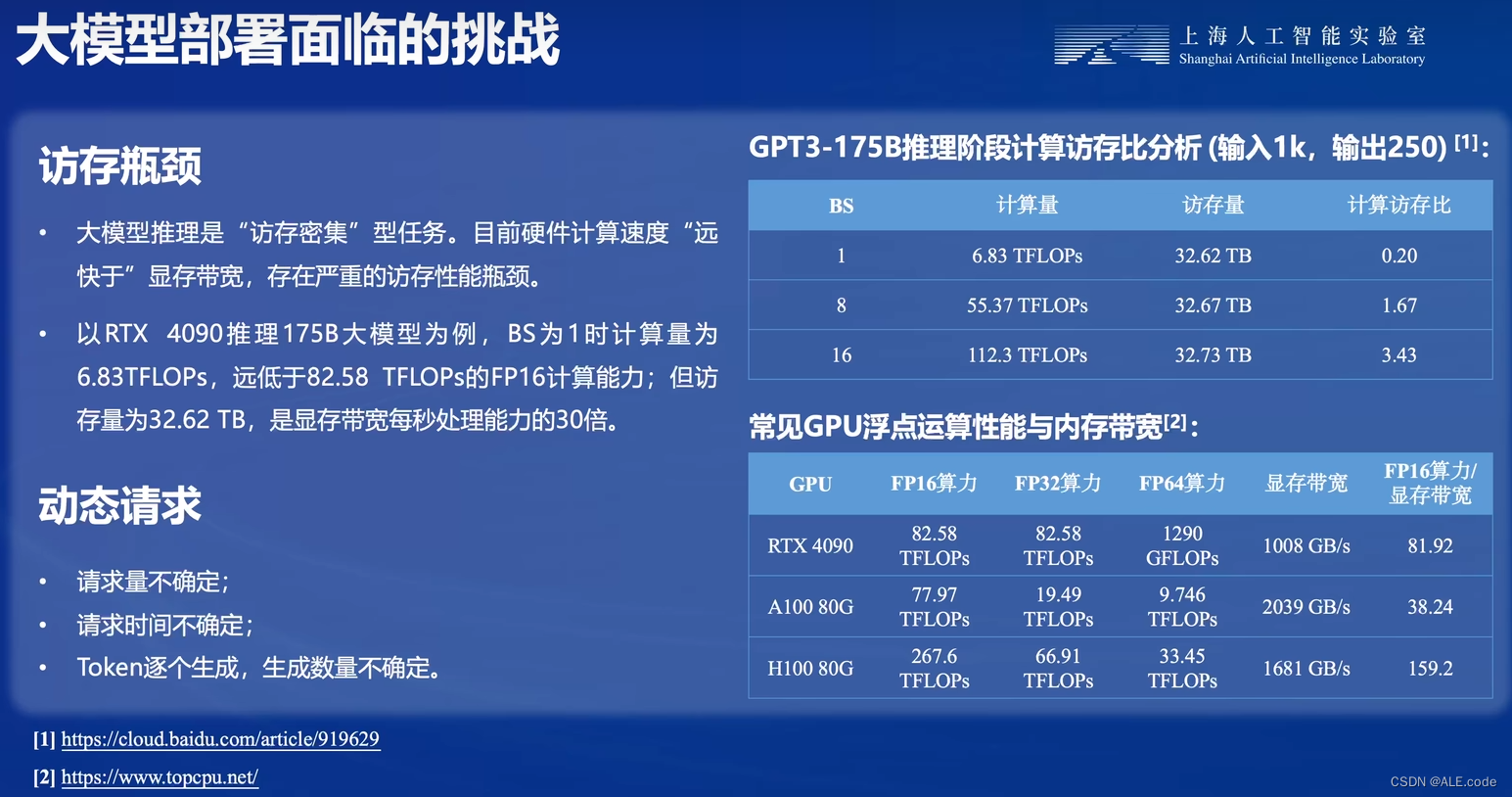
3.访存瓶颈与动态请求
目前常用的模型部署方法(三类)
目的:减少模型的冗余参数
1. 模型剪枝
2. 知识蒸馏
3. 量化(核心:把浮点数转换为整数 or 其他离散形式)
模型参数存储一般是以32位浮点数进行存储的,一个参数占用4个字节。存在一些冗余的情况,在满足回答的情况下,可以将浮点数转换为定点数(比如:8位,4位 or平均1位的整数)。
- 优点:模型量化可以提升efficiency,提升速度!(大模型,访存密集型,访存远大于计算的瓶颈,通过量化可以把访存量降低, 可以显著降低数据传输所用的时间)



