







层次分析法 (Analytic Hierarchy Process,简称 AHP) 由美国运筹学家托马斯 · 塞蒂 (T. L. Saaty) 于上世纪70年代中期提出,是通过定量与定性分析相结合的方法来进行多方案或多目标决策分析的一种方法。该方法的主要思想是通过将一个复杂的问题分解为若干层并考虑不同因素,对两两指标进行成对比较判断其重要程度,并建立判断矩阵进行重要性程度的权重确定,最终找到最佳方案来辅助决策。
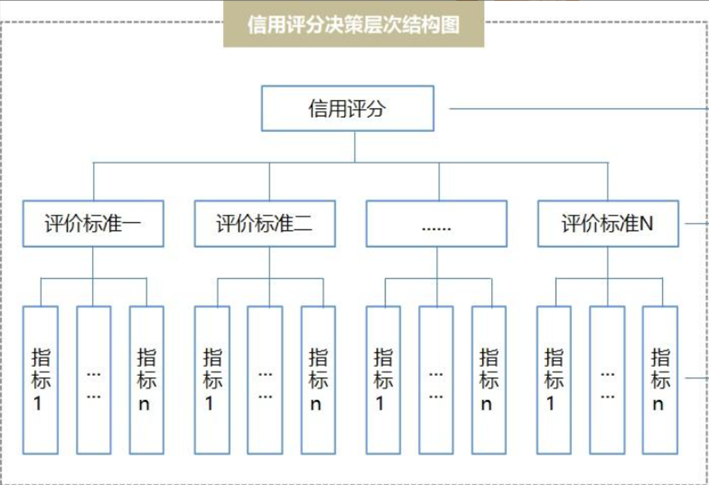
专家经验评分卡多用于新产品无数据积累的冷启动阶段,对申请人进行信用评分,本文基于自己工作中实操经验与理解以及一些公开资料,详细的介绍了整个流程。专家经验评分卡适用于业务开展初期和数据量少,主要基于过往业务经验、同业历史经验进行评分卡设计,直观、业务解释性强,主要通过多轮专家调查问卷并结合AHP层次分析法得到入模指标与权重,最终得到得分,进一步确定得分等级映射、综合信用评分的决策矩阵和定额定价策略。
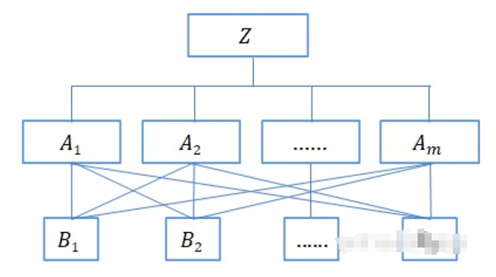
层次分析法开发专家评分卡是利用定量与定性分析相结合,以得到借款人信用评分为目标,构成一个多层次的分析结构模型,以评分为总目标(最高层)、评价标准为准则层(中间层)、评价指标为方案层(最底层),通过专家在各个因素之间进行比较、打分和计算,最终确定最底层相对于最高层的相对权重,得到最底层每个指标的最终得分。
层次分析法就是将一个决策事件分解为目标层(例如借款人资质如何),准则层(影响决策的因素,例如信用、资产、经营情况等)以及方案层(是方案,例如张三、李四、王五等各个借款人资质)
▍基于层次分析法的专家评分卡开发理论
步骤一:围绕信用评分问题,建立具有层次结构的指标体系
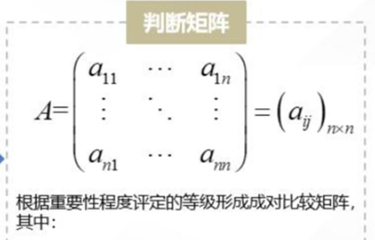
步骤二:将同一层次指标取出,构造两两比较矩阵(判断矩阵)
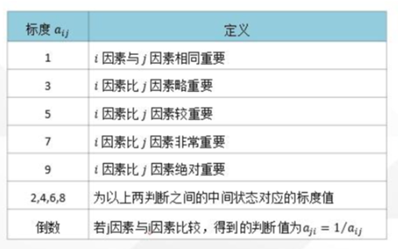
准则层中的各个准则在进行目标衡量过程中所占的重要性权重不同,根据Saaty的建议使用数字1-9及其倒数(如果元素 i 和元素 j 的重要性之比为 ,那么元素 j 与元素 i 的重要性之比为 ,例如: ,则 )作为标度来定义判断矩阵 , ,详见表1:
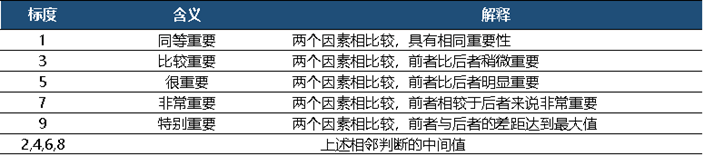
步骤三:层次单排序及一致性检验
步骤四:层次总排序及一致性检验
1.建立具有层次结构的指标体系
根据问题的性质和总目标,将问题分解为不同的组成因素。同一层次的元素作为准则对下一层次的某些元素起支配作用,同时它又受上一层次元素的支配。这些层次大体上可以分为3类。
2.构造两两比较矩阵
目标:准确测量出信用评分指标间的相对重要程度,得到权重。
方法:为了比较下层对上层的相对重要性,构造两两比较矩阵。通常会邀请10-20个经验专家对同一层次内两两因素的相对重要性进行打分。专家们要分别对指标层中的各评分标准内部每个因素以及评分标准层中的每个指标进行重要性比较,构造判断矩阵。得出:谁更重要,重要多少,并按重要性程度进行赋值,在赋值时采用1-9标度法。
3.层次单排序的一致性检验
两两比较矩阵的元素是通过两个因素比较得到的,而在很多这样的比较中,可能得到一些不一致性的结论。例如当因素A、B、C的重要性很接近的时候,在两两比较时,可能得出A比B重要,B比C重要,而C又比A重要等矛盾的结论,这在因素的数目多的时候更容易发生。
原理:判断矩阵A对应于最大特征值λ_max得到特征向量W,经归一化即为同一层次相应元素对于上一层次元素相对重要性的排序权值。
