






背景说明
在我们平时开发项目的时候,或多或少会遇到处理票据、身份证、图片文字等情况,这个时候就需要用到图像识别技术来进行文字提取,将其中有用的信息处理出来,为应用提供了更加强大的细节功能。这里介绍一款图像识别领域功能强大的产品,合合信息TextIn。它所提供的接口,能够进行智能图像处理、文字表格识别、文档内容提取。下面我们主要围绕着该产品的图像识别来讲。主要功能就是将图像文字处理成JSON数据,我们利用返回出来的JSON处理业务。
先介绍一下TextIn的强大之处
从下图可以看到的是合合信息TextIn接口能进行处理的方面
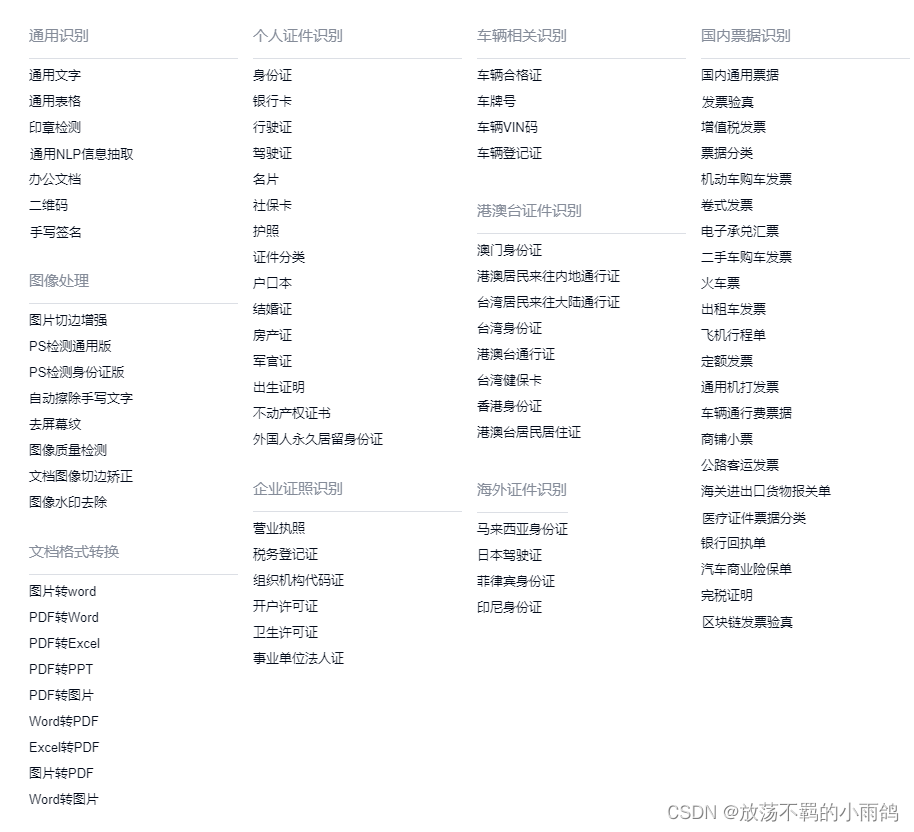
你可以按照你项目的需求进行选择,只需要更改提交查询参数即可进行相应功能API的调用。这样就非常方便,然后就是可以去看TextIn接口文档,上面有详细说明。
如何理解合合信息的接口调用
合合信息TextIn接口调用主要是简单的三个点
- 选用适合的API接口调用方式
- 配置接口调用的
x-ti-app-id和x-ti-secret-code- 根据你需要的接口去看相应的文档,了解其中你所需要配置的请求参数
HTML实现的一个接口调用
1.这里选用的是前端直接处理的方式
<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>服务集成演示</title>
</head>
<body>
<h2>上传文件</h2>
<div>
<input type="file" id="file">
</div>
<script>
document.querySelector('#file').addEventListener('change', function(e) {
var file = e.target.files[0] // 上传文件的 File 对象
var reader = new FileReader()
reader.readAsArrayBuffer(file) // 读取成二进制
reader.onload = function (e) {
var fileData = this.result
var xhr = new XMLHttpRequest()
// --------------------------------------------------------------------
// 特别注意
// --------------------------------------------------------------------
// 在客户端/浏览器端储存 x-ti-app-id 和 x-ti-secret-code 是一件风险极大的事情
// 极易造成 x-ti-app-id 和 x-ti-secret-code 的泄露。
// 非特殊情况,请勿在客户端/浏览器存储 x-ti-app-id 和 x-ti-secret-code
// 本示例代码仅供演示参考,请勿直接用于生产环境。
// 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-app-id
// 示例代码中 x-ti-app-id 非真实数据
var appId = '28c******************************76a'
