






0 项目背景
在之前的关键点检测系列项目中,我们先后通过PaddleHub直接调用、转换为MPII格式重新训练,实现了手部关键点检测模型训练、推理和部署。
但是前作PaddleDetection:手部关键点检测模型训练与Top-Down联合部署其实还遗留了一个比较大的问题,即它是把数据集转换为MPII格式训练的。在文中也指出,由于没有转换.mat格式标注,这种方式验证集只能直接导出评估结果,无法进行评估,既会导致读者对训练结果“抓瞎”,也很容易出现过拟合。
其实,自定义关键点检测模型训练时,主流的数据格式还是COCO。比如在PaddleDetection提供的关键点检测模型库中,超过90%都是基于COCO格式训练和评估的。为了有效地利用起这些预训练模型,在本项目中,我们就尝试将手部关键点数据集转换为COCO,并使用针对移动端设备优化的实时关键点检测模型PP-TinyPose,为更加流畅地在移动端设备上实现关键点检测任务做好准备。
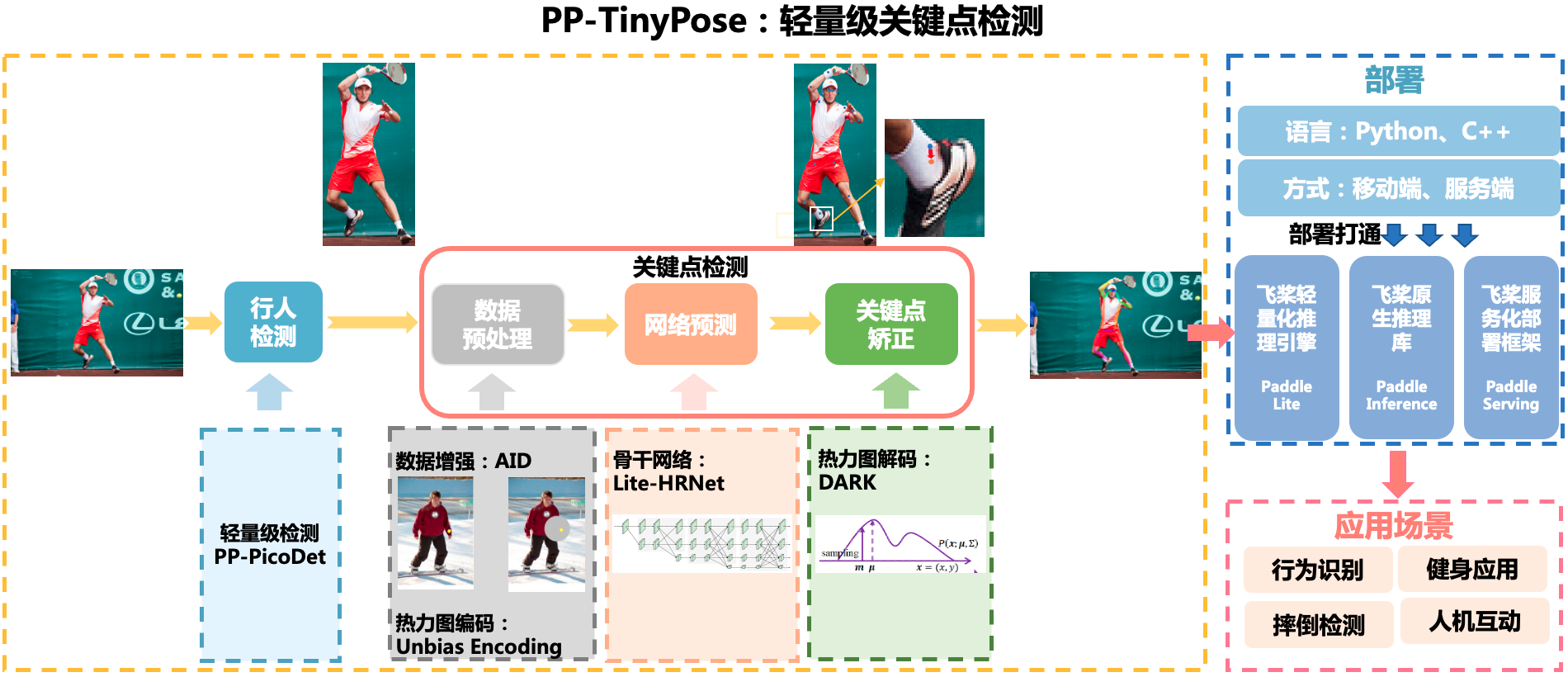
与PicoDet-S手部目标检测联合部署后效果如下:

0.1 参考资料:点读全系列
- 【PaddlePaddle+OpenVINO】AI“朗读机”诞生记
- 【PaddlePaddle+OpenVINO】电表检测识别模型的部署
- 【PaddlePaddle+OpenVINO】打造一个指哪读哪的AI“点读机”
- 手把手教你快速打造一个AI识物点读机
- PaddleSpeech:基于流式语音合成的电表点读系统
- PaddleDetection:手部关键点检测模型训练与Top-Down联合部署
- 【AI达人创造营三期】手势识别“框啥读啥”——AI点读机再升级
# 拉取PaddleDetection
!git clone https://gitee.com/paddlepaddle/PaddleDetection.git
# 拉取原手势识别项目(查看标注文件)
# !git clone https://gitcode.net/EricLee/handpose_x.git
1 数据集准备
1.1 手部关键点检测数据集介绍
本项目使用的数据集来自于Eric.Lee的:https://gitcode.net/EricLee/handpose_x 项目。作者制作的handpose_datasets_v2在兼容handpose_datasets_v1数据集的基础上,增加了左右手属性"handType": “Left” or “Right”。handpose_datasets_v2数据总量为 38w+。
注:
handpose_datasets_v1数据集包括网络图片及数据集<<Large-scale Multiview 3D Hand Pose Dataset>>筛选动作重复度低的部分图片,进行制作(如有侵权请联系删除),共49062个样本。
<<Large-scale Multiview 3D Hand Pose Dataset>>数据集,其官网地址 http://www.rovit.ua.es/dataset/mhpdataset/
感谢《Large-scale Multiview 3D Hand Pose Dataset》数据集贡献者:Francisco Gomez-Donoso, Sergio Orts-Escolano, and Miguel Cazorla. “Large-scale Multiview 3D Hand Pose Dataset”. ArXiv e-prints 1707.03742, July 2017.
具体标注关键点可视化效果如下:
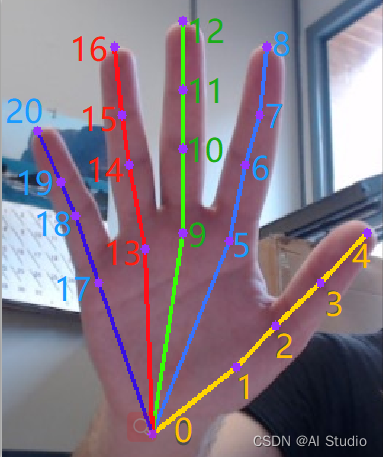
手部关键点检测数据集的标注格式是一张图对应一个标注文件,我们先抽取其中一张图片的标注,看看具体内容:
{
"maker": "Eric.Lee",
"date": "2022-04",
"info": [
{
"handType": "Left",
"bbox": [
0,
0,
0,
0
],
"pts": {
"0": {
"x": 132,
"y": 123
},
"1": {
"x": 122,
"y": 99
},
"2": {
"x": 107,
"y": 83
},
"3": {
"x": 93,
"y": 76
},
"4": {
"x": 77,
"y": 74
},
"5": {
"x": 103,
"y": 72
},
"6": {
"x": 81,
"y": 55
},
"7": {
"x": 69,
"y": 45
},
"8": {
"x": 56,
"y": 34
},
"9": {
"x": 98,
"y": 78
},
"10": {
"x": 72,
"y": 60
},
"11": {
"x": 57,
"y": 49
},
"12": {
"x": 42,
"y": 38
},
"13": {
"x": 93,
"y": 87
},
"14": {
"x": 66,
"y": 72
},
"15": {
"x": 51,
"y": 64
},
"16": {
"x": 36,
"y": 53
},
"17": {
"x": 88,
"y": 100
},
"18": {
"x": 66,
"y": 95
},
"19": {
"x": 52,
"y": 92
},
"20": {
"x": 36,
"y": 90
}
}
}
]
}
1.2 COCO数据集关键点检测标注格式
在COCO数据集中,要参照的标注格式是person_keypoints_train2017.json:

其中info, licenses,categories全局通用, images跟annotations放着图片跟label信息,用image id匹配。
也就是说,我们要进行数据集格式转换的目标如下:
{
"categories": [
{
"skeleton": [
[16,14],
[14,12],
[17, 5],
[15,13],
[12,13],
[6 ,12],
[7 ,13],
[6 , 7],
[6 , 8],
[7 , 9],
[8 ,10],
[9 ,11],
[2 , 3],
[1 , 2],
[1 , 3],
[2 , 4],
[3 , 5],
[4 , 6],
[5 , 7]
