






一、基于Logistic回归和Sigmoid函数的分类
1.1Logistic回归
逻辑回归(Logistic Regression)是一种用于解决二分类问题的统计模型,也可以扩展到多分类问题。它通过将线性回归模型的输出映射到一个概率值,并使用一个逻辑函数(通常是Sigmoid函数)将其限制在0和1之间。
在逻辑回归中,输入的特征经过权重和偏差的线性组合,然后通过逻辑函数进行转换。这个逻辑函数的输出表示了属于某个类别的概率。通常,当输出大于等于一个阈值时,将样本分类为正类,否则分类为负类。
逻辑回归的目标是学习到一组最优的权重和偏差参数,使得模型的预测与真实标签尽可能接近。为了达到这个目标,通常使用最大似然估计或者梯度下降等优化算法进行参数的训练和调整。
逻辑回归具有简单快速的训练过程和较好的可解释性,常用于分类问题,如广告点击预测、疾病诊断、信用风险评估等。
1.2Sigmoid函数
计算公式:
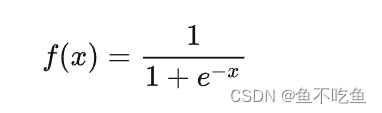
当x为0时,Sigmoid函数值为0.5。随着x的增大,对应的Sigmoid值将逼近于1;而随着x的减小,Sigmoid值将逼近于0.如果横坐标刻度足够大,Sigmoid函数看起来很像一个阶跃函数。
二、基于最优化方法的最佳回归系数确定
sigmoid函数的输入记为z,由下面公式可以得出:z=w0x0+w1x1+w1x1+...+wnxn
其中的向量z是分类器的输入数据,向量w也就是我们要找到的最佳参数
2.1梯度上升法
基本思想:要找到某个函数的最大值,最好的方法就是沿着该函数的梯度方向寻找,直至找到某个临界值,或者是达到某个可以允许的误差范围。
2.2 训练算法:使用梯度上升找到最佳参数
梯度上升法的步骤如下:
每个回归系数初始化为1
重复n次:
计算整个数据集的梯度
使用alpha*gradient更新回归系数的向量
返回回归系数
代码如下:
import numpy as np
# 加载数据函数
def loadDataSet():
dataMat=[]
labelMat=[]
# 打开文本文件
fr=open('testSet.txt')
# 按行读取文件
for line in fr.readlines():
# strip()默认删除字符串中的空格,换行等,如果是strip(s)就是删除字符串中的s
# split()函数用于分割字符串
lineArr=line.strip().split()
# 将xy坐标对放到数据组里
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])
# 放到标签组里
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
# sigmoid函数 inX是一个向量
def sigmoid(inX):
return 1/(1+np.exp(-inX))
# 梯度上升法
def gradAscent(dataMatIn,classLabels):
# np.mat矩阵将输入解释为矩阵,np.matrix函数用于从类数组对象或数据字符串返回矩阵,np.array()函数用于创建一个数组
dataMatrix=np.mat(dataMatIn)
# transpose函数求转置矩阵
labelMat=np.mat(classLabels).transpose()
# 获得矩阵的维数
m,n=np.shape(dataMatrix)
# 目标移动的步长
alpha=0.001
# 迭代次数
maxCycles=500
# 得到一个n行1列全是1 的矩阵
weights=np.ones((n,1))
print(weights)
# 循环进行迭代 矩阵相乘
for k in range(maxCycles):
# 计算sigmoid函数的值 h是一个列向量
h=sigmoid(dataMatrix*weights)
# 得到误差值,在这里计算真实类别和预测类别之间的差值,就是按照该差值的方向调整回归系数
error=(labelMat-h)
# weight是最优参数
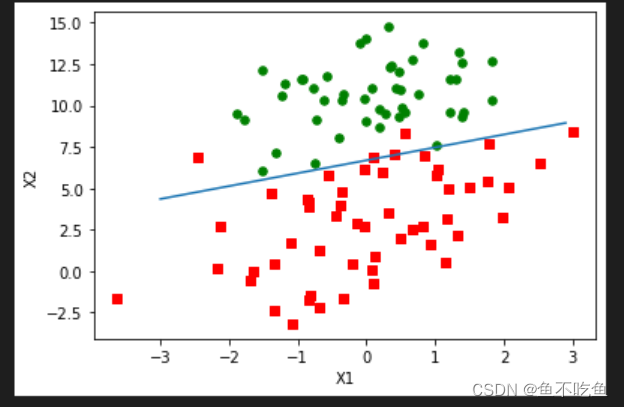
weights=weights+alpha*dataMatrix.transpose()*error
return weights2.3分析数据:画出决策边界
# 画出数据集和logistic回归最佳拟合直线的函数
import numpy as np
def plotBestFit(weights):
import matplotlib.pyplot as plt
# getA()函数将矩阵转化为数组
# weights=wei.getA()
# 加载数据
dataMat,labelMat=loadDataSet()
dataArr=np.array(dataMat)
# print(dataArr)
n=np.shape(dataArr)[0]
xcord1=[]
ycord1=[]
xcord2=[]
ycord2=[]
# print(labelMat)
for i in range(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i][1])
ycord1.append(dataArr[i][2])
else:
xcord2.append(dataArr[i][1])
ycord2.append(dataArr[i][2])
fig=plt.figure()
ax=fig.add_subplot(111)