动手实践
完成以下任务,并将实现过程记录截图:
-
配置 LMDeploy 运行环境
# 配置 LMDeploy 运行环境
studio-conda -t lmdeploy -o pytorch-2.1.2
# 激活刚刚创建的虚拟环境,并安装0.3.0版本的lmdeploy
conda activate lmdeploy
pip install lmdeploy[all]==0.3.0
注: Huggingface与TurboMind大致介绍(截图来自课程文档,详细可以看页首的课程文档link!)

-
以命令行方式与 InternLM2-Chat-1.8B 模型对话

注:这里对比一下和传统的使用Transformer库运行的区别
- Transformer库是Huggingface社区推出的用于运行HF模型的官方库。
对比一下使用Transformer来直接运行InternLM2-Chat-1.8B模型,以及LMDeploy的使用感受,速度明显比原生Transformer快!
LMDeploy模型量化

模型量化-1.设置最大KV Cache缓存大小

上述运行chat的时候,占用显存为如下图:
![]()
可以通过上图的显存占用情况发现,占显存还是比较多的,那么能否进行显存占用呢?
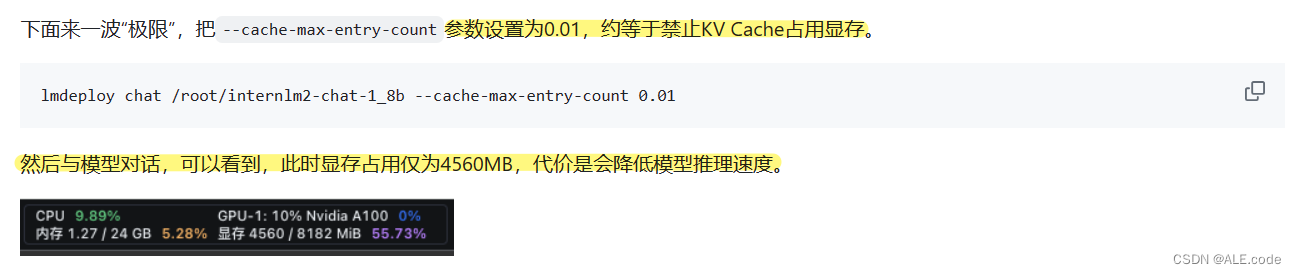
# 尝试这个命令,设成0.01,约等于禁用KV Cache占用显存
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.01运行完这个命令之后显存占用,从原来7856M到4552M,有降低!
![]()
模型量化-2. 使用W4A16量化

只用输入下面这个命令就可以完成量化:
lmdeploy lite auto_awq \
/root/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit参数注释:
- lite auto_awq:使用自动awq算法
- 采用‘ptb’数据集
- 采样128个数据对
- 量化上下文长度:1024
- 量化工作结束后,新的HF模型被保存到
internlm2-chat-1_8b-4bit目录( --work-dir /root/internlm2-chat-1_8b-4bit)

