







一.异常值识别
异常值: 指的是样本中的一些数值明显偏离其余数值的样本点,所以也称为离群值,常见分类:
(1)数据有一个指定范围:
例如调查问卷中,需要对某个事物进行打分,满分为0-10分。如果填问卷的人填了一个30分,那么这个数据就是异常值。
这种情况比较简单,我们可以使用MATLAB的逻辑运算快速的找到这些异常值:
x = [8 9 10 7 6 3 30 4 13 9 2];
ind = find(x<0 | x>10)
x(ind) % 也可以直接使用x(x<0 | x>10)
(2) 数据没有给定的范围:
这种情况下我们介绍两种最常用的判定方法:
第一:3σ原则识别异常值
注意事项:使用3σ原则要求数据服从正态分布或近似服从正态分布
x = [48 51 57 57 49 86 48 53 59 50 48 47 53 56 60]; % 假设x是取自正态分布的样本
u = mean(x,'omitnan'); % 忽略数据中的缺失值计算均值
sigma = std(x,'omitnan'); % 计算标准差 std(x,0,'omitnan')是总体标准差
lb = u - 3*sigma % 区间下界,low bound的缩写
ub = u + 3*sigma % 区间上界,upper bound的缩写
tmp = (x < lb) | (x > ub);
ind = find(tmp)
返回6,意味着第6个位置是异常值
第二:箱形图识别异常值
和3σ原则相比,箱形图并没有对数据服从的分布作任何限制性要求,其判断异常值的标准主要以四分位数和四分位距为基础。在总体分布未知的情况下,使用箱形图识别异常值的结果更加客观。
箱型图画法:(使用Excel)
在插入中选择推荐的图表,选择所有图形,选择箱形图

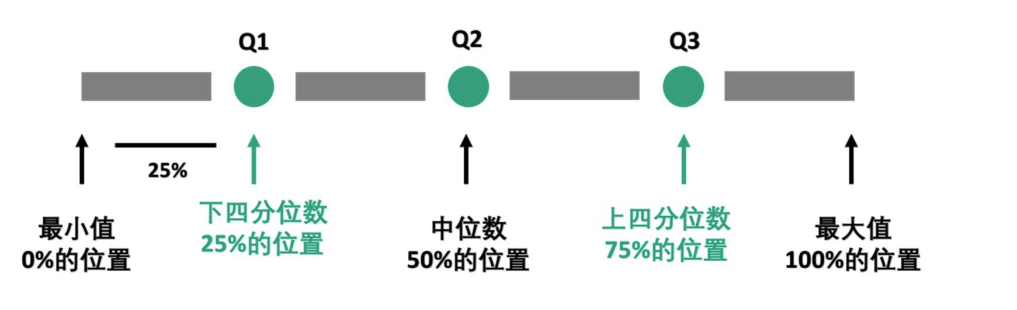
IQR:称为四分位距指标
IQR=Q3-Q1。四分位距反映了中间 50%数据的离散程度,其数值越小,说明中间的数据越集中;其数值越大,说明中间的数据越分散。
接下来跟3σ识别原则类似,我们需要给出一个合理的区间,位于该区间内的值是正常的数值,而在区间外的值就是我们定义异常值。在箱线图中,该区间一般为[Q1 − k × IQR, Q3 + k × IQR], k是控制区间长度的一个正数,通常k取为 1.5。因此,我们只需要判断这组数据中的每个值是否都位于[Q1 −1.5 × IQR, Q3 + 1.5 × IQR]这个区间内,如果不在这个区间内就标记为异常值。
另外,如果我们将k取为 3,在这个区间外的异常值被称为极端异常值。
x = [48 51 57 57 49 86 48 53 59 50 48 47 53 56 60];
% 计算分位数的函数需要MATLAB安装了统计机器学习工具箱
Q1 = prctile(x,25); % 下四分位数
Q3 = prctile(x,75); % 上四分位数
IQR = Q3-Q1; % 四分位距
lb = Q1 - 1.5*IQR % 下界
ub = Q3 + 1.5*IQR % 上界
tmp = (x < lb) | (x > ub);
ind = find(tmp)
识别出异常值后,我们通常可以将异常值视为缺失值,然后交给缺失值处理方法来处理。
x(ind) = nan
二.缺失值处理
1.缺失值处理
如何处理数据的缺失值是一门很深的学问,事实上数据缺失在许多研究领域都是一个复杂的问题。下面我们介绍的只是一些比较简单的处理方法。
MATLAB中计算缺失值数量的函数非常简单,我们可以使用ismissing函数和sum函数,下面举个例子:
A = [3 NaN 5 6 7 NaN NaN 9]; % nan也可以写成NaN
TF = ismissing(A)
% TF = 1x8 的逻辑数组(为1的位置表示是缺失值)
sum(TF)
对TF向量求和,结果为3,代表有3个缺失值
另外,ismissing函数也可以对矩阵或者表格数据类型判断缺失值,有兴趣的同学可以查询MATLAB官网。
链接: https://www.mathworks.cn/help/matlab/ref/ismissing.html
B = [1 2 5;
nan 0 8;
nan 1 nan;
3 5 nan;
nan nan nan];
TF = ismissing(B)
sum(TF,1) % 计算每一列的和
sum(TF,2) % 计算每一行的和
2.缺失值填补
下面我们再来介绍缺失值填补,我们需要对缺失的数据类型进行区分:横截面数据和时间序列数据。这两种数据的缺失值处理方法有所不同。
横截面数据是指在某一时点收集的不同对象的数据,例如北京、上海、广州、深圳等 30个城市今天的最高气温;时间序列数据是指对同一对象在不同时间连续观察所取得的数据,例如北京今年来每天的最高气温。
对于横截面数据,我们通常使用某个具体的数值来代替缺失值,例如非缺失数据的平均值、中位数或者众数。
A = [2 3 nan 3 nan nan 8 4];
v = mean(A,'omitnan'); % 平均值
% v = median(A,'omitnan'); % 中位数
% v = mode(A); % 众数,常用于离散变量的缺失值
F = fillmissing(A,'constant',v)
对于数据序列数据,我们通常有下面几种策略:

A = [10 12 16 23 nan 49 68];
F1 = fillmissing(A, 'previous')
F2 = fillmissing(A, 'next')
F3 = fillmissing(A, 'nearest') % 距离同样近时选择右侧的
F4 = fillmissing(A, 'linear')
F5 = fillmissing(A, 'spline')
当然,我们这里介绍的方法比较简单,如果你专门做数据挖掘,还可以使用一些其他的方法来填补缺失值,例如 KNN 填补、随机森林填补、多重插补等方法。
引用自清风课程















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









