






一、简述
1.1定义
主成分分析(Principal Component Analysis)简称PCA,是一个非监督学习的机器学习算法,主要用于数据的降维,对于高维数据,通过降维,可以发现更便于人类理解的特征。
PCA是实现数据降维的一种算法。正如其名,假设有一份数据集,每条数据的维度是D,PCA通过分析这D个维度的前K个主要特征(这K个维度在原有D维特征的基础上重新构造出来,且是全新的正交特征),将D维的数据映射到这K个主要维度上进而实现对高维数据的降维处理。 PCA算法所要达到的目标是,降维后的数据所损失的信息量应该尽可能的少,即这K个维度的选取应该尽可能的符合原始D维数据的特征。
1.2原理
降维有两种方法,一种是特征消除,另一种是特征提取
特征消除:将会在直接消除那些我们觉得不重要的特征,这会使我们对视这些特征中的很多信息。
特征提取:通过组合现有特征来创建新变量,可以尽量保存特征中存在的信息
PCA是一种常见的数据降维算法,PCA会将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,于是就可以用较少的综合指标分别代表存在于各个变量中的各类信息。
PCA的核心思想是找到一个维数更低的仿射集,然后将所有的数据点在其上做投影,以得到新的在更低维空间中的点作为新的数据。有两种方法选择合适的仿射集,在降维的同时不至于损失过多的信息呢:
最近重构性:样本点到该仿射集的距离要尽量小;
最大可分性:样本点到该放射集的投影要尽可能分开。
1.3优缺点
优点:降低数据的复杂性,识别最重要的多个特征
缺点:不一定需要,且可能损失有用信息
二、PCA步骤
输入:m条样本,特征数为n的数据集,即样本数据
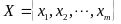
降维到的目标维数为k。记样本集为矩阵X。
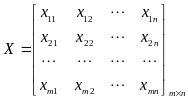
其中每一行代表一个样本,每一列代表一个特征,列号表示特征的维度,共n维。
输出:降维后的样本集
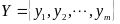
步骤如下:
第一步:对矩阵去中心化得到新矩阵X,即每一列进行零均值化,也即减去这一列的均值,
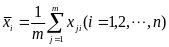
所求X仍为阶矩阵。
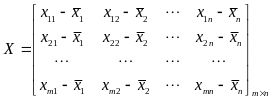
第二步:计算去中心化的矩阵X的协方差矩
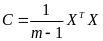 ,即
,即阶矩阵。
第三步:对协方差矩阵C进行特征分解,求出协方差矩阵的特征值,及对应的特征向量
,即
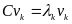
第四步:将特征向量按对应特征值从左到右按列降序排列成矩阵,取前k列组成矩阵W,即阶矩阵。
第五步,通过计算降维到k维后的样本特征,即
阶矩阵。
三、代码实现
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import numpy as np
iris = load_iris()
Y = iris.target # 数据集标签 ['setosa', 'versicolor', 'virginica'],山鸢尾、变色鸢尾、维吉尼亚鸢尾
X = iris.data # 数据集特征 四维,花瓣的长度、宽度,花萼的长度、宽度
# 标准化数据
X -= X.mean(axis=0)
# 计算协方差矩阵
C = X.T.dot(X)
# 计算特征值和特征向量
lam, v = np.linalg.eig(C)
# 对特征值排序并取前两个最大的
new_index = np.argsort(lam)[::-1]
lam = lam[new_index][:2]
v = v[:, new_index][:, :2]
# 计算新的特征矩阵
X_dr = X.dot(v)
# 对三种鸢尾花分别绘图
colors = ['red', 'black', 'orange']
# iris.target_names
plt.figure()
for i in [0, 1, 2]:
plt.scatter(X_dr[Y == i, 0],
X_dr[Y == i, 1],
alpha=1,
c=colors[i],
label=iris.target_names[i])
plt.legend()
plt.title('PCA of IRIS dataset')
plt.show()
运行结果
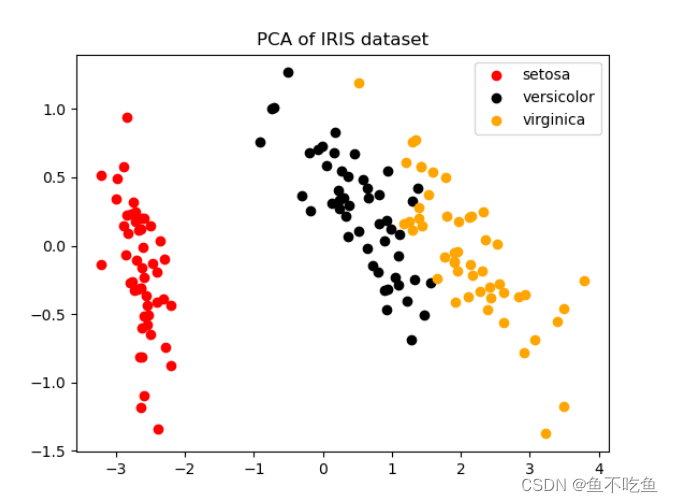
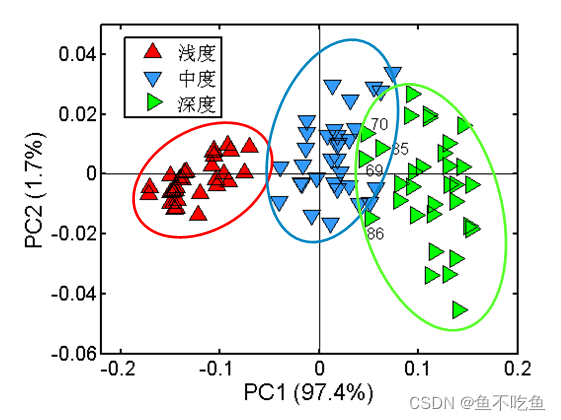
横坐标代表主成分1,纵坐标代表主成分2,从数据点的分布来看,混杂在一起的数据不多,数据容易进行分类。















 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









