







A Survey on Bridging EEG Signals and Generative AI: From Image and Text to Beyond2025.2.18
只是为了学习
Abstract
脑机接口(BCI)和生成性人工智能(GenAI) 的集成开辟了大脑信号解码的新领域,实 现了辅助交流、神经表征学习和多模式集 成。BCI,特别是那些利用脑电图(EEG)的 BCI,提供了一种将神经活动转化为有意义输出的非侵入性方法。
深度学习的最新进 展,包括生成对抗网络(GAN)和基于变 换器的大型语言模型(LLM),显著改善了 基于 EEG 的图像、文本和语音生成。本文 对基于 EEG 的多模态生成的最新进展进行 了文献综述,重点关注(i)通过 GAN、变 分自编码器(VAE)和扩散模型生成 EEG 到图像,以及(ii)利用基于 Transformer 的 语言模型和对比学习方法生成 EEG 到文本。此外,我们还讨论了脑电到语音合成的新兴领域,这是一个不断发展的多模态 前沿。
相关知识请看:EEG图像生成知识点-CSDN博客
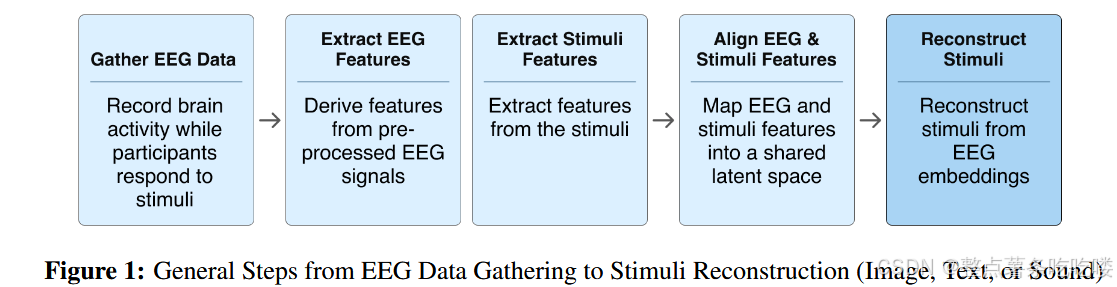
我们重点介绍支持生成方法的关键 数据集、用例、挑战和 EEG 特征编码方法。 通过提供基于 EEG 的生成人工智能的结构 化概述,这项调查旨在为研究人员和从业 者提供见解,以推进神经解码,增强辅助 技术,并扩展脑机交互的前沿。
虽然是综述,但也只是综述,针对某一个应用,并不是很前沿,也不是很深,不是很详细,还是得靠自己。
因此此文章为无脑翻译的重点阅读与知识点学习。
3 EEG 到图像生成
本节探讨了通过 EEG 从视觉诱发的脑信号中 再生图像。它涵盖了用例、解决的问题、采用 的技术以及调查研究中使用的用于图像生成的 EEG 特征编码方法。
3.1 用例和解决的问题
调查研究解决了关键挑战,如 EEG 信号 (Bai et al., 2023; Lan et al., 2023; Zeng et al., 2023a) 的 低信噪比、EEG 信号 (Bai et al., 2023) 的信息 有限和个体差异、与数字和字符 (Mishra et al., 2023) 相比在自然物体图像上的性能较低以及 数据集 (Singh et al., 2023) 较小。
此外,一 些研究探索了监督学习 (Li et al., 2020; Song et al., 2023) 的替代方案,因为它需要大量的数 据。Song et al. (2023) 解决了人们对沿时间和空 间维度分别应用卷积层的担忧,这会破坏通道 之间的相关性,阻碍大脑活动的空间特性。总 体而言,这些方法旨在增强大脑数据 (Li et al., 2024) 的训练、表现和解释。
Kavasidis et al. (2017),Song et al. (2023) and Mishra et al. (2023) 提取包含判别信息的特定类别 EEG 编码以提高图像生成质量,同时 (Nemrodov et al., 2018) 专注于利用时空 EEG 信息来 确定面部身份表示的神经相关性,while (Khaleghi et al., 2022) 将 EEG 信号映射到与每个图像对 应的视觉显著性图。
其他常见策略包括将神经信号投影到具有图像嵌入 (Shimizu and Srinivasan, 2022) 的共享子空间中,生成特定类别的 EEG 编码作为潜在表示 (Mishra et al., 2023), 以及从 EEG 信号中解码多级感知信息以产生 多粒度输出 (Lan et al., 2023)。
此外,研究工作侧重于提高跨数据 (Singh et al., 2024) 集的特征提取管道的通用性,评估 不同通道 (Sugimoto et al., 2024) 的性能,并结 合注意力模块来突出每个通道或频带 (Li et al., 2024) 的重要性。
3.2 跨研究使用的技术
采用各种计算机视觉生成模型从 EEG 信号中 重建图像。这些包括变分自编码器 (Kavasidis et al., 2017; Wakita et al., 2021)、生成对抗网络 (GAN)(Kavasidis et al., 2017; Khaleghi et al., 2022; Mishra et al., 2023; Singh et al., 2024; Li et al., 2024) 和条件 GAN(Singh et al., 2023; Ahmadieh et al., 2024)。扩散模型,包括将 EEG 嵌入细化为图像先验 (Shimizu and Srinivasan, 2022) 的先验扩散模型,以及预训练的扩散模 型,如Stable Diffusion (Bai et al., 2023),也经常被使 用。此外,基于 U-net 架构的扩散模块已被用 于进一步增强 EEG 到图像的重建。
