






文章目录
前言
SVM被提出于1964年,在二十世纪90年代后得到快速发展并衍生出一系列改进和扩展算法,在人像识别、文本分类等模式识别(pattern recognition)问题中有得到应用 。SVM是由模式识别中广义肖像算法(generalized portrait algorithm)发展而来的分类器 ,其早期工作来自前苏联学者Vladimir N. Vapnik和Alexander Y. Lerner在1963年发表的研究 。1964年,Vapnik和Alexey Y. Chervonenkis对广义肖像算法进行了进一步讨论并建立了硬边距的线性SVM 。此后在二十世纪70-80年代,随着模式识别中最大边距决策边界的理论研究 、基于松弛变量(slack variable)的规划问题求解技术的出现 ,和VC维(Vapnik-Chervonenkis dimension, VC dimension)的提出 ,SVM被逐步理论化并成为统计学习理论的一部分 。1992年,Bernhard E. Boser、Isabelle M. Guyon和Vapnik通过核方法得到了非线性SVM 。1995年,Corinna Cortes和Vapnik提出了软边距的非线性SVM并将其应用于手写字符识别问题 ,这份研究在发表后得到了关注和引用,为SVM在各领域的应用提供了参考。
一、相关概念
1.SVM
SVM本质模型是特征空间中最大化间隔的线性分类器,是一种二分类模型。
间隔最大使它有别于感知机。
2.SVM的分类
1.线性可分支持向量机(硬间隔最大化)
2.线性支持向量机(训练数据近似线性可分时,通过软间隔最大化。
3.非线性支持向量机(当训练数据线性不可分时,通过使用核技巧及软间隔最大化。
3.SVM的三类问题
(1)数据线性可分,硬间隔SVM
(2)数据近似线性可分,软间隔SVM
(3)数据不可以线性分,核技巧
二、线性可分和线性不可分
1.线性可分和线性不可分的定义
线性可分:有一条直线,可以将O和X分开。如下图

线性不可分:不存在一条直线,将O和X分开。
在高维度是,我们需要借助数学来定义
在数学上严格的定义:
在二维上

(大于0小于0区域使我们自己设的,你只需要令参数为相反,即区域就互换一下即可)
假设:现在有N个训练样本集以及他们的标签
严格定义:一个训练样本集{(xi,yi),…(xn,yn)},在i=1–N线性可分,是指存在(w1,w2,b),使得对i=1—N,有:

用向量形式定义:
假设

可在总结为一句话:

2.点到超平面的距离

三、问题描述
1.引出问题
如果是线性可分的,在这无数多个分开各个类别的超平面中,到底哪一个才是最好的?

2.最优化理论
假设对任一条分开的线,把它向一侧平行的移动,当它擦到一个或几个样本为止。同时,也向另外一层平行移动。我们求的就是间隔最大的线
用图像来显示

支持向量:我们定义两条平行线擦到的训练样本,叫做支持向量。
间隔:两条平行线的距离。
中间的线我们取名为决策边界
支持向量机寻找最优分类的直线应该满足:
1.该直线分开了两类
2.该直线最大化间隔
3.该直线处于间隔的中间,到所有支持向量距离相等的点
(这是二维的讨论是直线,高维度直线则变成超平面)
四、优化问题
1.最大化间隔
推导的过程


为了方便后面求导,我们一般将其转换为最小化1/2||w||^2

w为一个向量,w模的平方
2.优化问题求解
(1)拉格朗日数乘法
拉式乘数法主要用来求解带约束条件下的极值

那么根据之前的条件,我们可以写出
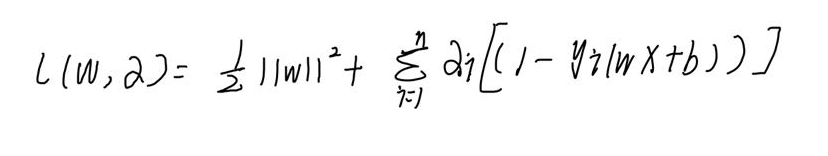
3.原问题与拉格朗日对偶问题
(1)原问题

(2)对偶问题

有几个定理


KKT条件:从上面公式理解就是ai=0或g(w)=0
五、硬间隔最大优化问题求解



用一个例子




六、软间隔最大优化问题求解
1.近似线性可分问题导出
近似线性可分简而言之,就是在线性可分的情况下,加了一些噪声数据点。


2.优化问题求解



七、非线性SVM问题
1.引出问题
若出现

线性不可分的情况,我们该怎么做?
2.低维到高维的映射
定理:在一个M维空间上随机取N个训练样本,随机对每个样本赋予标签+1和-1,假设这些训练样本线性可分的概率为P(M),当M趋于无穷大时,P(M)的概率趋向于1
3.核函数

4.常用的核函数

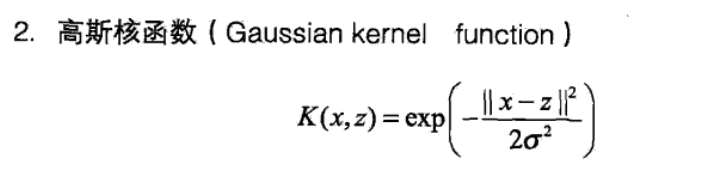

总结
以上就是对SVM的学习,其中SMO算法暂时还没有去学习,对核函数相关内容仍有一些不足。















 2200
2200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