],
"name": "person", # 子类(具体类别)
"supercategory": "person", # 主类
"id": 1, # class id
"keypoints": [
"nose",
"left_eye",
"right_eye",
"left_ear",
"right_ear",
"left_shoulder",
"right_shoulder",
"left_elbow",
"right_elbow",
"left_wrist",
"right_wrist",
"left_hip",
"right_hip",
"left_knee",
"right_knee",
"left_ankle",
"right_ankle"
]
}
],
"licenses": [
{
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License",
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/"
},
{
"id": 2,
"name": "Attribution-NonCommercial License",
"url": "http://creativecommons.org/licenses/by-nc/2.0/"
},
{
"id": 3,
"name": "Attribution-NonCommercial-NoDerivs License",
"url": "http://creativecommons.org/licenses/by-nc-nd/2.0/"
},
{
"id": 4,
"name": "Attribution License",
"url": "http://creativecommons.org/licenses/by/2.0/"
},
{
"id": 5,
"name": "Attribution-ShareAlike License",
"url": "http://creativecommons.org/licenses/by-sa/2.0/"
},
{
"id": 6,
"name": "Attribution-NoDerivs License",
"url": "http://creativecommons.org/licenses/by-nd/2.0/"
},
{
"id": 7,
"name": "No known copyright restrictions",
"url": "http://flickr.com/commons/usage/"
},
{
"id": 8,
"name": "United States Government Work",
"url": "http://www.usa.gov/copyright.shtml"
}
],
"annotations": [
{
"iscrowd": 0,
"bbox": [
339.88, 22.16, 153.88, 300.73 # [x,y,w,h] 对象定位框
],
"image_id": 391895, # match the images: "id"
"segmentation": [
[
352.55, 146.82, # 多边形(对象mask)第一个点 x,y, 如果对象被遮挡,对象被分成多个区域
353.61, 137.66,
356.07, 112.66,
......
353.61, 152.25,
353.26, 149.43
],
[
450.45, 196.54,
461.71, 195.13,
466.29, 209.22,
......
449.04, 229.57,
448.33, 199.29
]
],
"num_keypoints": 14,
"id": 202758,
"category_id": 1,
"keypoints": [
# 如果关键点在物体segment内,则认为可见.
# v=0 表示这个关键点没有标注(这种情况下x=y=v=0)
# v=1 表示这个关键点标注了但是不可见(被遮挡了)
# v=2 表示这个关键点标注了同时也可见
368, 61, 1,
369, 52, 2,
0, 0, 0,
382, 48, 2,
0, 0, 0,
368, 84, 2,
435, 81, 2,
362, 125, 2,
446, 125, 2,
360, 153, 2,
0, 0, 0,
397, 167, 1,
439, 166, 1,
369, 193, 2,
461, 234, 2,
361, 246, 2,
474, 287, 2
],
"area": 14107.2713
},
{
"iscrowd": 0,
"bbox": [
471.64,
172.82,
35.92,
48.1
],
"image_id": 391895,
"segmentation": [
[
477.41, 217.71,
475.06, 212.15,
......
478.27, 218.57
]
],
"num_keypoints": 0,
"id": 1260346,
"category_id": 1,
"keypoints": [
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0,
0,0,0
],
"area": 708.26055
}
],
"images": [
{
"id": 391895, # match the annotations: "image_id"
"date_captured": "2013-11-14 11:18:45",
"coco_url": "http://images.cocodataset.org/val2014/COCO_val2014_000000391895.jpg",
"height": 360,
"flickr_url": "http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg",
"file_name": "COCO_val2014_000000391895.jpg",
"license": 3,
"width": 640
}
],
"info": {
"version": "1.0",
"description": "COCO 2014 Dataset",
