







问题阐述:
Traceback (most recent call last):
File "D:\conda2023\SimCLRv3\trainstage1.1.py", line 105, in <module> train(args)
File "D:\conda2023\SimCLRv3\trainstage1.1.py", line 68, in train _, pre_L = model(imgL)
File "D:\conda2023\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl return forward_call(*args, **kwargs)
File "D:\conda2023\SimCLRv3\net.py", line 34, in forward x = self.f(x)
File "D:\conda2023\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl return forward_call(*args, **kwargs)
File "D:\conda2023\lib\site-packages\torch\nn\modules\container.py", line 217, in forward input = module(input)
File "D:\conda2023\lib\site-packages\torch\nn\modules\module.py", line 1538, in _call_impl result = forward_call(*args, **kwargs)
File "D:\conda2023\lib\site-packages\torch\nn\modules\normalization.py", line 273, in forward return F.group_norm(
File "D:\conda2023\lib\site-packages\torch\nn\functional.py", line 2530, in group_norm return torch.group_norm(input, num_groups, weight, bias, eps, torch.backends.cudnn.enabled)
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument weight in method wrapper_CUDA__native_group_norm)
原因分析:
weight(或其他任何参数)不在与输入张量input相同的设备上。
可以在函数开始时将其移动到相同的设备上。这样可以确保所有的张量都在同一设备上,从而避免设备不匹配的问题。
解决方案:
找到\Lib\site-packages\torch\nn\functional.py中的group_norm函数:
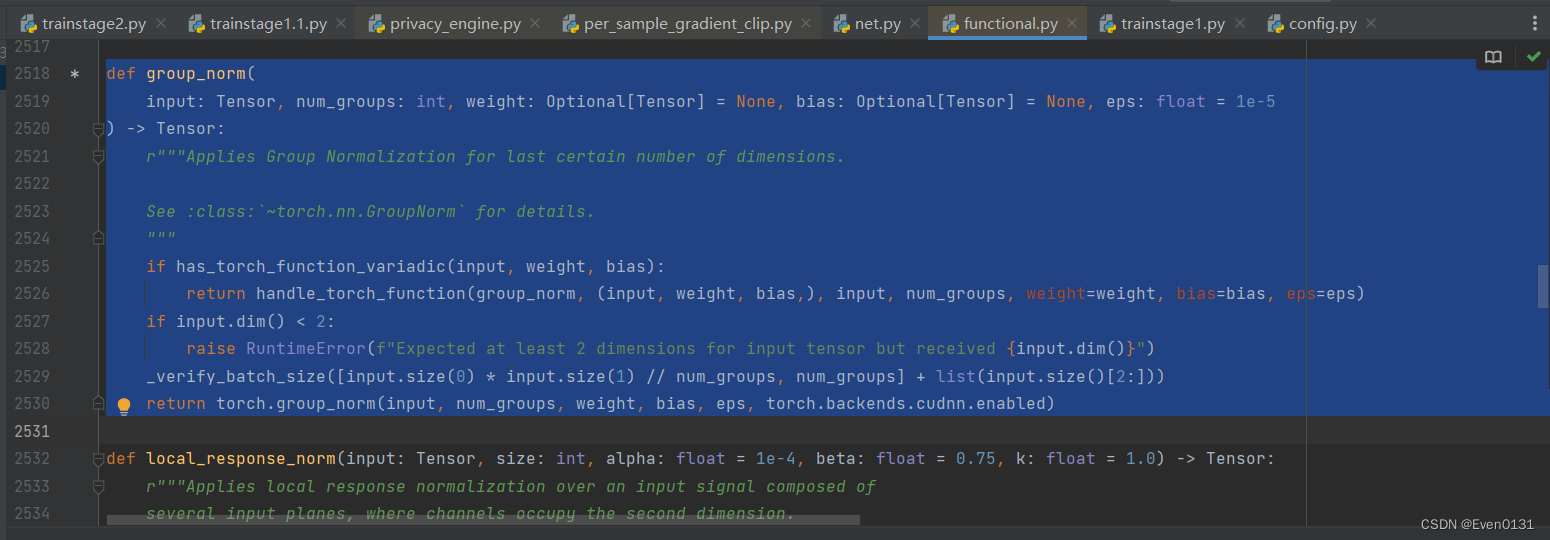
修改为:
def group_norm(
input: torch.Tensor, num_groups: int, weight: Optional[torch.Tensor] = None,
bias: Optional[torch.Tensor] = None, eps: float = 1e-5
) -> torch.Tensor:
r"""Applies Group Normalization for last certain number of dimensions.
See :class:`~torch.nn.GroupNorm` for details.
"""
# 获取输入张量的设备
device = input.device
# 将权重和偏置移动到与输入相同的设备上
if weight is not None:
weight = weight.to(device)
if bias is not None:
bias = bias.to(device)
if has_torch_function_variadic(input, weight, bias):
return handle_torch_function(group_norm, (input, weight, bias,), input, num_groups, weight=weight, bias=bias, eps=eps)
if input.dim() < 2:
raise RuntimeError(f"Expected at least 2 dimensions for input tensor but received {input.dim()}")
_verify_batch_size([input.size(0) * input.size(1) // num_groups, num_groups] + list(input.size()[2:]))
return torch.group_norm(input, num_groups, weight, bias, eps, torch.backends.cudnn.enabled)
这样,无论weight和bias最初在哪个设备上,它们都会被移动到与输入张量input相同的设备上。
(这个小问题困扰了我半天,改了无数次网络和训练函数的代码,始终出现这个错误,刚开始一直以为是张量没有move到GPU上,所以给所有的模型和张量都添加了.to(DEVICE)。后来分析得到应该是torch内置函数的问题。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









