









博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
目录
目录
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
博主提供的项目均为博主自己收集和开发的!所有的源码都经由博主检验过,能过正常启动并且功能都没有问题!同学们拿到后就能使用!且博主自身就是高级开发,可以将所有的代码都清晰讲解出来。
文章下方名片联系我即可~大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻精彩专栏推荐订阅:在下方专栏

Python 融合
作为整个技术栈的“胶水语言”,Python 凭借其简洁的语法和丰富的第三方库,能够轻松衔接各个组件。利用 pyhdfs 或 hdfs3 等库,Python 脚本能够与 Hadoop 分布式文件系统无缝交互,读取和写入大规模数据;借助 mysql-connector-python 或 SQLAlchemy,Python 直接操作 MySQL,完成数据的增删改查;在爬虫端,通过 Scrapy 或 Requests + BeautifulSoup,高效采集网页内容并初步清洗;最后,所有处理结果都可被封装成模块,供 Flask 应用通过 RESTful 接口调用,从而实现“数据采集—存储—计算—展示”全流程自动化。
Flask 融合
Flask 的微框架特性让它成为前端与后端、用户与数据之间的桥梁。在爬虫模块完成数据抓取并存入 MySQL 后,Flask 可借助 Jinja2 模板或 Flask-RESTful,将这些结构化数据展示为图表、表格或 API 接口;同时,通过 Celery(配合 Redis)调度爬虫作业和 Hadoop 任务,让 Flask 不仅仅是展示层,也能负责触发和监控后端大数据作业;借助 Flask-Admin 或 Flask-SQLAlchemy,还能快速生成运维后台,实时查看 HDFS 上文件状态和 MapReduce 任务进度。
Hadoop 融合
面对海量离线数据处理,Hadoop 提供了可靠的分布式存储与计算能力。Python 脚本可通过 Hadoop Streaming 将 MapReduce 任务打包部署到集群;爬虫抓取的原始日志可直接推送到 HDFS,并由 Hadoop 进行预处理和 ETL;处理完成的中间结果再写回 MySQL,以便于在线查询;在 Flask 中,可通过 RESTalytics(自定义分析接口)触发 Hadoop 作业并获取统计报表,为用户提供大规模数据分析能力,同时保证应用的高可用与伸缩性。