"year": 2014,
"contributor": "COCO Consortium",
"url": "http://cocodataset.org",
"date_created": "2017/09/01"
}
}
其实,从上面的分析也可以看出,转换时所用到的字段跟MPII其实也差不多。因此,我们基于前一个项目PaddleDetection:手部关键点检测模型训练与Top-Down联合部署开发的数据转换代码,在很大程度上还是可以复用的。
1.3 手部关键点检测数据格式对齐COCO数据集
# 解压手势关键点检测数据集
!unzip data/data162171/handpose_datasets_v2-2022-04-16.zip -d ./data/
# 统计图片和标注文件数量(1:1)
!ls ./data/handpose_datasets_v2| wc -l
770122
# 调用一些需要的第三方库
import numpy as np
import pandas as pd
import shutil
import json
import os
import cv2
import glob
import matplotlib.pyplot as plt
import seaborn as sns
from PIL import Image
import random
# 准备图片目录
%mkdir ./data/handpose_datasets
在本项目中,我们不再对左右手的关键点进行区分,而是将他们视为相同的关键点进行训练。因此数据标注文件中,关键点共21个。
# 定义关键点类别信息
categories = [
{
"skeleton": [
[0 ,1],
[1 ,2],
[2 ,3],
[3 ,4],
[0 ,5],
[5 ,6],
[6 ,7],
[7 ,8],
[0 ,9],
[9 ,10],
[10 ,11],
[11 ,12],
[0 ,13],
[13 ,14],
[14 ,15],
[15 ,16],
[0 ,17],
[17 ,18],
[18 ,19],
[19, 20]
],
"name": "hand", # 子类(具体类别)
"supercategory": "hand", # 主类
"id": 1,
"keypoints": [
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9",
"10",
"11",
"12",
"13",
"14",
"15",
"16",
"17",
"18",
"19",
"20"
]
}
]
path = "./data/handpose_datasets_v2/"
path2 = "./data/handpose_datasets/"
train_json = []
val_json = []
num = 0
image_train = []
annotation_train = []
image_val = []
annotation_val = []
# 遍历标注图片
for img_id , f_ in enumerate(os.listdir(path)):
if ".jpg" in f_:
# 获取图片路径
img_path = path + f_
# 获取标签路径
label_path = img_path.replace('.jpg','.json')
image_id = img_id
img = Image.open(img_path)
width = img.width
height = img.height
if not os.path.exists(label_path):
continue
# 获取标注信息
with open(label_path, encoding='utf-8') as f:
hand_dict_ = json.load(f)
f.close()
hand_dict_ = hand_dict_["info"]
# 初始化检测框坐标
x_max = -65535
y_max = -65535
x_min = 65535
y_min = 65535
# 初始化关键点信息
# "keypoints" : [x1,y1,v1,...], 关键点坐标,其中V字段表示关键点属性,0表示未标注,1表示已标注但不可见,2表示已标注且可见
keypoints = []
if len(hand_dict_) > 0:
for msg in hand_dict_:
# 标注检测框坐标
bbox = msg["bbox"]
# 手势关键点坐标
pts = msg["pts"]
# 左手右手标注
handType = msg["handType"]
# 找到外接矩形
x1,y1,x2,y2 = int(bbox[0]),int(bbox[1]),int(bbox[2]),int(bbox[3])
# 遍历关键点坐标
for i in range(21):
x_,y_ = pts[str(i)]["x"],pts[str(i)]["y"]
x_ += x1
y_ += y1
# "keypoints" : [x1,y1,v1,...], 关键点坐标,其中V字段表示关键点属性,0表示未标注,1表示已标注但不可见,2表示已标注且可见
# 由于可见与否相当于需要再一次标注,本项目为节省时间,直接设置为已标注且可见:如果读者需要更好的检测效果,可以对标注进行再次矫正
keypoints.append([x_ ,y_, 2])
x_min = x_ if x_min > x_ else x_min
y_min = y_ if y_min > y_ else y_min
x_max = x_ if x_max < x_ else x_max
y_max = y_ if y_max < y_ else y_max
area = float((x_max - x_min) * (y_max - y_min))
num_keypoint = 21
# 准备COCO数据集中image和annotation字典段内容
image_dict = {
"id" : image_id, # 图像id,可从0开始
"width" : width, # 图像的宽
"height" : height, # 图像的高