# print(xcord1)
# print(ycord1)
ax.scatter(xcord1,ycord1,s=30,c='red',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='green')
# arange()函数用于创造等差数组
# 起始点 终止点 步长
x=np.arange(-3.0,3.0,0.1)
y=(-weights[0]-weights[1]*x)/weights[2]
ax.plot(x,y)
# 添加xy轴标签
plt.xlabel('X1')
plt.ylabel('X2')
# 显示图像
plt.show()得到输出结果为:
2.4 训练算法:随机梯度上升
步骤如下:
所有回归系数初始化为1
对数据集中每个样本
计算该样本的梯度
使用alpha*gradient更新回归值系数值
返回回归系数值
代码如下:
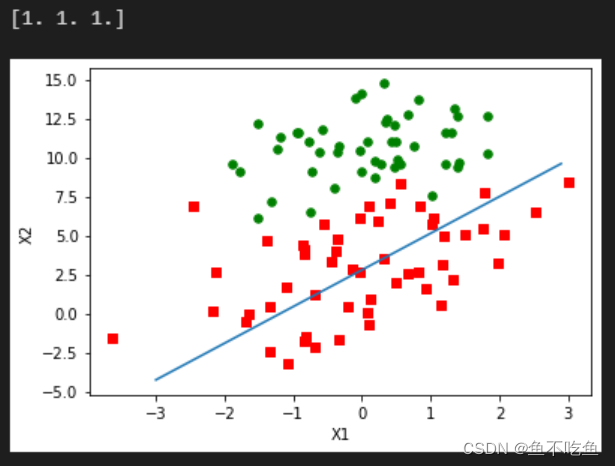
# 随机梯度上升法
def stocGradAscent0(dataMatrix,classLabels):
dataMatrix=np.array(dataMatrix)
# 不需要进行矩阵的转换
m,n=np.shape(dataMatrix)
# 移动步长加大
alpha=0.01
weights=np.ones(n)
print(weights)
for i in range(m):
# 不是数值的计算,而是向量的计算
h=sigmoid(sum(dataMatrix[i]*weights))
error=classLabels[i]-h
weights=weights+alpha*error*dataMatrix[i]
return weights输出结果为:
三、示例
3.1 准备数据:处理数据中的缺失值
数据中存在缺失值可处理的方法:
使用可用特征的均值来填补缺失值;
使用特殊值来填补缺失值,如-1;
忽略有缺失值的样本;
使用相似样本的均值来填补缺失值;
使用另外的机器学习算法来预测缺失值。
3.2 测试算法:用logistic回归进行分类
# 如果预测的sigmoid值大于0.5就属于第一个类别,否则就属于第二个类别
# 回归系数 特征向量
def classifyVector(inX,weights):
prob=sigmoid(sum(inX*weights))
# print(prob)
if prob>0.5:
return 1.0
else:
return 0.0
# 打开测试集和训练集
def colicTest():
# 读取文件
frTrain=open('horseColicTraining.txt')
frTest=open('horseColicTest.txt')
trainingSet=[]
trainingLabels=[]
# 按行读取训练集文件
for line in frTrain.readlines():
currLine=line.strip().split('\t')
lineArr=[]
# 读取每行的22个数据
for i in range(21):
lineArr.append(float(currLine[i]))
# 特征
trainingSet.append(lineArr)
# 标签为最后一个数据
trainingLabels.append(float(currLine[21]))
# 计算回归系数向量 可自由设置迭代次数
trainWeights=stocGradAscent1(np.array(trainingSet),trainingLabels,500)
# print(trainWeights)
errorCount=0
numTestVec=0.0
# 读取测试集文件
for line in frTest.readlines():
# print(line)
numTestVec+=1.0
currLine=line.strip().split('\t')
lineArr=[]
for i in range(21):
lineArr.append(float(currLine[i]))
# print(lineArr)
if int(classifyVector(np.array(lineArr),trainWeights))!=int(float(currLine[21])):
# print(int(float(currLine[21])))
errorCount+=1
# 计算错误率
errorRate=(float(errorCount)/numTestVec)
# print(errorCount,numTestVec,errorRate)
print('the error rate of this test is :%f' % errorRate)
# 返回错误率
return errorRate
def multTest():
numTests=10
errorSum=0.0
# 调用十次colivTest函数,并且求得平均值,得到最终结果
for k in range(numTests):
errorSum+=colicTest()
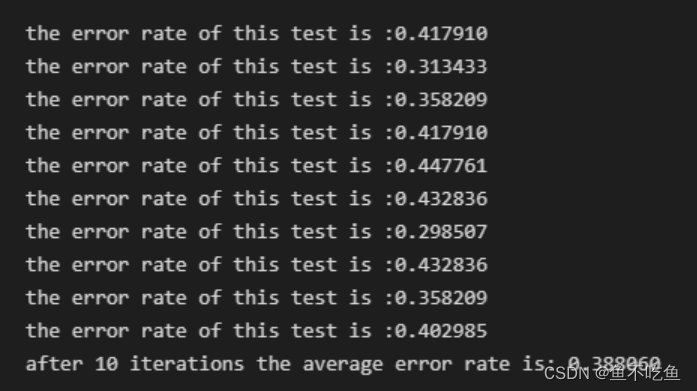
print('after %d iterations the average error rate is: %f' % (numTests,errorSum/float(numTests)))输出结果为:















 1834
1834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