MySQL 融合
作为关系型数据库,MySQL 负责存储业务关键的结构化数据与元数据。爬虫模块将采集的实时数据写入 MySQL,用于快速检索和二次加工;Hadoop 离线计算后的聚合结果定期同步到 MySQL,供在线应用调用;Python ORM(如 SQLAlchemy)进一步抽象了表结构,简化了业务逻辑;而 Flask 端则通过 SQLAlchemy 或 Flask-MySQLdb 直接连接 MySQL,为前端提供灵活的查询和事务支持,保证了系统的性能与数据一致性。
爬虫(Crawler)融合
爬虫模块是数据流的“上游入口”。借助 Python 强大的网络请求库和分布式框架(如 Scrapy+Scrapyd 或分布式任务队列 Celery + Redis),爬虫可横跨多个站点并行抓取,实时将原始网页和日志写入 HDFS;同时,根据业务需求,爬虫也可直接将热点数据推送到 MySQL,确保在线系统能获取最新信息;后端通过 Flask 提供的调度接口,动态触发爬虫任务、监控抓取进度,而爬虫产出的结构化数据又反过来驱动 Hadoop 分析和 Flask 展示,实现完整的“网—算—存—显”闭环。

系统实现:
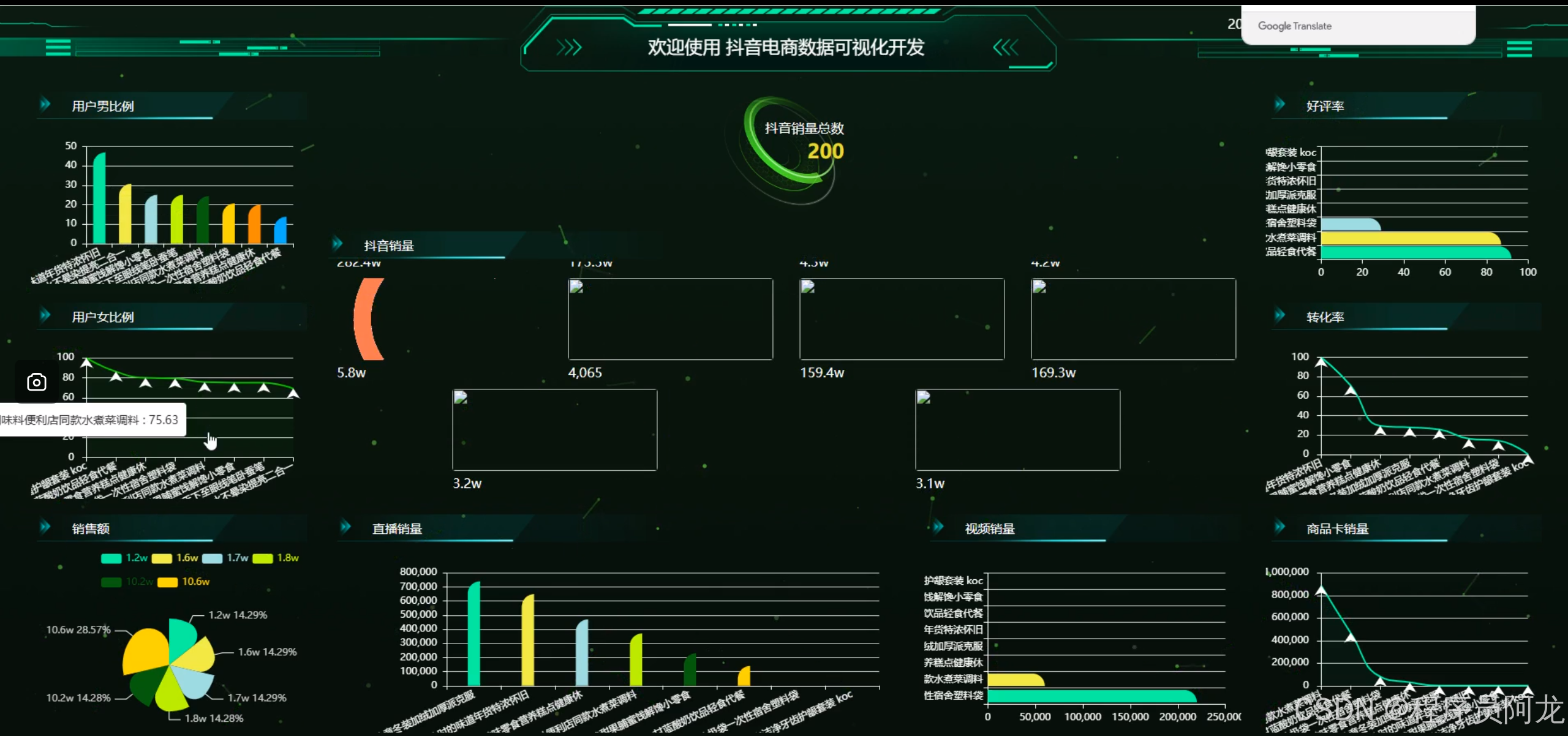
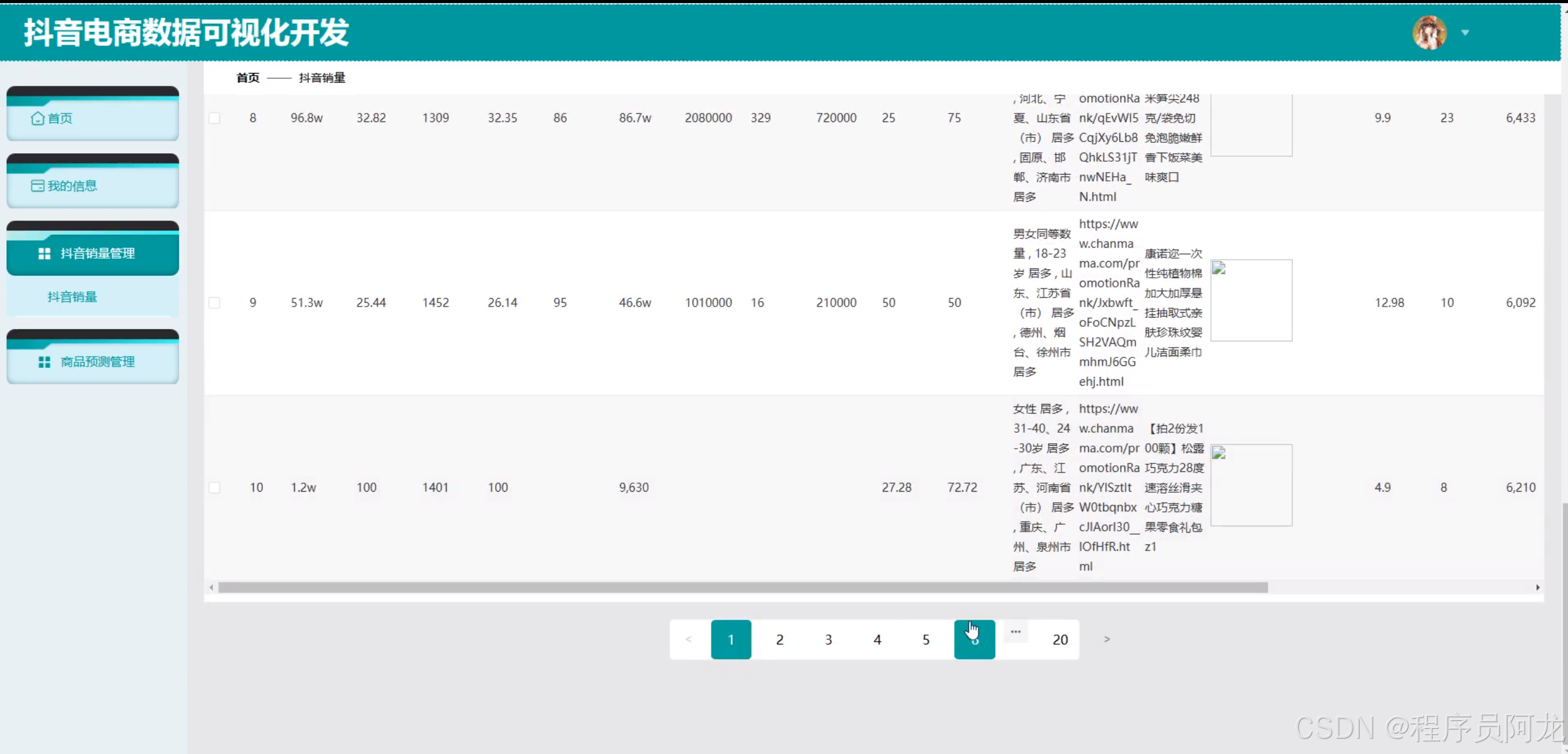
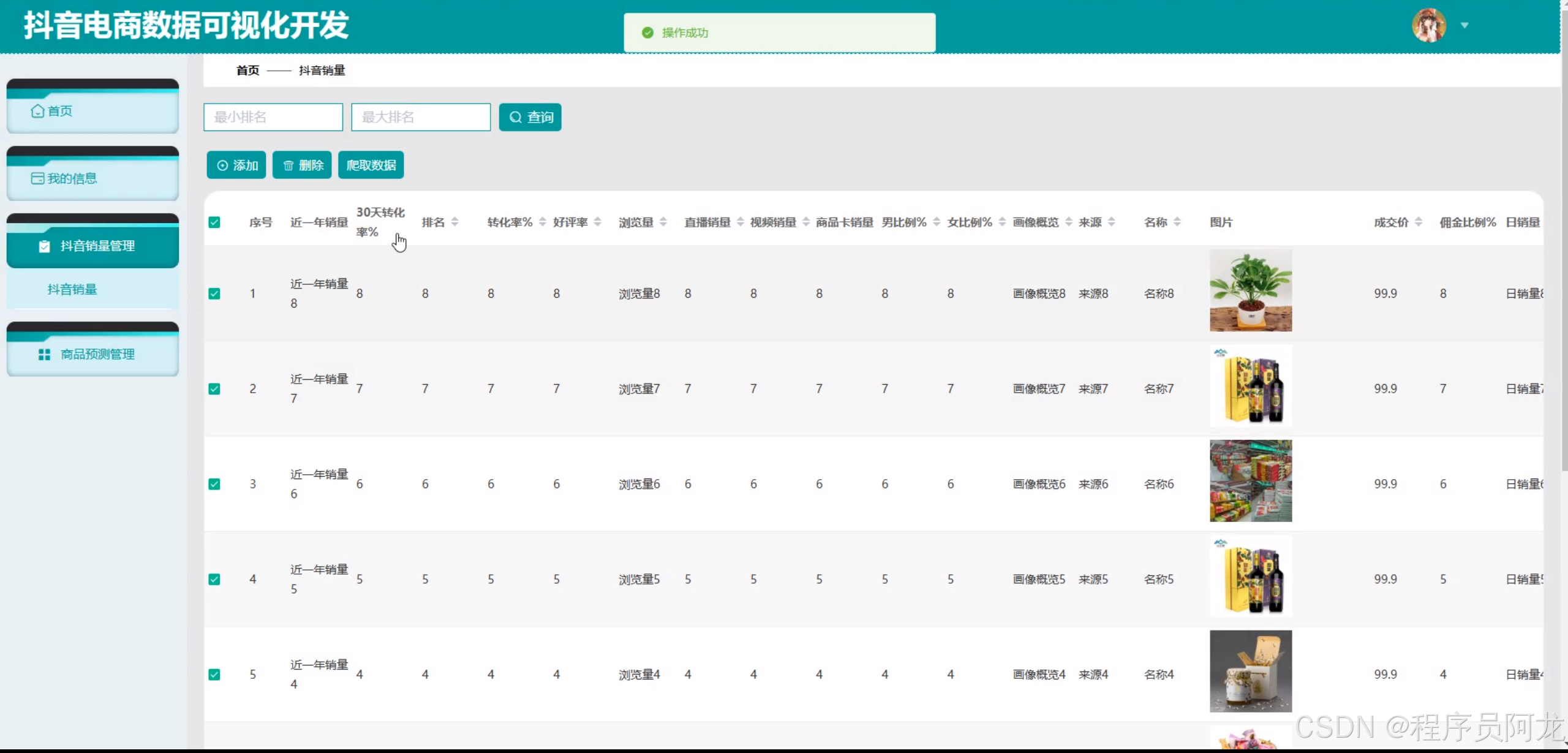
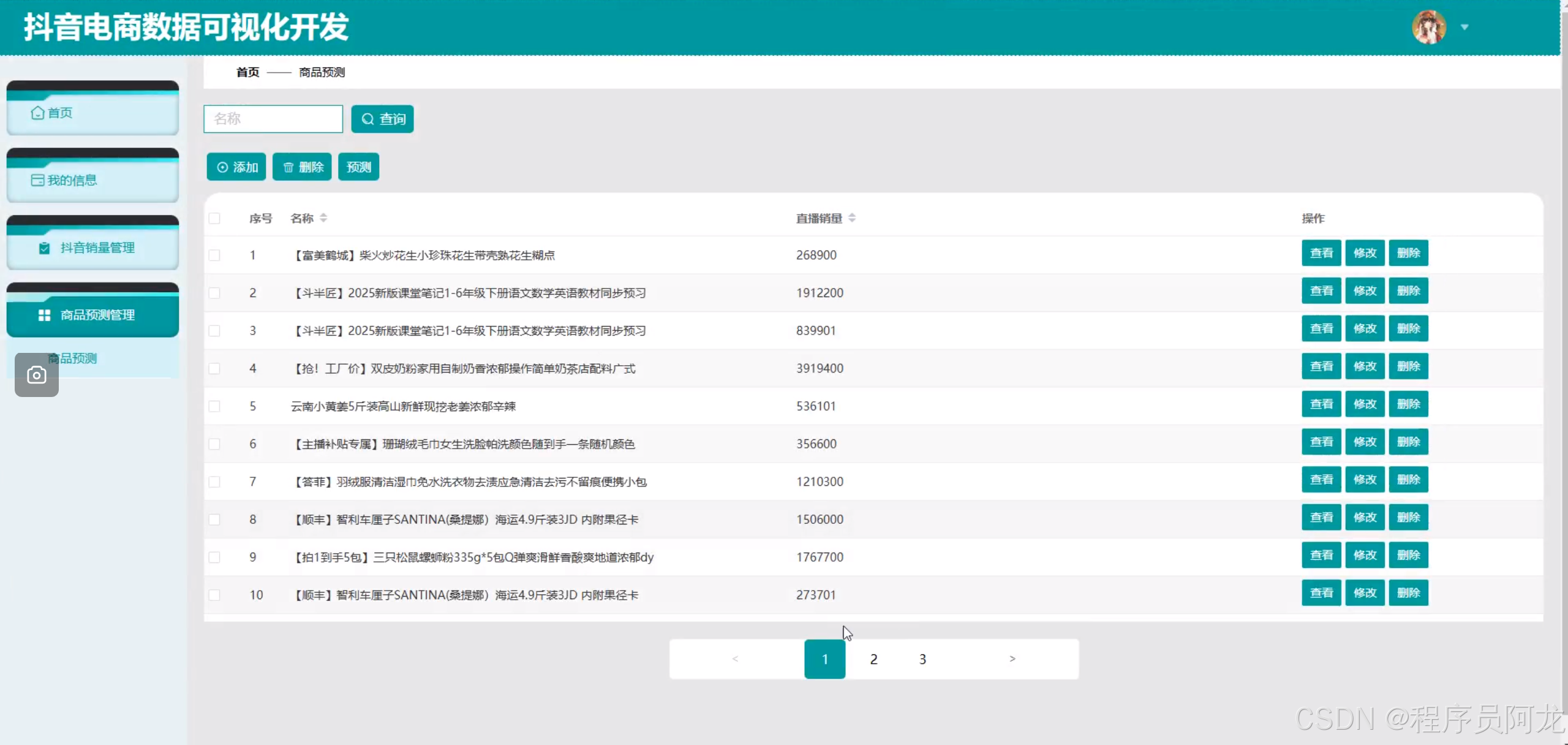
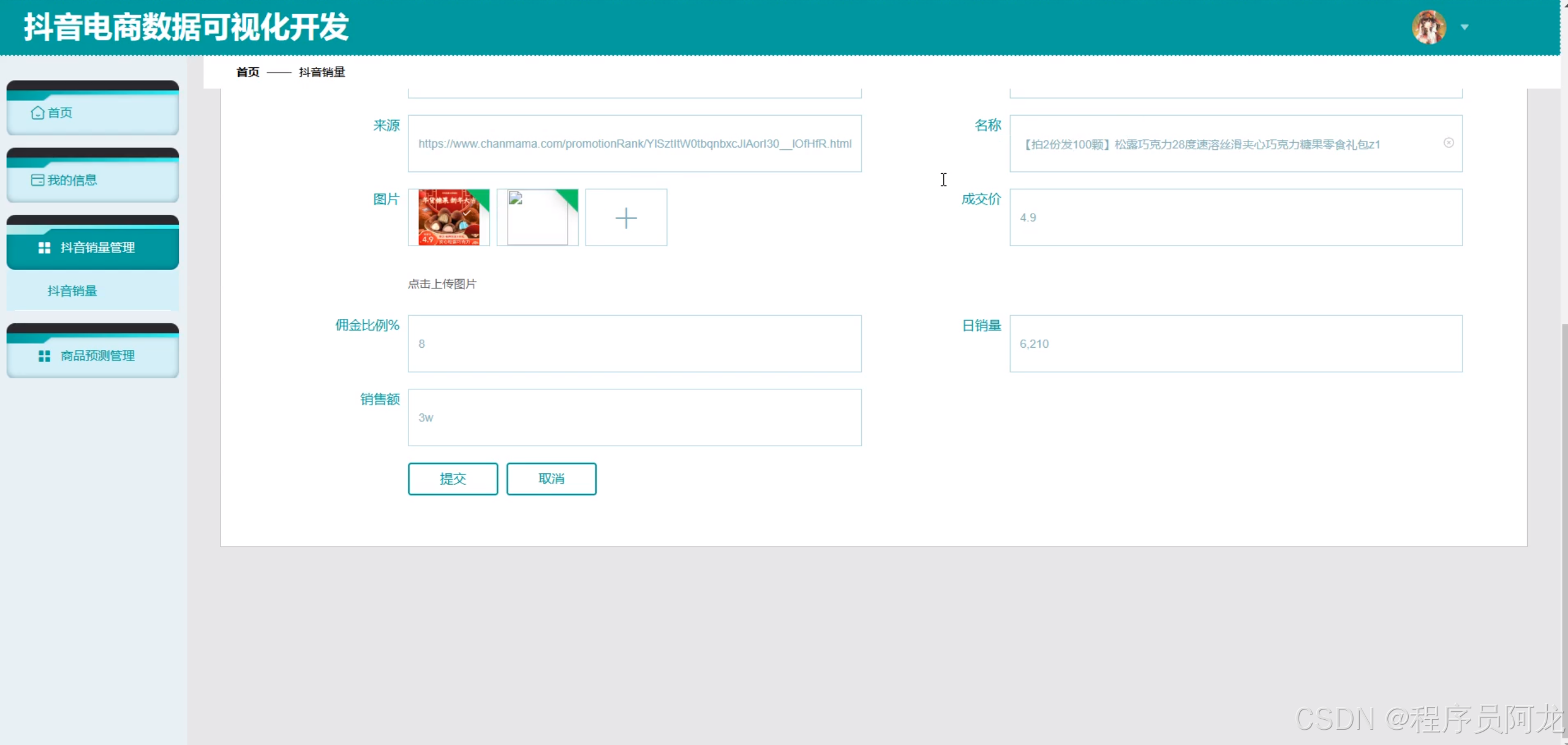
机器学习之随机森林分类算法:
随机森林分类算法通过构建大量互相独立的决策树来提升分类性能:首先在原始训练集中采用自助采样法(Bootstrap)随机抽取多个子集,对每个子集训练一棵决策树;在树的每个分裂节点,随机选取特征子集来决定最优分裂,以增加模型多样性并抑制过拟合;最终,所有决策树对新样本进行投票或概率平均,得票最多的类别即为随机森林的预测结果。由于集成了多棵弱学习器,随机森林不仅具有高准确率和鲁棒性,还能通过特征重要性度量揭示数据中关键变量,为实际应用中的特征筛选和模型解释提供了便利。

机器学习算法实现:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 1. 加载示例数据集(这里以 Iris 数据集为例)
iris = load_iris()
X, y = iris.data, iris.target
feature_names = iris.feature_names
class_names = iris.target_names
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# 3. 初始化随机森林分类器
# n_estimators:树的数量
# max_features:每个节点分裂时考虑的最大特征数
# random_state:随机种子,保证结果可复现
rf_clf = RandomForestClassifier(
n_estimators=100,
max_features='sqrt',
random_state=42,
n_jobs=-1
)
# 4. 训练模型
rf_clf.fit(X_train, y_train)
# 5. 预测
y_pred = rf_clf.predict(X_test)
y_prob = rf_clf.predict_proba(X_test) # 如果需要类别概率
# 6. 评估
acc = accuracy_score(y_test, y_pred)
print(f"Accuracy: {acc:.4f}\n")
print("Classification Report:")
print(classification_report(y_test, y_pred, target_names=class_names))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
# 7. 特征重要性
importances = rf_clf.feature_importances_
indices = np.argsort(importances)[::-1]
print("\nFeature importances:")
for idx in indices:
print(f"{feature_names[idx]:<20} : {importances[idx]:.4f}")




















 7540
7540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