"file_name" : f_ # 文件名
}
annotation_dict = {
"id" : num, # 注释id编号
"image_id" : image_id, # 图像id编号
"segmentation" : [], # 分割具体数据
"area" : area, # 目标检测的区域大小
"bbox" : [x_min, y_min, int(x_max - x_min), int(y_max - y_min)], # 目标检测框的坐标详细位置信息
"iscrowd" : 0,
"num_keypoints": num_keypoint,
"keypoints": [k for s in keypoints for k in s],
"category_id": 1
}
# 移动图片
shutil.copy(img_path, path2 + f_)
# 划分训练集和测试集
if num % 5 == 0:
image_val.append(image_dict)
annotation_val.append(annotation_dict)
else:
image_train.append(image_dict)
annotation_train.append(annotation_dict)
num += 1
# 准备训练集标注数据
item_train = {
"info" : {"version": "1.0", "description":"handpose keypoint dataset"}, # 数据集描述信息
"images" : image_train, # 图像字典段列表信息
"annotations" : annotation_train, # 注释类型字典段列表
"categories" : categories,
"licenses" : [] # 许可协议字典段列表
}
train_json.append(item_train)
# 准备验证集标注数据
item_val = {
"info" : {"version": "1.0", "description":"handpose keypoint dataset"}, # 数据集描述信息
"images" : image_val, # 图像字典段列表信息
"annotations" : annotation_val, # 注释类型字典段列表
"categories" : categories,
"licenses" : [] # 许可协议字典段列表
}
val_json.append(item_val)
# 创建训练集标签
with open("./train_json.json","w") as f:
json.dump(train_json[0],f)
# 创建测试集标签
with open("./val_json.json","w") as f:
json.dump(val_json[0],f)
2 模型训练
2.1 tinypose自定义数据集训练
关键点检测的config文件主要需要关注下面这几个配置项:
num_joints: &num_joints 21 #自定义数据的关键点数量
train_height: &train_height 256 #训练图片尺寸-高度h
train_width: &train_width 192 #训练图片尺寸-宽度w
hmsize: &hmsize [48, 64] #对应训练尺寸的输出尺寸,这里是输入[w,h]的1/4
flip_perm: &flip_perm [] #关键点定义中左右对称的关键点,用于flip增强。若没有对称结构在 TrainReader 的 RandomFlipHalfBodyTransform 一栏中 flip_pairs 后面加一行 "flip: False"(注意缩紧对齐)
num_joints_half_body: 0 #半身关键点数量,用于半身增强
prob_half_body: 0.3 #半身增强实现概率,若不需要则修改为0
upper_body_ids: [0] #上半身对应关键点id,用于半身增强中获取上半身对应的关键点。
因为是手部关键点检测,其实并不需要用到半身检测相关的内容.最终处理的配置内容可参考项目提供的tinypose_256x192.yml文件。
另一个需要注意的地方是,要实现边训练边验证,还有一些代码上的修改——因为源码还是按照COCO数据集17个人体关键点去写的。
- keypoint_utils.py中的sigmas = np.array([.26, .25, .25, .35, .35, .79, .79, .72, .72, .62, .62, 1.07, 1.07,.87, .87, .89, .89]) / 10.0,表示每个关键点的确定范围方差,根据实际关键点可信区域设置,区域精确的一般0.25-0.5,例如眼睛。区域范围大的一般0.5-1.0,例如肩膀。若不确定建议0.75。
在本项目中,PaddleDetection的ppdet/modeling/keypoint_utils.py的219行修改为:
sigmas = np.array([
.75, .75, .75, .75, .75, .75, .75, .75, .75, .75, .75, .75, .75,
.75, .75, .75, .75, .75, .75, .75, .75
]) / 10.
- pycocotools工具中的sigmas,同第一个keypoint_utils.py中的设置。用于coco指标评估时计算。
这里有个比较麻烦的地方,就是pycocotools工具是用pip安装的,修改源码的地方没那么好找。
本文提供了基于AI Studio的修改路径,如果是在读者自己的机子上,可以考虑在第1个epoch保存后立即测试,然后找到pycocotools源码报错位置进行修改。
具体要修改的地方在cocoeval.py的第523行:
self.kpt_oks_sigmas = np.array([.75, .75, .75, .75, .75, .75, .75, .75, .75, .75, .75, .75, .75,
.75, .75, .75, .75, .75, .75, .75, .75])/10.0