(1)第一步计算一致性指标CI
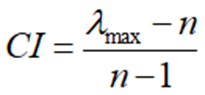
(2)查找平均随机一致性指标RI

(3)计算一性比例CR
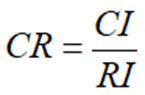
如果CR<0.1,判断矩阵的一致性可以接受,否则需要对判断矩阵进行修正。
4.层次总排序的一致性检验
定义:计算某一层次所有因素对于最高层(总目标)相对重要性的权值,称为层次总排序。这一过程是从最高层次到最低层次依次进行的。
(1)B层的层次总排序:
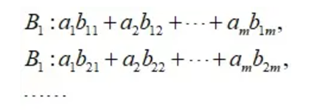
(2)层次总排序的一致性比率:
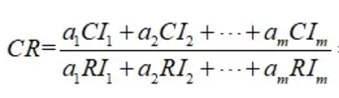
当CR<0.1 时,认为层次总排序通过一致性检验。
▍基于专家评分卡多轮问卷实战建设
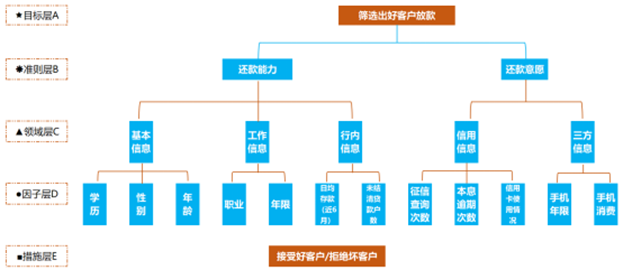
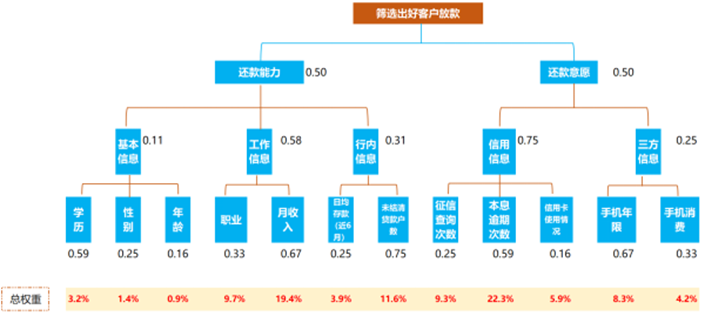
建立风控策略及模型的目标是筛选出好客户进件放款。为达到这一目标,从客户的还款能力和还款意愿两个方面来考虑。还款能力主要看客户的基本信息、工作信息以及行内信息;还款意愿主要看客户的信用信息和三方信息。
1.评分卡指标体系层次结构建立
2.两两比较矩阵构造

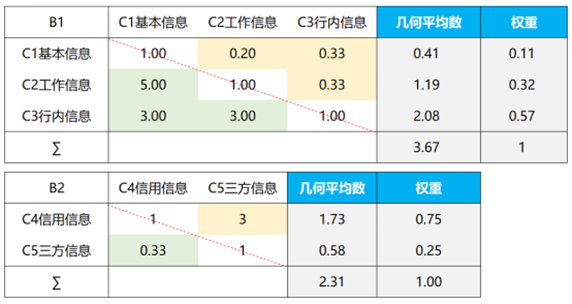
同理,根据因子层D各因素相对重要性对其进行打分,确定因子层D各因素对领域层C的相对重要性的权重,如下表:
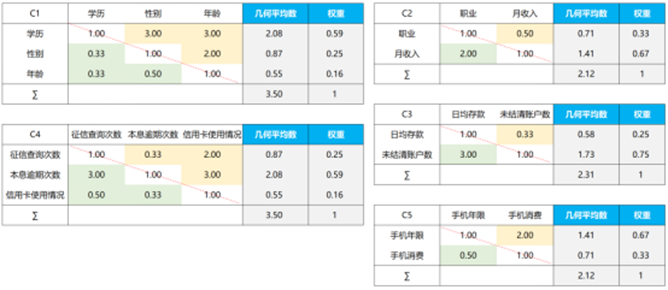
最终得到各个指标权重比例(总权重是每层因子比重的乘积,如:学历的总权重3.2%=0.5*0.11*0.59):
3.一致性检验
以信用信息下层的三个因素(征信查询次数、本息逾期次数、信用卡使用情况)为例:
Step1:由被检验的两两比较矩阵乘以其特征向量,所得的向量称之为赋权和向量
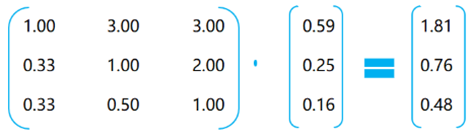
Step2:每个赋权和向量的分量分别除以对应的特征向量的分量
1.81/0.59=3.05
0.76/0.25=3.05
0.48/0.16=3.05
Step3:计算出Step2结果中的平均值,记为λavg
λavg= (3.05+3.05+3.05)/3=3.05
Step4:计算一致性指标CI
CI = (λavg– n ) / (n - 1)
CI = (3.05 – 3 ) / (3 – 1 ) = 0.03
Step5:计算一致性率CR
CR = CI / RI=0.03/0.58=0.05<0.1
即通过一致性检验。
▍基于AHP法挑选高跟鞋python实现
首先我们来设定目标,也就是我们需要解决的问题,如何选购一双最合适的高跟鞋;其次,为了实现这一目标,我们需要考虑的因素包括:款式,颜色,材质,价格和舒适度;最后,可供我们选择的高跟鞋备选方案包括:Jimmy Choo、Christian Louboutin,以及Roger Vivier。做好以上准备,我们建立如下层次结构模型:

Python代码:
import numpy as np
import pandas as pd
import warnings
class AHP:
def __init__(self, criteria, b):
self.RI = (0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49)
self.criteria = criteria