对比学习是另一种流行的对齐多模态嵌入 的方法,在研究 (Singh et al., 2023; Lan et al., 2023; Song et al., 2023; Sugimoto et al., 2024) 中 用于从 EEG 信号中获得判别特征,并通过约 束它们的余弦相似性 (Song et al., 2023) 来对齐 这两种模态。
相关论文学习链接:,,,后续再补充
(Singh et al., 2023)Eeg2image: image reconstruction from eeg brain signals
(Lan et al., 2023)Seeing through the brain: Image reconstruction of visual perception from human brain signals
(Sugimoto et al., 2024)Image generation using eeg data: A contrastive learning based approach
还有(Song et al., 2023) Decoding natural images from eeg for object recognition
此外,注意力机制被整合到各 种模型 (Mishra et al., 2023; Song et al., 2023; Li et al., 2024) 中,以提高图像质量,捕捉反映从 EEG 数据推断的大脑活动的空间相关性,并确 定单个 EEG 通道的相对重要性。
3.3 脑电特征编码技术
在 EEG 到图像重建中,该过程通常始于编码器识别 EEG 信号的潜在特征空间,然后是解码器将这些特征转换为图像。基于长短期记忆 (LSTM)的架构因其在捕获 EEG 信号中的时间依赖性方面的有效性而被广泛使用。Kavasidis et al. (2017) 采用 LSTM 网络生成紧凑的类判别特征向量,该向量也用于对象识别。同样, (Singh et al., 2023) 将 LSTM 与基于三重损失的对比学习方法相结合,以增强特征辨别能力。 通过结合 在三重损失的 EEG 标签监督下 训练的 CNN 和 LSTM 架构来Singh et al. (2024) 扩展这种方法,进一步改善了判别特征学习。 此外,(Ahmadieh et al., 2024) 使用 LSTM 横跨二个维度(EEG 通道和信号持续时间) 来提取 EEG 特 征,并通过各种回归方法(包括多项式回归、 神经网络回归以及 1 型和 2 型模糊回归)增强 特征生成。
一些研究还利用卷积架构来捕捉 EEG 中的 空间依赖性。Li et al. (2020) 使用三层前馈神 经网络将 EEG 信号投影到语义特征中。Wakita et al. (2021) 采用 1D 卷积编码器-解码器作为 多模态变分自动编码器(VAE)的一部分,以 获得用于 EEG 信号表示的均值和方差向量。 Mishra et al. (2023) 使用注意力模块增强了的 卷积编码器-解码器框架,以更多地关注具有 重要特征的信道,而不是使用具有相等权重的 所有特征。同样,Sugimoto et al. (2024) 实现了 紧凑卷积网络 EEGNet(Lawhern et al., 2018) 作 为 EEG 编码器,同时Li et al. (2024) 使用 Sinc EEGNet(Bria et al., 2021),这是一种结合了基 于 Sinc 的卷积层、深度卷积和可分离卷积的架 构来提取 EEG 特征。它还集成了一种注意力 机制,用于识别最相关的频带和信道,以便进 行基于信号的分类。
已经探索了基于图的 EEG 特征提取技术。 从 EEG 信号中Khaleghi et al. (2022) 构建基于 函数图连通性的嵌入,然后使用几何深度网络 (GDN)对其进行处理以导出特征向量。将时 空卷积与即插即用空间模块相Song et al. (2023) 结合,利用自我注意和图形注意机制更有效地 提取 EEG 特征。
为了整合时间和空间特征提取机制以改进基 于 EEG 的图像重建,Zeng et al. (2023a) 开发了 一个受 EEGChannelNet(Palazzo et al., 2020) 和 ResNet-18 启发的框架,将空间、时间和时空块 与多核残差块相结合。Shimizu and Srinivasan (2022) 使用具有通道变换编码器和时空卷积的 时间序列启发架构来提取丰富的潜在 EEG 表 示。
自监督学习和对比学习已被应用于增强 EEG 特征提取。Bai et al. (2023) 使用掩蔽信 号建模,其中 EEG tokens被部分掩蔽,1D 卷积 层将所有tokens转换为嵌入。掩码自动编码器 (MAE)预测丢失的tokens,优化学习到的表示。 Lan et al. (2023)采用对比学习从 EEG 信号中提取像素级语义, 同时使用 GAN 生成轮廓信息的显著图。它还通过专门的损失函数将image captions的 CLIP 嵌入 与 EEG 样本级编码器对齐。
怎么理解像素级语义?