# 覆盖配置文件
!cp tinypose_256x192.yml PaddleDetection/configs/keypoint/tiny_pose/tinypose_256x192.yml
%cd PaddleDetection/
/home/aistudio/PaddleDetection
# 安装依赖库
!pip install -r ../requirements.txt
# 修改pycocotools源码
!cp ../cocoeval.py /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/pycocotools/cocoeval.py
# 修改PaddleDetection源码
!cp ../keypoint_utils.py ppdet/modeling/keypoint_utils.py
由于训练时间较长,建议读者可以使用AI Studio提供的后台任务进行训练。
!python tools/train.py -c configs/keypoint/tiny_pose/tinypose_256x192.yml --use_vdl=True --eval
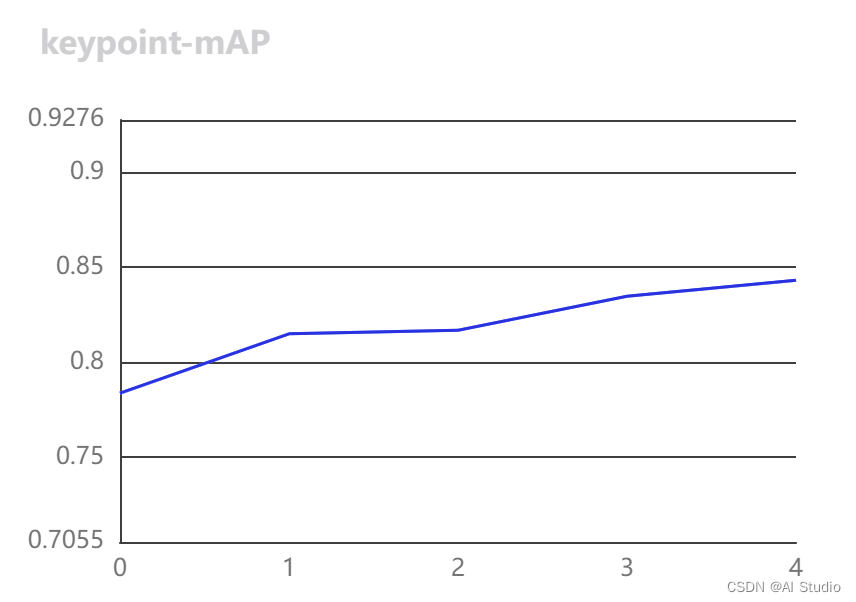
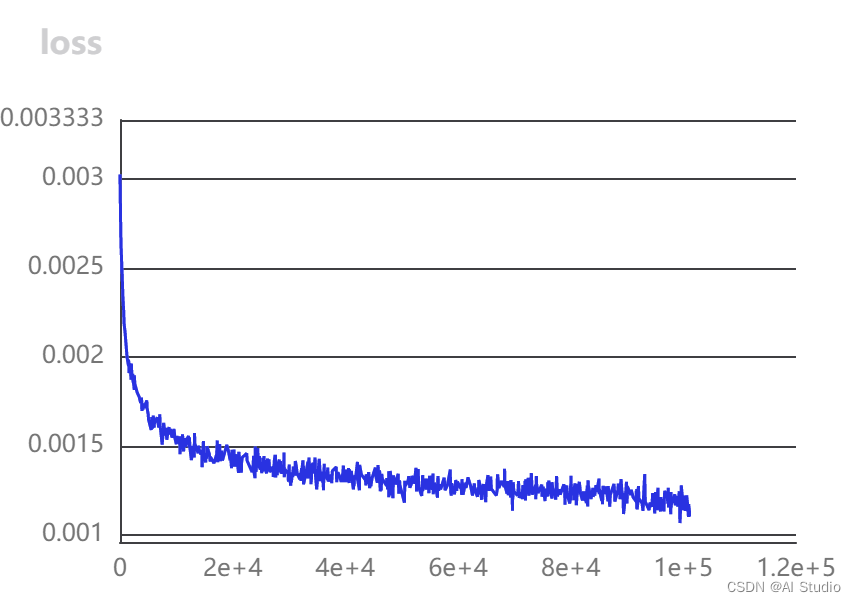
2.2 验证集评估结果导出
在完成1个epoch的训练后,我们可以查看下评估结果:
!python tools/eval.py -c configs/keypoint/tiny_pose/tinypose_256x192.yml -o weights=output/tinypose_256x192/best_model.pdparams
Warning: Unable to use OC-SORT, please install filterpy, for example: `pip install filterpy`, see https://github.com/rlabbe/filterpy
Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly
W1008 20:23:12.443706 28888 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1008 20:23:12.448221 28888 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
loading annotations into memory...
Done (t=1.31s)
creating index...
index created!
loading annotations into memory...
Done (t=1.38s)
creating index...
index created!
[10/08 20:23:28] ppdet.utils.checkpoint INFO: Finish loading model weights: output/tinypose_256x192/0.pdparams
[10/08 20:23:29] ppdet.engine INFO: Eval iter: 0
[10/08 20:24:01] ppdet.engine INFO: Eval iter: 100
[10/08 20:24:31] ppdet.engine INFO: Eval iter: 200
[10/08 20:25:03] ppdet.engine INFO: Eval iter: 300
[10/08 20:25:33] ppdet.engine INFO: Eval iter: 400
[10/08 20:26:05] ppdet.engine INFO: Eval iter: 500
[10/08 20:26:35] ppdet.engine INFO: Eval iter: 600
[10/08 20:27:05] ppdet.engine INFO: Eval iter: 700
[10/08 20:27:35] ppdet.engine INFO: Eval iter: 800
[10/08 20:28:07] ppdet.engine INFO: Eval iter: 900
[10/08 20:28:37] ppdet.engine INFO: Eval iter: 1000
[10/08 20:29:08] ppdet.engine INFO: Eval iter: 1100
[10/08 20:29:39] ppdet.engine INFO: Eval iter: 1200
[10/08 20:30:09] ppdet.engine INFO: Eval iter: 1300
[10/08 20:30:39] ppdet.engine INFO: Eval iter: 1400
[10/08 20:31:10] ppdet.engine INFO: Eval iter: 1500
[10/08 20:31:40] ppdet.engine INFO: Eval iter: 1600
[10/08 20:32:10] ppdet.engine INFO: Eval iter: 1700
[10/08 20:32:40] ppdet.engine INFO: Eval iter: 1800
[10/08 20:33:10] ppdet.engine INFO: Eval iter: 1900
[10/08 20:33:42] ppdet.engine INFO: Eval iter: 2000
[10/08 20:34:14] ppdet.engine INFO: Eval iter: 2100
[10/08 20:34:44] ppdet.engine INFO: Eval iter: 2200
[10/08 20:35:15] ppdet.engine INFO: Eval iter: 2300
[10/08 20:35:46] ppdet.engine INFO: Eval iter: 2400
[10/08 20:36:16] ppdet.engine INFO: Eval iter: 2500
[10/08 20:36:46] ppdet.engine INFO: Eval iter: 2600