self.b = b
self.num_criteria = criteria.shape[0]
self.num_project = b[0].shape[0]
def cal_weights(self, input_matrix):
input_matrix = np.array(input_matrix)
n, n1 = input_matrix.shape
assert n == n1, '不是一个方阵'
for i in range(n):
for j in range(n):
if np.abs(input_matrix[i, j] * input_matrix[j, i] - 1) > 1e-7:
raise ValueError('不是反互对称矩阵')
eigenvalues, eigenvectors = np.linalg.eig(input_matrix)
max_idx = np.argmax(eigenvalues)
max_eigen = eigenvalues[max_idx].real
eigen = eigenvectors[:, max_idx].real
eigen = eigen / eigen.sum()
if n > 9:
CR = None
warnings.warn('无法判断一致性')
else:
CI = (max_eigen - n) / (n - 1)
CR = CI / self.RI[n]
return max_eigen, CR, eigen
def run(self):
max_eigen, CR, criteria_eigen = self.cal_weights(self.criteria)
print('准则层:最大特征值{:<5f},CR={:<5f},检验{}通过'.format(max_eigen, CR, '' if CR < 0.1 else '不'))
print('准则层权重={}\n'.format(criteria_eigen))
max_eigen_list, CR_list, eigen_list = [], [], []
for i in self.b:
max_eigen, CR, eigen = self.cal_weights(i)
max_eigen_list.append(max_eigen)
CR_list.append(CR)
eigen_list.append(eigen)
pd_print = pd.DataFrame(eigen_list,
index=['准则' + str(i) for i in range(self.num_criteria)],
columns=['方案' + str(i) for i in range(self.num_project)],
)
pd_print.loc[:, '最大特征值'] = max_eigen_list
pd_print.loc[:, 'CR'] = CR_list
pd_print.loc[:, '一致性检验'] = pd_print.loc[:, 'CR'] < 0.1
print('方案层')
print(pd_print)
# 目标层
obj = np.dot(criteria_eigen.reshape(1, -1), np.array(eigen_list))
print('\n目标层', obj)
print('最优选择是方案{}'.format(np.argmax(obj)))
return obj
if __name__ == '__main__':
# 准则重要性矩阵
criteria = np.array([[1, 2, 1 / 4, 1 / 3, 1 / 3],
