







>-**🍨本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/2Wc0B5c2SdivAR3WS_g1bA)中的学习记录博客**
>-**🍦 参考文章:Pytorch实战 |第P7周:咖啡豆识别(训练营内部成员可读)**
>-**🍖 原作者:[K同学啊|接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**
1自己搭建VGG-16网络框架
将类似结构块,单独定义出来,少做重复的事情
import torch.nn as nn
import torch
class MYVGG(nn.Module): # 定义VGG网络
def __init__(self, features, num_classes=1000): # num_classed 为分类的个数
super(MYVGG, self).__init__()
self.features = features # 特征提取层(卷积)通过make_features 创建 负责卷积部分
self.avgpool=nn.AdaptiveAvgPool2d((7,7))
self.classifier = nn.Sequential( #负责全连接部分
# dropout 随机失活
nn.Linear(512*7*7, 4096), # 特征提取最后的size是(512*7*7)
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x) # 特征提取层 卷积
x=self.avgpool(x)
x = torch.flatten(x, start_dim=1) # ddata维度为(batch_size,512,7,7),从第二个维度开始flatten
x = self.classifier(x) # 分类层
return x
def make_features(cfg: list): # 生成特征提取层,就是VGG前面的卷积池化层
layers = [] # 保存每一层网络结构
in_channels = 3 # 输入图片的深度channels,起始输入是RGB 3 通道的
for v in cfg: # 遍历配置列表 cfgs
if v == "M": # M 代表最大池化层,VGG中maxpool的size=2,stride = 2
layers += [nn.MaxPool2d(kernel_size=2, stride=2)] # M 代表最大池化层
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) # 数字代表卷积核的个数==输出的channels VGG中全部是由 **stride = 1,padding = 1**
layers += [conv2d, nn.ReLU(True)] # 添加卷积层
in_channels = v # 输出的channels == 下次输入的channels
return nn.Sequential(*layers) # 解引用,将大的list里面的小list拿出来
# 特征提取层的 网络结构参数
cfgs = { # 建立网络的字典文件,对应的key可以生成对应网络结构参数的value值
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], # 数字代表卷积核的个数,M代表池化层
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
# 定义生成VGG 网络函数
def vgg(model_name="vgg16", num_classes = 10): # 创建VGG网络,常用的为 VGG16 结构,如果不指定分类个数,默认是10
cfg = cfgs[model_name] # 先定义特征提取层的结构
model = MYVGG(make_features(cfg), num_classes=num_classes) # 将cfgs里面某个参数传给make_features,并且生成VGG net
return model
net = vgg(model_name='vgg16',num_classes=4)
print(net)2调用官方的VGG-16网络框架
from torchvision.models import vgg16
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
# 加载预训练模型,并且对模型进行微调
model = vgg16(pretrained = True).to(device) # 加载预训练的vgg16模型 这里True Flase是看你需不需要预训练 需要就直接把官方参数初始化
for param in model.parameters(): #这里全部冻结 后面
param.requires_grad = False # 冻结模型的参数,这样子在训练的时候只训练最后一层的参数
model.classifier._modules['6'] = nn.Linear(4096,·4) # 修改vgg16模型中最后一层全连接层,输出目标类别个数
model.to(device)
model3如何查看模型的参数量以及相关指标
# 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
Linear-32 [-1, 4096] 102,764,544
ReLU-33 [-1, 4096] 0
Linear-34 [-1, 4096] 16,781,312
ReLU-35 [-1, 4096] 0
Linear-36 [-1, 4] 16,388
================================================================
Total params: 134,276,932
Trainable params: 134,276,932
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.52
Params size (MB): 512.23
Estimated Total Size (MB): 731.32
----------------------------------------------------------------这次与之前一样,使用Adam优化器,和动态学习率,效果较好, 最高高达98.3%
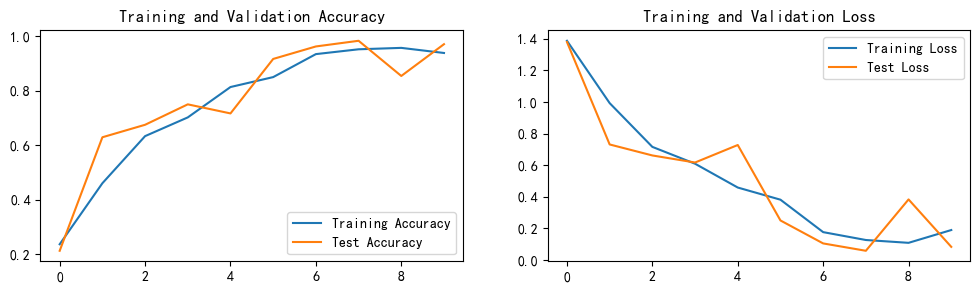
目前还需了解其他优化手段















 1118
1118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