[10/08 20:37:16] ppdet.engine INFO: Eval iter: 2700
[10/08 20:37:47] ppdet.engine INFO: Eval iter: 2800
[10/08 20:38:18] ppdet.engine INFO: Eval iter: 2900
[10/08 20:38:48] ppdet.engine INFO: Eval iter: 3000
[10/08 20:39:20] ppdet.engine INFO: Eval iter: 3100
[10/08 20:39:50] ppdet.engine INFO: Eval iter: 3200
[10/08 20:40:21] ppdet.engine INFO: Eval iter: 3300
[10/08 20:40:51] ppdet.engine INFO: Eval iter: 3400
[10/08 20:41:22] ppdet.engine INFO: Eval iter: 3500
[10/08 20:41:52] ppdet.engine INFO: Eval iter: 3600
[10/08 20:42:23] ppdet.engine INFO: Eval iter: 3700
[10/08 20:42:53] ppdet.engine INFO: Eval iter: 3800
[10/08 20:43:24] ppdet.engine INFO: Eval iter: 3900
[10/08 20:43:55] ppdet.engine INFO: Eval iter: 4000
[10/08 20:44:26] ppdet.engine INFO: Eval iter: 4100
[10/08 20:44:56] ppdet.engine INFO: Eval iter: 4200
[10/08 20:45:28] ppdet.engine INFO: Eval iter: 4300
[10/08 20:45:58] ppdet.engine INFO: Eval iter: 4400
[10/08 20:46:28] ppdet.engine INFO: Eval iter: 4500
[10/08 20:46:57] ppdet.engine INFO: Eval iter: 4600
[10/08 20:47:28] ppdet.engine INFO: Eval iter: 4700
[10/08 20:47:59] ppdet.engine INFO: Eval iter: 4800
[10/08 20:48:21] ppdet.metrics.keypoint_metrics INFO: The keypoint result is saved to output/keypoints_results.json.
Loading and preparing results...
DONE (t=5.54s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *keypoints*
DONE (t=24.73s).
Accumulating evaluation results...
DONE (t=2.33s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.617
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.866
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.656
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.483
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.685
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.656
Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.886
Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.694
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.537
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.721
| AP | Ap .5 | AP .75 | AP (M) | AP (L) | AR | AR .5 | AR .75 | AR (M) | AR (L) |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.617 | 0.866 | 0.656 | 0.483 | 0.685 | 0.656 | 0.886 | 0.694 | 0.537 | 0.721 |
[10/08 20:48:59] ppdet.engine INFO: Total sample number: 77045, averge FPS: 52.210687059441746
完成42个epoch的训练后,在验证集上评估效果如下:
[10/10 02:24:26] ppdet.metrics.keypoint_metrics INFO: The keypoint result is saved to output/keypoints_results.json.
Loading and preparing results...
DONE (t=5.83s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *keypoints*
DONE (t=24.64s).
Accumulating evaluation results...
DONE (t=3.69s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.843