[1 / 2, 1, 1 / 7, 1 / 5, 1 / 5],
[4, 7, 1, 2, 3],
[3, 5, 1 / 2, 1, 1],
[3, 5, 1 / 3, 1, 1]])
# 对每个准则,方案优劣排序
b1 = np.array([[1, 1 / 2, 1 / 5], [2, 1, 1 / 2], [5, 2, 1]])
b2 = np.array([[1, 3, 8], [1 / 3, 1, 3], [1 / 8, 1 / 3, 1]])
b3 = np.array([[1, 1, 1 / 3], [1, 1, 1 / 3], [3, 3, 1]])
b4 = np.array([[1, 1 / 3, 1 / 4], [3, 1, 1], [4, 1, 1]])
b5 = np.array([[1, 1, 4], [1, 1, 4], [1 / 4, 1 / 4, 1]])
b = [b1, b2, b3, b4, b5]
a = AHP(criteria, b).run()结果:
准则层:最大特征值5.072084,CR=0.014533,检验通过
准则层权重=[0.08530829 0.04704119 0.43099972 0.22540664 0.21124416]
方案层
方案0 方案1 方案2 最大特征值 CR 一致性检验
准则0 0.128271 0.276350 0.595379 3.005535 3.075062e-03 True
准则1 0.681725 0.236341 0.081935 3.001542 8.564584e-04 True
准则2 0.200000 0.200000 0.600000 3.000000 1.233581e-15 True
准则3 0.126005 0.416061 0.457934 3.009203 5.112618e-03 True
准则4 0.444444 0.444444 0.111111 3.000000 -4.934325e-16 True
目标层 [[0.25150036 0.3085618 0.43993784]]
最优选择是方案2参考文献
[1] DR. Richard Hodgett. Decision-Making 2: Pairwise Comparison Methods. Business Analystic and Decisison Science (LUBS5308M). University of Leeds.
[2] 郭金玉,张忠彬,孙庆云. 层次分析法的研究与应用. 中国安全科学学报,2008,18(5):148-153.
[3] 邓雪,李家铭,曾浩健,陈俊羊,赵俊峰. 层次分析法权重计算方法分析及其应用研究[J]. 数学的实践与认识,2012,24(7):93-100.
[4] 常建娥,蒋太立. 层次分析法确定权重的研究[J]. 武汉理工大学学报:信息与管理工程版,2007,29(1):153-156.
[5] CSDN博主「卖山楂啦prss」的原创文章,
原文链接:https://blog.csdn.net/qq_42374697/article/details/105883584.
[6] CSDN博主「guofei9987」的原创文章,
原文链接:https://blog.csdn.net/guofei9987/article/details/103878993















 4171
4171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