// 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-secret-code
// 示例代码中 x-ti-secret-code 非真实数据
var secretCode = '616e*****************************e9954f9'
// 通用文字识别 服务URL
var url = 'https://api.textin.com/ai/service/v2/recognize?straighten=0&character=0'
xhr.open('POST', url)
xhr.setRequestHeader('x-ti-app-id', appId)
xhr.setRequestHeader('x-ti-secret-code', secretCode)
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
xhr.onreadystatechange = null
var response = xhr.response
console.log(response);
var obj = {}
try {
obj = JSON.parse(response) // 转化为对象
} catch (e) {
}
if (!obj.result) return
var list = obj.result.item_list
if (!list || !list.length) return
console.log(JSON.stringify(list))
}
}
xhr.send(fileData)
}
})
</script>
</body>
</html>
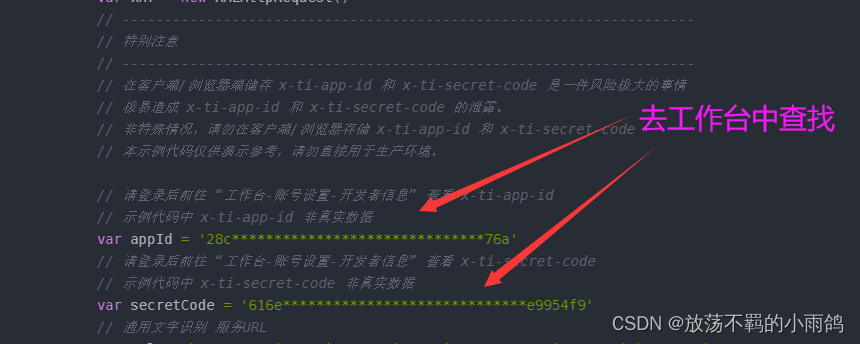
2.配置好自己的信息,注意保证这里私有数据信息的安全性
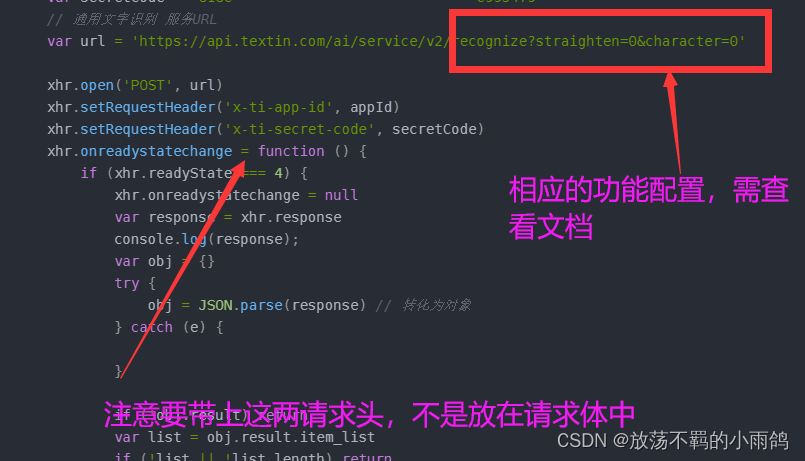
3.按照项目中需要的功能进行选择,查看文档,参数自行配置
实际项目中使用的体验和图像文字识别的准确性
1.直接在前端项目中使用合合信息提供的API
在前端项目开发阶段,为了测试项目的功能流程,可以直接使用合合信息TextIn提供的图像识别接口进行调用,不需要经过后端,由于没有后端进行处理,前端按照API接口返回的JSON格式进行获取数据,基本上,只要规范好了请求所带的参数,封装好的函数能一直进行调用,很少会出现问题。
- 只需关注我们实际项目的业务
前端进行开发的时候有些功能模块上不需要经过项目后端处理,合合信息API的安全性和数据格式也提供完善了,我们只需在相应的功能模块上关注自己的业务逻辑就行了,无需考虑很多。比如在发布职位平台上BOSS需要提供企业认证,基本上的识别要求是需要扫描一些,将一些相关的信息辅助用户进行填充。
3.调用过程的优化方案
项目中有关于一组数据信息,能给用户提供不同文件格式的文件。为了解决网站大量的重复调用合合信息API接口,导致不必要的开销,我们会想到将信息数据放在后端进行处理。这个时候前端将收集好的数据信息传给后端,后端需要来调用合合信息API图像文件转化的API,我们需要将转换后的文件存储在后端,下次用户请求不同格式的文件时,不需要将数据再次通过合合信息API接口调用,直接从我们的后端存储的资源位置获取就行。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