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.957
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.882
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.772
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.883
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.862
Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.965
Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.897
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.794
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.899
| AP | Ap .5 | AP .75 | AP (M) | AP (L) | AR | AR .5 | AR .75 | AR (M) | AR (L) |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.843 | 0.957 | 0.882 | 0.772 | 0.883 | 0.862 | 0.965 | 0.897 | 0.794 | 0.899 |
[10/10 02:25:05] ppdet.engine INFO: Total sample number: 77006, averge FPS: 50.348725469608944
2.3 推理效果可视化
关于MPII格式数据集,PaddleDetection源码的扩展性支持还有待提高,因此要进行推理效果可视化,这里需要对源码可视化文件PaddleDetection/ppdet/utils/visualizer.py进行一些修改,具体就是在draw_pose()函数中,把自定义的手部关键点检测数据集的关键点相邻连接关系配置到EDGES中,然后把颜色索引设置colors扩展到关键点数量+1。
if kpt_nums == 17: #plot coco keypoint
EDGES = [(0, 1), (0, 2), (1, 3), (2, 4), (3, 5), (4, 6), (5, 7), (6, 8),
(7, 9), (8, 10), (5, 11), (6, 12), (11, 13), (12, 14),
(13, 15), (14, 16), (11, 12)]
else: #plot mpii keypoint
EDGES = [(0, 1), (1, 2), (2, 3), (3, 4), (0, 5), (5, 6), (6, 7), (7, 8), (0, 9),
(9, 10), (10, 11), (11, 12), (0, 13), (13, 14), (14, 15), (15, 16), (0, 17),
(17, 18), (18, 19), (19, 20)
]
NUM_EDGES = len(EDGES)
colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
[0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], \
[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
[255, 0, 0]]
项目提供了修改后的visualizer.py文件,运行时覆盖源代码的对应文件即可。
!cp ../visualizer.py ppdet/utils/visualizer.py
!python tools/infer.py -c configs/keypoint/tiny_pose/tinypose_256x192.yml -o weights=./output/tinypose_256x192/best_model.pdparams --infer_img=../data/handpose_datasets_v2/2022-04-15_02-04-51_000019.jpg --draw_threshold=0.2
Warning: Unable to use OC-SORT, please install filterpy, for example: `pip install filterpy`, see https://github.com/rlabbe/filterpy
Warning: import ppdet from source directory without installing, run 'python setup.py install' to install ppdet firstly
W1009 16:33:26.825568 16266 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1009 16:33:26.830075 16266 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[10/09 16:33:29] ppdet.utils.checkpoint INFO: Finish loading model weights: ./output/tinypose_256x192/0.pdparams
[10/09 16:33:29] ppdet.data.source.category WARNING: anno_file 'dataset/coco/keypoint_imagelist.txt' is None or not set or not exist, please recheck TrainDataset/EvalDataset/TestDataset.anno_path, otherwise the default categories will be used by metric_type.