“像素级语义”(Pixel-Level Semantics)是计算机视觉中的核心概念,指为图像中的每个像素分配一个语义标签(如“人”“车”“天空”等),从而实现细粒度的图像理解。它超越了传统目标检测(框级定位)或图像分类(整体标签),直接关联图像的底层像素信息与高层语义信息。
1. 核心思想
像素与语义的直接映射:将图像中的每个像素映射到预定义的语义类别,例如在街景分割中,每个像素被标记为“道路”“行人”“车辆”等类别。
从局部到全局的关联:结合像素的局部特征(颜色、纹理)与全局上下文(物体间关系、场景结构),确保分割结果的连贯性。
2. 关键技术
全卷积网络(FCN)
通过卷积层替代全连接层,允许任意尺寸输入,输出与输入分辨率相同的像素级预测图。编码器-解码器结构(如U-Net)
编码器:提取多尺度特征(高层语义信息);
解码器:恢复空间分辨率,融合浅层细节(边缘、纹理)与深层语义。
注意力机制(如Transformer):通过自注意力捕捉长距离依赖,增强模型对复杂场景的建模能力(如DeepLab中的空间金字塔池化)。
3. 挑战与解决方案
挑战 解决方案 计算量大 轻量级模型(MobileNetV3)、知识蒸馏、模型压缩 标注成本高 弱监督学习(仅用图像级标签)、半监督学习、合成数据生成(GANs) 类别不平衡 加权损失函数(如Focal Loss)、数据增强(过采样稀有类别) 边缘模糊 多尺度特征融合、条件随机场(CRF)后处理、边缘感知损失函数
4. 与相关概念的区别
目标检测(Object Detection):框级定位(Bounding Box),无法精确到像素边缘。
实例分割(Instance Segmentation):区分同类物体的不同个体(如“人A” vs “人B”)。
语义分割(Semantic Segmentation):仅关注类别(如“人”),不区分个体。
6. 典型模型演进(有机会还是要嘟嘟的)
FCN(2015):开创全卷积端到端分割。
U-Net(2015):医学影像分割标杆,跳跃连接融合特征。
DeepLab系列(2017+):空洞卷积扩大感受野,ASPP模块捕捉多尺度上下文。
Mask R-CNN(2017):联合目标检测与实例分割。
Vision Transformer(2021):全局注意力机制提升分割精度(如SETR、Segmenter)。
7. 关键指标
交并比(IoU):预测区域与真实区域的交集与并集之比(最常用指标)。
像素准确率(Pixel Accuracy):正确分类像素占总像素的比例。
平均精度(mAP):多类别场景下的综合性能评估。
3.4 评估指标
EEG 到图像的生成通常从对象分类开始,以 确保提取的 EEG 特征包含有用的类判别信 息。通常使用 (Shimizu and Srinivasan, 2022; Lan et al., 2023; Song et al., 2023)top-k 准确性等指 标,以及定性视觉分析和定量评估。
关键的 定量指标包括用于衡量图像质量的Inception Score (IS)、用于衡量真实感 (Bai et al., 2023; Singh et al., 2024; Ahmadieh et al., 2024) 的 Frechet Inception Distance (FID) 以 及 用 于 评 估 感 知 保 真 度 (Khaleghi et al., 2022; Shimizu and Srinivasan, 2022; Bai et al., 2023; Ahmadieh et al., 2024; Sugimoto et al., 2024) 的结构相似性指数(SSIM) (Salimans et al., 2016) 等显著性指标。
其他有用 的指标是 PixCorr(逐像素相关性)(Shimizu and Srinivasan, 2022)、核起始距离(KID) (Singh et al., 2024)、LPIPS(学习感知图像块相似性) (Bai et al., 2023) 和多样性得分 (Mishra et al., 2023)。

















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