运行完上面量化命令后,得到量化后的model,可以进行测试:
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.01此时的显存占用:
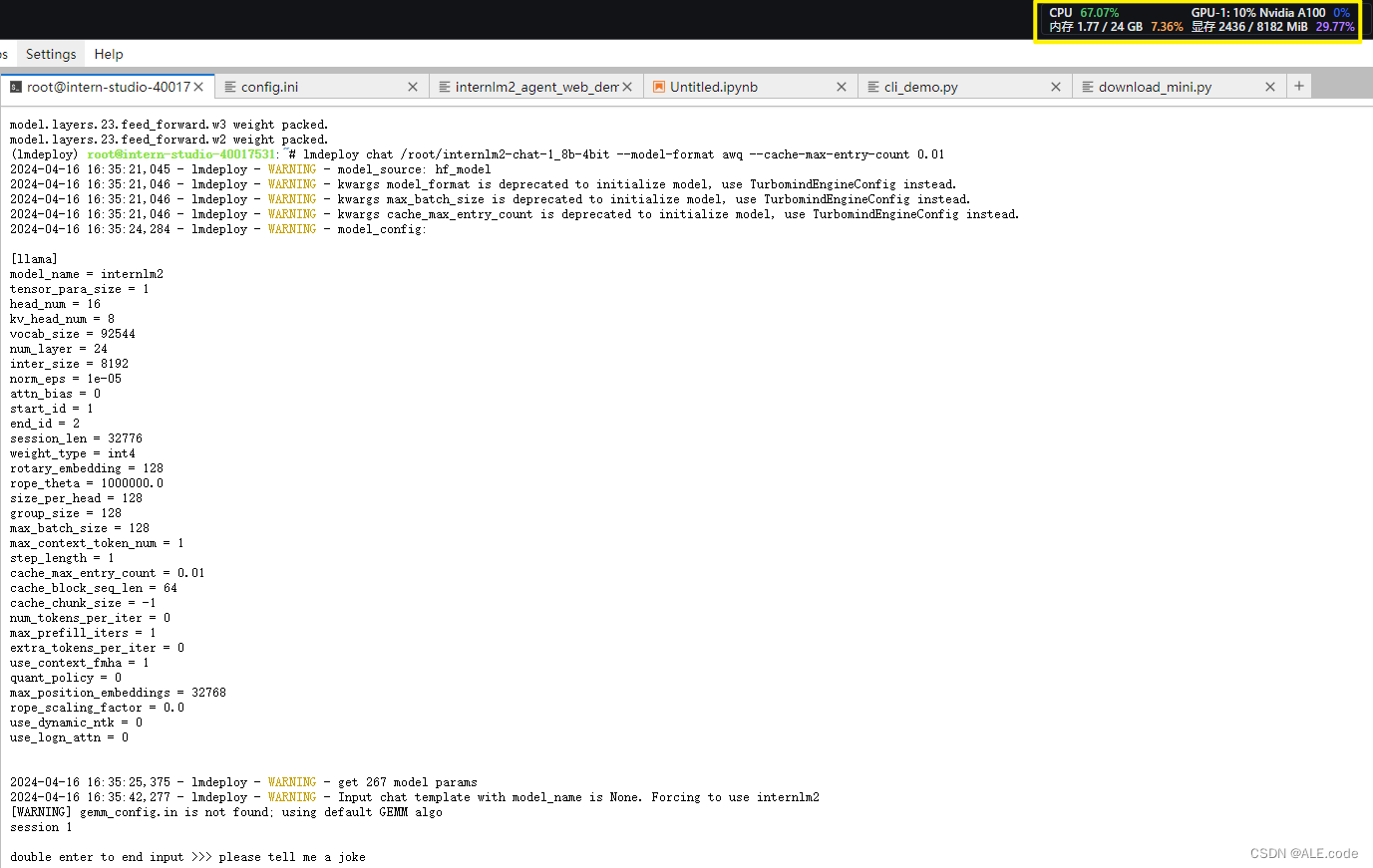
显存此时只占用2436M,也有很大降低
参考内容
1. 这个笔记内容非常详尽,可以参考👍🏻[InternLM2]LMDeploy 量化部署 LLM&VLM 实践【书生·浦语大模型实战营第二期第五节笔记和作业】 - 知乎 (zhihu.com)
2. 关于模型量化之AWQ,下面这两个博客都不错:














 1201
1201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