100%|█████████████████████████████████████████████| 1/1 [00:01<00:00, 1.57s/it]
[10/09 16:33:31] ppdet.engine INFO: Detection bbox results save in output/2022-04-15_02-04-51_000019.jpg
从可视化效果中我们可以看出,之前在数据转换时设置全部已标注且可见其实还是有一些问题的,当然,关键点检测结果整体还是不错的——这还仅仅是1个epoch的效果。

3 模型部署准备
3.1 部署模型导出
!python tools/export_model.py -c configs/keypoint/tiny_pose/tinypose_256x192.yml --output_dir=output_inference -o weights=output/tinypose_256x192/best_model
3.2 联合部署效果
本项目直接使用前作PaddleDetection:手部关键点检测模型训练与Top-Down联合部署提供的picodet_s_320_voc训练30个epoch后的导出部署模型进行联合部署。
!unzip ../picodet_s_320_voc.zip -d output_inference
Archive: ../picodet_s_320_voc.zip
inflating: output_inference/picodet_s_320_voc/model.pdiparams.info
inflating: output_inference/picodet_s_320_voc/model.pdmodel
inflating: output_inference/picodet_s_320_voc/model.pdiparams
inflating: output_inference/picodet_s_320_voc/infer_cfg.yml
# 部署模型也要修改关键点数量和连接关系
!cp ../deploy_visualize.py deploy/python/visualize.py
# 替换主体检测模型后的detector检测 + keypoint top-down模型联合部署(联合推理只支持top-down方式)
!python deploy/python/det_keypoint_unite_infer.py --det_model_dir=output_inference/picodet_s_320_voc/ --keypoint_model_dir=output_inference/tinypose_256x192/ --video_file=../20-11-32_Trim.mp4 --device=gpu --det_threshold=0.4
from IPython.display import Video
# 联合部署效果展示
Video('output/20-11-32_Trim.mp4')
3.3 Lite部署模型转换
!pip install paddlelite
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddlelite
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/8b/d7/8babc059bff1d02dc85e32fb8bff3c56680db5f5b20246467f9fcbcfe62c/paddlelite-2.11-cp37-cp37m-manylinux1_x86_64.whl (47.1 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m47.1/47.1 MB[0m [31m2.3 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hInstalling collected packages: paddlelite
Successfully installed paddlelite-2.11
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.2.2[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
# fp32
!paddle_lite_opt --model_dir=output_inference/tinypose_256x192 --valid_targets=arm --optimize_out=tinypose_256x192_fp32
Loading topology data from outut_inference/tinypose_256x192/model.pdmodel
Loading params data from outut_inference/tinypose_256x192/model.pdiparams
1. Model is successfully loaded!
2. Model is optimized and saved into tinypose_256x192_fp32.nb successfully
# fp16
!paddle_lite_opt --model_dir=output_inference/tinypose_256x192 --valid_targets=arm --optimize_out=tinypose_256x192_fp32 --enable_fp16=true
Loading topology data from outut_inference/tinypose_256x192/model.pdmodel
Loading params data from outut_inference/tinypose_256x192/model.pdiparams
1. Model is successfully loaded!
2. Model is optimized and saved into tinypose_256x192_fp32.nb successfully
4 小结
在本项目中,我们实现了自定义关键点检测数据集转换为COCO格式后的训练、评估、测试和部署,解决了此前
PaddleDetection:手部关键点检测模型训练与Top-Down联合部署项目遗留下的、不能进行验证集评估的问题。
同时,也完成了基于PP-TinyPose的轻量级关键点检测模型训练。后续,我们将基于该模型,进一步提升“点读机”的适用范围和运行效果。
此文章为搬运
原项目链接

















 8343
8343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









